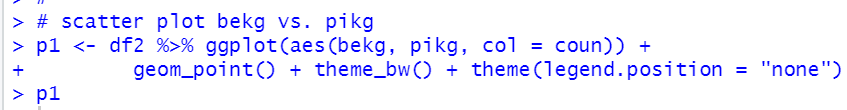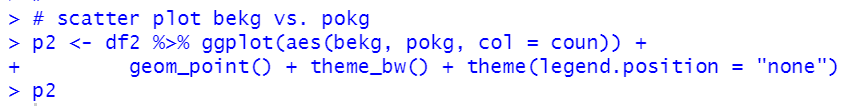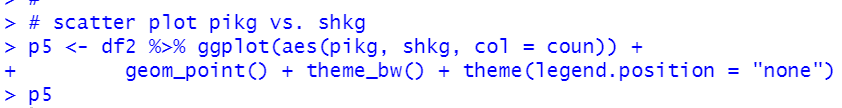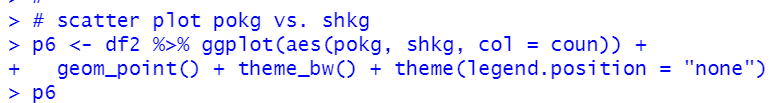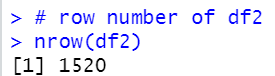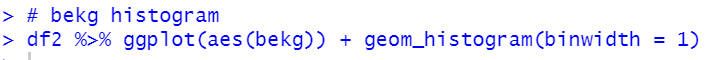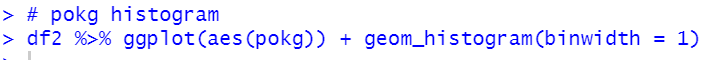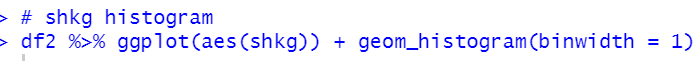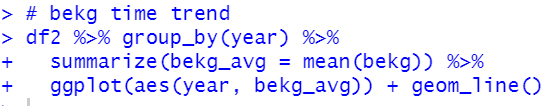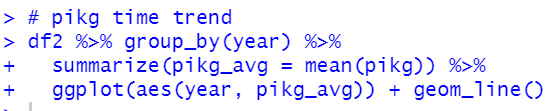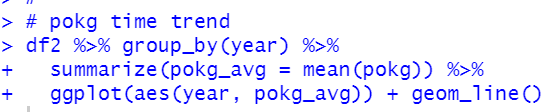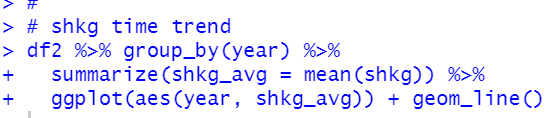Photo by corina ardeleanu on Unsplash
This post is following of above post.
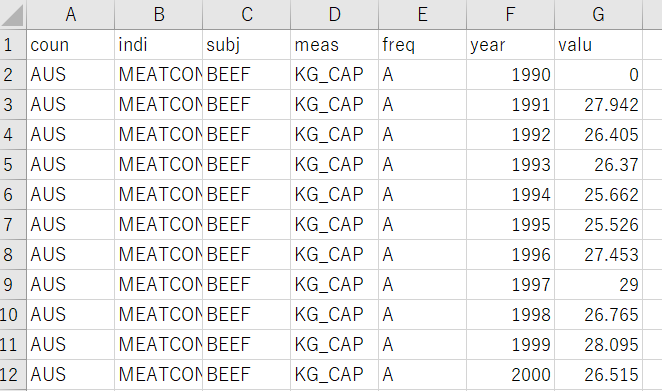
I have GDP data like below CSV file.
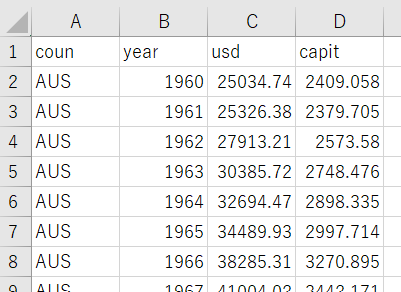
So, let's combine this GDP data and Meat Consumption data.

Next, I use inner_join() function to combine df2 dataframe and gdp dataframe.

Let's see the result.
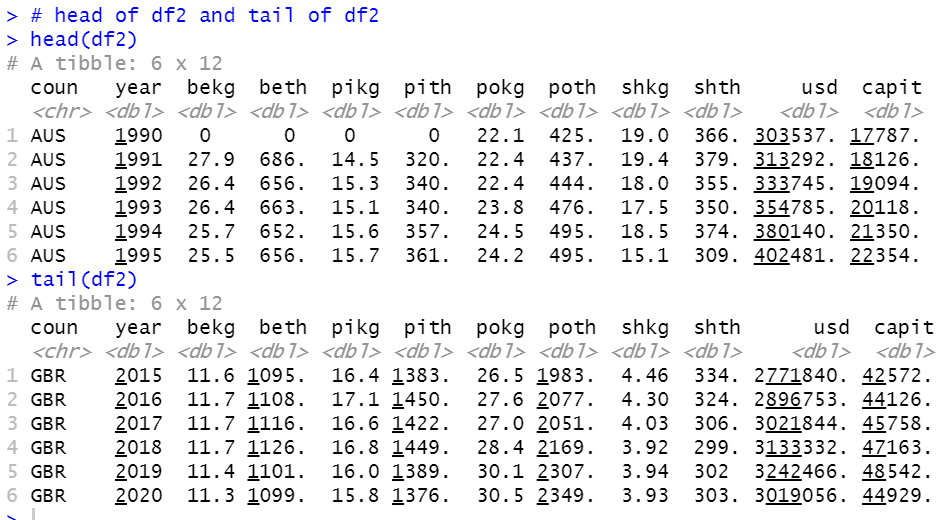
usd is gross GDP value, capit is per capita GDP.
summary if df2
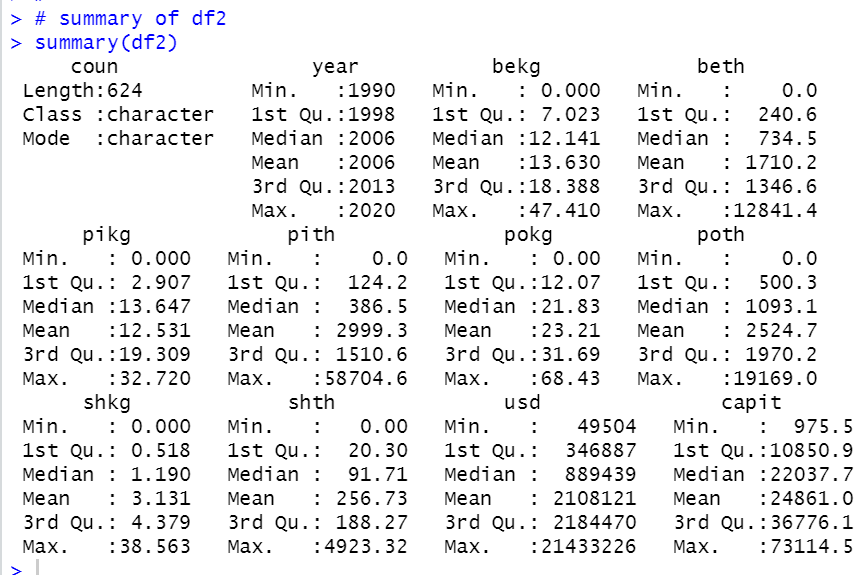
We see year range is changed. 1990 ~ 2020.
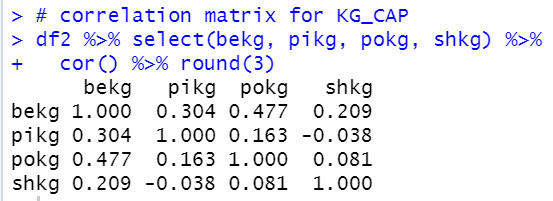
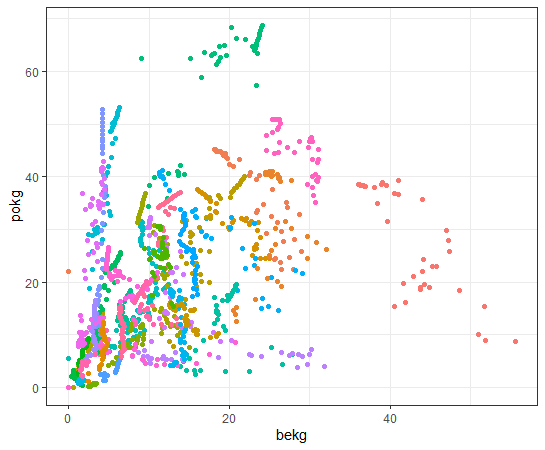
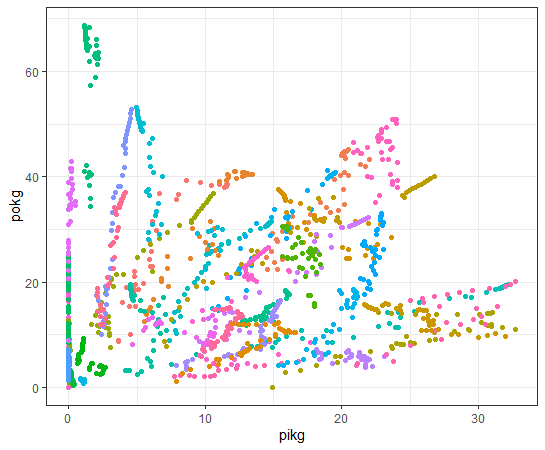
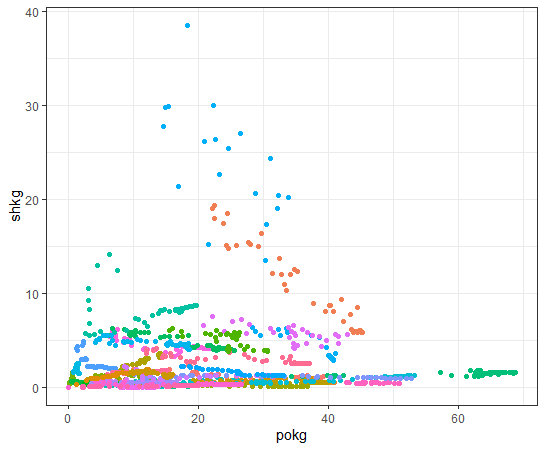
Now, let's see capit and 4 KG_CAP data.

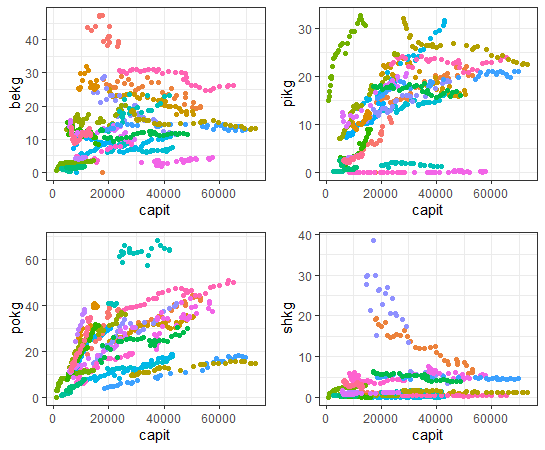
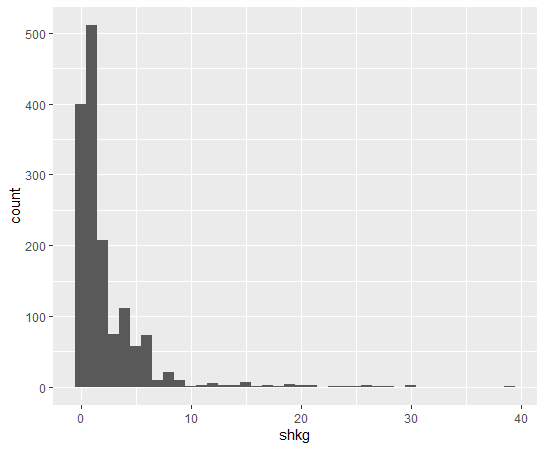
I see shkg is not so much correlated with capit.
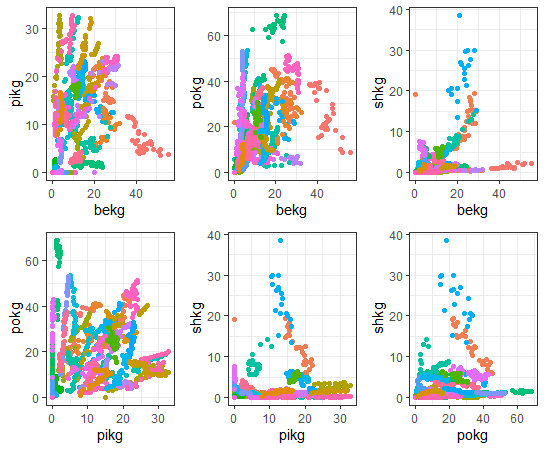
Let's see correlation with capit and 4 KG_CAPs by country.

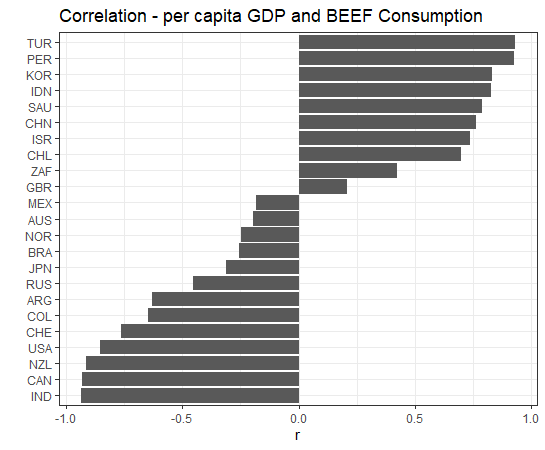
We see some countries have negative correlations and some contries have positive correlations.
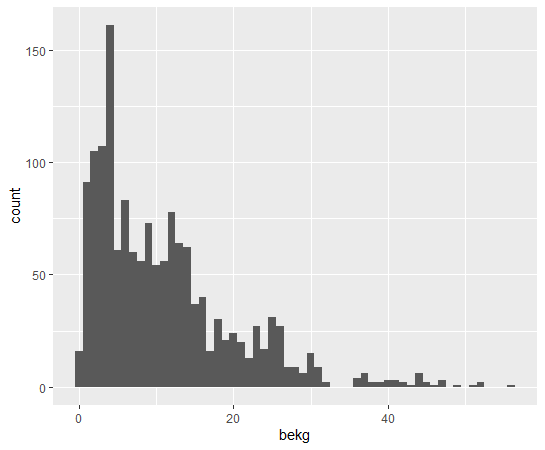
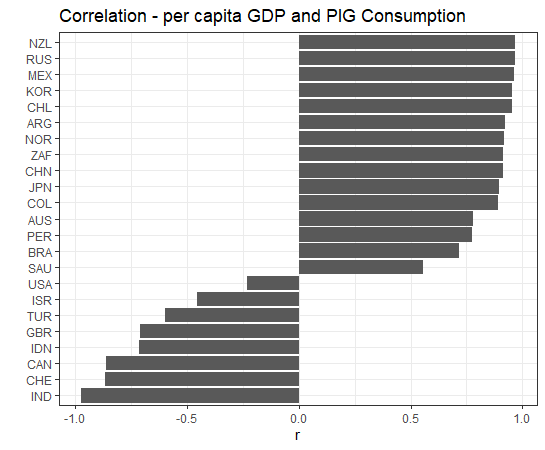
How about pikg: PIG KG_CAP?

How about POULTRY?

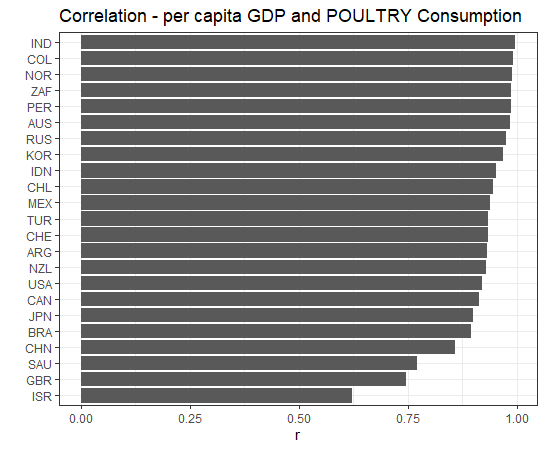
All countires have positive correlations with POULTRY.
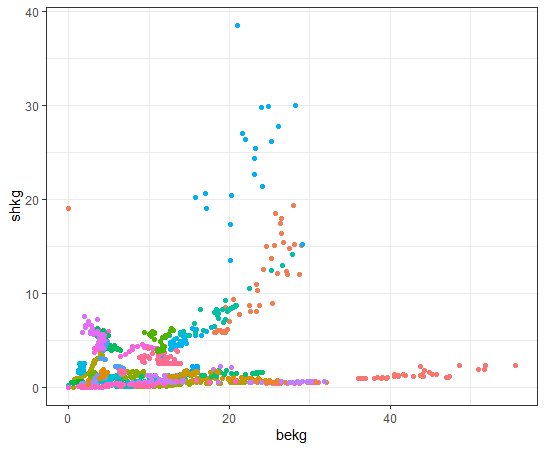
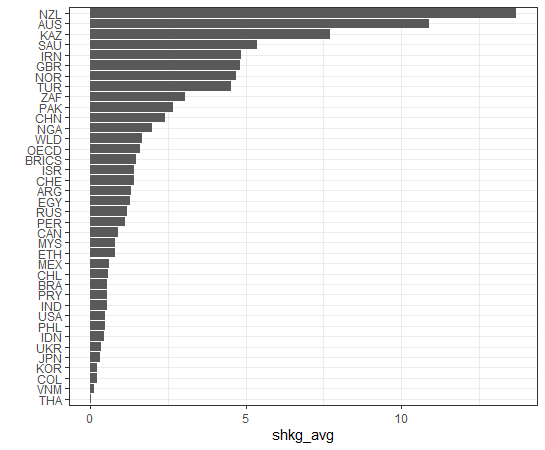
Last, how about shkg?

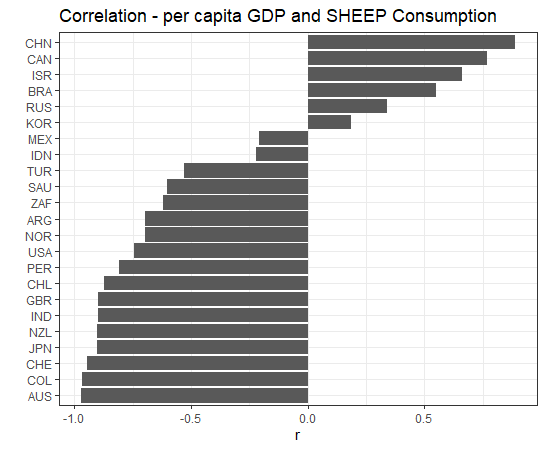
We see some countries have negative correlation while some countries have positive correlations.
per capita POULTRY Consumption and per capita GDP are positively correlated in all countries.
That's it. Thank you!
Next post is
To read the 1st post,