
コーポレートガバナンスとは、企業の舵取りを関係者間でいろいろと考えていこうよ、ということ。
そして、企業の舵取りというのは、普通は経営者に任せているので、この経営者という存在が的確な舵取りをしているのかを見定めたり、怠けていないか規律づけたりすることが関係者の役割になる。
コーポレートガバナンスとは、企業の舵取りを関係者間でいろいろと考えていこうよ、ということ。
そして、企業の舵取りというのは、普通は経営者に任せているので、この経営者という存在が的確な舵取りをしているのかを見定めたり、怠けていないか規律づけたりすることが関係者の役割になる。
の続きです。
今回はR言語でカイ2乗検定をしてみます。
まずは、クロス表を作成します。

こうして作成したm_tblはtibbleオブジェクトです。このうち、1列目はいらないので、削除します。

m_tbl[ , -1]で1列目を削除して、as.matrix関数でマトリックス型オブジェクトに変換しました。そして、rownames関数で行名を設定しました。
これで終わりではないです。prefの値は、cityとlargeの受給者数も入っていますから、それを引かないといけないです。

比率でも表示してみましょう。rowSums関数を使うと各行の合計が計算できます。

prefのm_pop比率は88%と低いことがわかります。
それでは、chisq.test関数でカイ2乗検定をしてみます。

p-value < 2.2e-16と0.05よりも小さいですから、地域によって母子家庭世帯の受給者数は違いがある、ということですね。
chi_m_tbl$stdresとして調整済残差を見てみましょう。

やはり、pref, この場合は政令指定都市と中核都市以外の地域、は母子家庭世帯の受給者数の比率が少ないことがわかります。
同じように父子家庭世帯についても調べましょう。

rowSums関数を利用して比率で表示しましょう。

prefの比率が8.8%とcity, largeと比べて倍ちかくあります。
カイ2乗検定をしてみましょう。

p-value < 2.2e-16 ですから有意です。
調整済残差を見ます。

やはり、prefで父子家庭世帯の受給者数の比率は高いです。
今回は以上です。
の続きです。
前回の分析で、母子家庭比率、父子家庭比率は地域のタイプ(都道府県、指定都市、中核都市)によって違いがありそうだとわかりました。
グラフにして確かめてみます。
まずは、地域タイプ別の箱ひげ図を作成してみました。


largeというのは政令指定都市です。cityは中核都市、prefは都道府県です。都道府県は母子家庭比率が低いように見えますね。
父子家庭比率も同じように見てます。


父子家庭比率は都道府県が比率が高いようです。
group_by関数とsummarise関数をつかって集計してみます。

母子家庭比率の平均値は政令指定都市(large)が92.6%で一番高く、
父子家庭比率の平均値は都道府県(pref)が6.12%と一番高いです。
でも、これは、各都道府県や政令指定都市、中核都市の比率の平均値ですから、正確な値ではありません。
正確な比率は、
都道府県の合計の母子家庭世帯の受給者数 / 都道府県の合計の総受給者数
で計算しないといけないです。
計算してみましょう。

母子家庭比率は、政令指定都市(large)が92.8%で一番高く、
父子家庭比率は、都道府県(pref)が5.65%で一番高いです。
念のため検算してみましょう。

あっていますね。
今回は以上です。
の続きです。
今回は、母子家庭の比率と父子家庭の比率に注目してみます。
母子家庭比率は、m_pop / t_pop で、
父子家庭比率は、f_pop / t_pop で計算できます。

母子家庭比率(m_ratio)のヒストグラムを見てみましょう。


母子家庭比率はほとんどの地域で90%以上ですが、ひとつだけとても低い地域があります。どこでしょうか?arrange関数で小さい順に並び替えます。

select関数でtype, name, m_ratioだけを表示しています。そして、head関数ではじめ6行だけを表示しています。
高知市が一番、母子家庭比率が低いのですね。
母子家庭比率が高い地域はどこでしょうか?

郡山市が一番母子家庭比率の高い地域です。
父子家庭比率についてもヒストグラムを描いてみます。


父子家庭比率はほとんどが10%以下ですね。
父子家庭比率の高い地域を見てみましょう。高知市、高知県かな?

あ、高知県はありましたが、高知市はありませんね。父子家庭比率が一番高いのは秋田県でした。
反対に父子家庭比率が低い地域はどこでしょうか?

郡山市、ありませんね。一番父子家庭比率が低い地域は岡崎市でした。富山市、川口市と続きます。
今回は以上です。
今回は、児童扶養手当受給者データを分析しようと思います。
データは、政府統計の総合窓口、www.e-stat.go.jp から取得しました。

9月4日の新着ファイルで、厚生労働省から福祉行政報告例というファイルがありましたのでこれをクリックします。
クリックして進んでいきます。
月次の統計です。クリックします。
4月をクリックします。
都道府県別統計表のほうをクリックします。
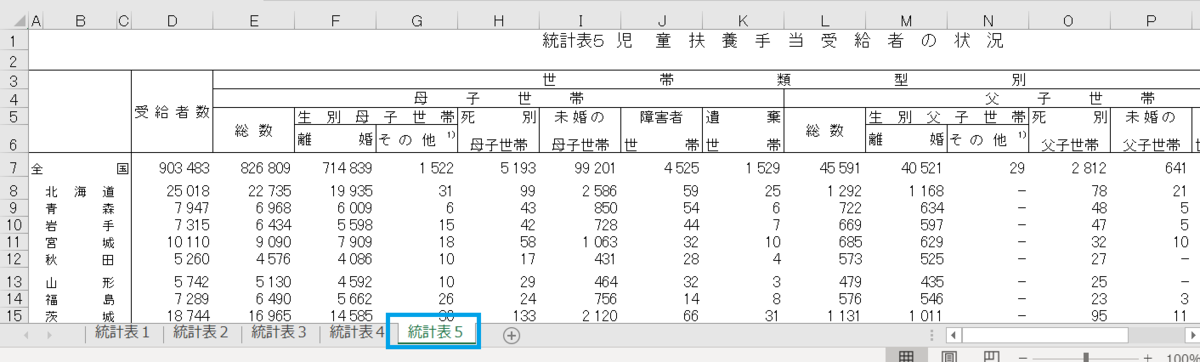
統計表5が児童扶養手当受給者データです。
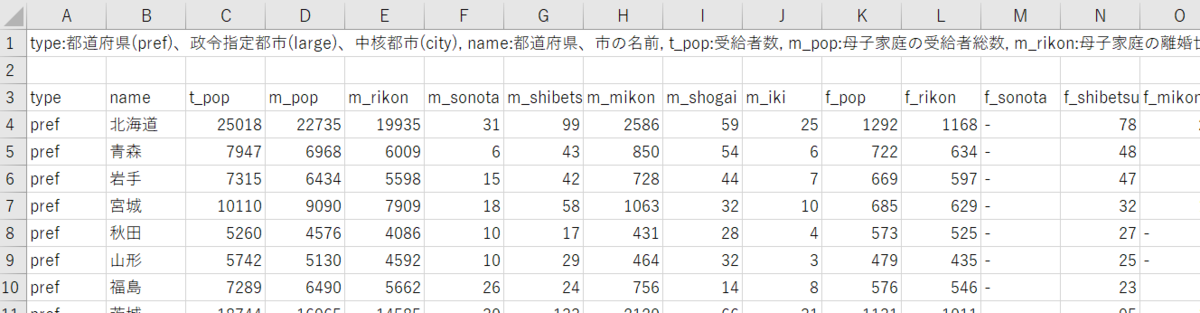
このファイルを上のようなCSVファイルにしました。これをR言語のread.csv関数で読み込みます。

上のCSVファイルは3行目からがデータなので、skip = 2 として2行を飛ばしています。
UTF-8のエンコードのファイルなので、encoding = "UTF-8"にしています。
str関数で確認してみます。

str関数でデータの型を見ると、m_sonota, m_iki, f_sonota, f_mikon, f_shogai, f_ikiのデータ型が文字列になっていますね。- があるからですね。- を0に変換して数値型に変えましょう。

function関数で - を 0 に変換する関数を作りました。
この関数を使います。
まず、tidyverseパッケージを読み込んでおきます。

それでは - を0に変換してみます。

このように、mutate関数内でzero_henkan関数を使います。
もういちど、str関数で確認してみます。
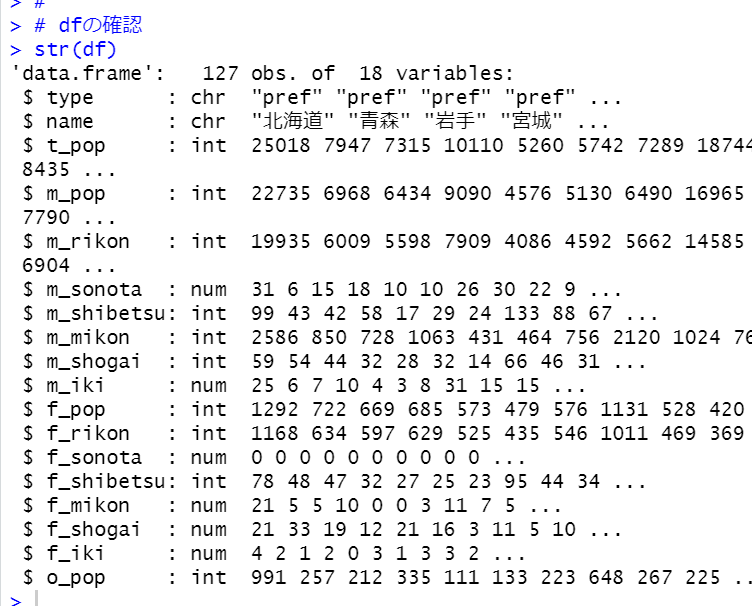
データ型がnumとなっていて数値型にに代わっています。
最後にそれぞれの変数名の説明を書いておきます。
type:都道府県(pref)、政令指定都市(large)、中核都市(city)
name:都道府県、市の名前
t_pop:受給者数
m_pop:母子家庭の受給者総数
m_rikon:母子家庭の離婚世帯の受給者数
m_sonota:母子家庭のその他世帯受給者数
m_shibetsu:母子家庭の死別世帯の受給者数
m_shogai:母子家庭の障碍者世帯の受給者数
m_iki:母子家庭の遺棄世帯の受給者数
f_pop:父子家庭の受給者総数
f_rikon:父子家庭の離婚世帯の受給者数
f_sonota:父子家庭のその他世帯の受給者数
f_shibetsu:父子家庭の死別世帯の受給者数
f_shogai:父子家庭の障碍者世帯の受給者数
f_iki:父子家庭の遺棄世帯の受給者数
o_pop:母子家庭、父子家庭以外の世帯の受給者総数
今回は以上です。
の続きです。
分析7ではマニュアル作業でデータフレームの構成を作り替えましたが、あれから少し調べてみると、gather関数というので簡単にできるらしいです。やってみます。

gather関数一つでできてしまううですね。
自分のためにgather関数の使い方をメモしておきます。
gather(key = X, value = Y, Z1, Z2, Z3,...)となっていて、key = X と value = Y が新しく作られる変数名で、Z1, Z2, Z3,..がもともとある変数名で、この変数名がkey = X に格納されて、Z1, Z2, Z3,...の変数の値がvalue = Y に格納される、ということですね。
そして、この反対がspread関数です。
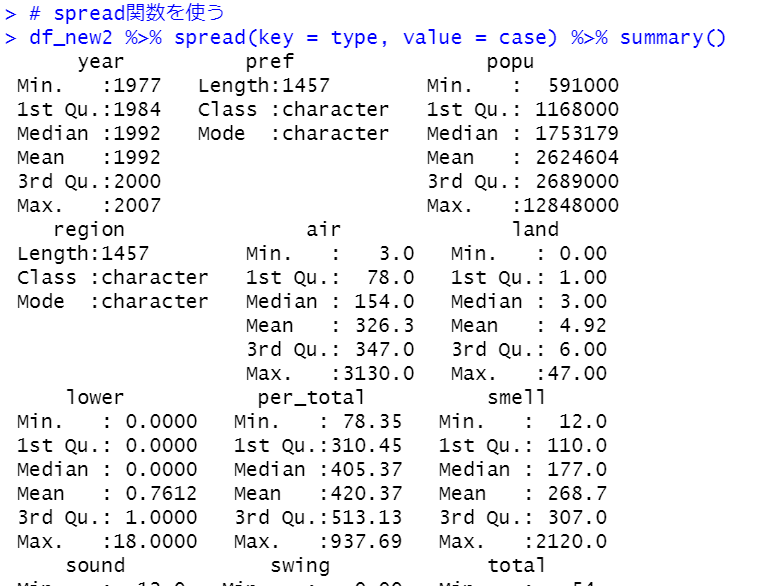
spread(key = X, value = Y)という使い方で、keyで指定したXの値を新しい変数として作成して、そのXの値として、valueで指定したYの値を入れる、ということですね。
spread(key = type, value = case)だとtypeのそれぞれの値(air, landなど)を変数名にして、その変数にcaseの値を入れていく、ということですね。
今回は以上です。
の続きです。
前回、データフレームの構成を作り替えました。
これで、何をしたかったかというと、

こういうグラフを作りたかったのです。
スクリプトは、

library(RColorBrewer)でカラーパレットのパッケージを読み込みます。
df_new %>% filter(type == "per_total") %>% でper_totalだけのデータフレームにしています。
mutate(pref = reorder(pref, case, FUN = mean)) %>% でprefをcaseの値の平均値の順番に並び替えています。
あとは、ggplot()以下でタイルグラフを作成しています。
今回も、
を参考にしました。
今回は以上です。
 (English Edition)")