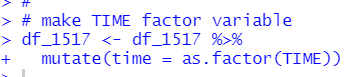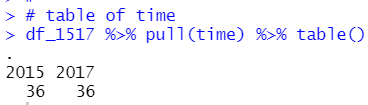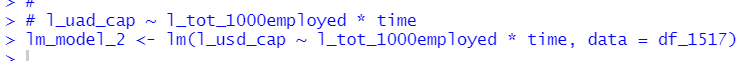UnsplashのWesley Tingeyが撮影した写真
今回は、J. Leagueのデータを分析してみます。勝ち点と得点、失点の関係を調べます。
まず、データをJ. Leagueの公式サイトから取得しました。
J. League Data Site (j-league.or.jp)
Webスクレイピングできればいいのですが、そこまでの技術が無いのでコピペしてExcelに貼り付けました。

こんな感じでまとめました。
これを、R言語で分析します。
まず、必要なライブラリを読み込みます。

tidyverseパッケージはRを使うときはとりあえず読み込んでおいたほうがいいですよね。modendiveパッケージは、現在、読んでいるデータ分析の本、Statistical Inference via Data Science (moderndive.com)のパッケージです。今回はこの本の内容を参考にして分析します。readxlパッケージはExcelのデータを読み込むときに使います。
では、read_xlsx()関数でデータ読み込みます。

glimpse()関数でデータが読み込まれたかどうか見てみます。

無事に読み込みできたようです。日本語のチーム名が何故か文字化けしてしまうんですよね。。今回はチーム名は分析には使わないので大丈夫です。
変数を簡単に説明します。year: 西暦、rank: 順位、name: 英語のチーム名、team: 日本語のチーム名、point: 勝点、game: 試合数、win: 勝数、lose: 敗数、tile: 引分数、goal_get: 得点、goal_give: 失点、get_give: 得失点差、です。
今回の分析では、pointが被説明変数で、goal_getとgoal_giveが説明変数です。
point, goal_get, goal_giveの基本データをみてみます。summary()関数を使います。

pointの平均値は46.65, goal_getとgoal_giveの平均値は46.16と同じです。
最小値は、pointは14, goal_getは16, goal_giveは24。
最大値は、pointは92, goal_getは88, goal_giveは88となっています。
3つの値の範囲はだいたい同じですね。
この3つの変数の相関係数を見てみます。cor()関数を使います。

pointとgoal_getは0.77の相関係数なので、比較的強い正の相関です。
pointとgoal_giveは-0.70の相関なので、比較的強い負の相関です。
goal_getとgoal_giveは-0.25の相関なので、比較的弱い負の相関です。
この結果は直感と矛盾しませんね、得点が多ければ勝点は多く、失点が多ければ勝点は少なく、得点が多ければ失点は少ない、勝点が多ければ得点は多く、勝点が少なければ失点は多く、失点が少なければ得点が多い、ということです。
plot()関数で散布図を描いてみます。


pointとgoal_get, pointとgoal_giveは相関が強く、goal_getとgoal_giveは相関が弱いことがわかります。
それでは、lm()関数で回帰分析をしてみます。

続いて、moderndiveパッケージのget_regression_table()関数で結果を表示します。

goal_getの係数は0.688でgoal_giveの係数は-0.656です。
つまり、goal_giveが変わらないとすると、1点得点すると勝点が0.688増えるということ、goal_getが変わらないとすると、1点失点すると勝点が0.656減るということです。
ということは、1得点(=勝点0.688) > 1失点(=勝点0.656)ということなので、「攻撃は最大の防御なり」ですね。
以上の結果はJ. League全部のチームの結果です。もしかしたら、上位チームと下位チームでは違うかもしれません。勝数のほうが敗数よりも多いチームは、1, そうでないときは0というダミー変数を作って、これを回帰モデルに加えてみましょう。
まずは、ダミー変数を作成します。

こうして作成した、winnerを加えた回帰モデルを作成します。

結果をget_regression_table()関数でみてみます。

すこしややこしいですが winner = 1 のときとwinner = 0 のときでわけて考えます。
winner = 1, つまり勝ち越しチームは
point = 40.1 + 9.23 + (0.594 + 0.022) * goal_get - (0.507 + 0.13) * goal_give
= 49.33 + 0.616 * goal_get - 0.520 * goal_give となります。
winner = 0, つまり負け越しチームは、
point = 40.1 + 0.594 * goal_get - 0.507 + goal_give となります。
どちらの場合でも、goal_getの係数の絶対値ほうがgoal_giveの係数の絶対値よりも大きいですから、1得点の価値のほうが1失点の価値よりも大きいことがわかりました。
今度は、J. Leagueの開催された年を前半、後半に区切ったダミー変数を作成して、分析してみましょう。
まずは、前半の年なら1のダミー変数を作成します。

回帰モデルを作成します。

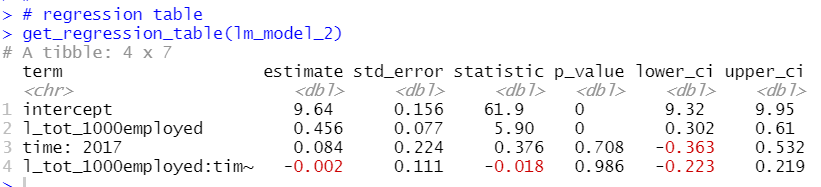
結果をget_regression_table()関数で表示します。

old_year = 1 のときと、old_year = 0 のときでわけて推計式を考えます。
old_year = 1 のとき、
point = 46.6 - 4.03 + (0.707 - 0.029) * goal_get - (0.687 - 0.079) * goal_give
= 43.57 + 0.736 * goal_get - 0.608 * goal_give
old_year = 0 のとき、
point = 46.6 + 0.707 * goal_get - 0.687 * goal_give
です。どちらのケースでもgoal_getの係数の絶対値のほうがgola_giveの係数の絶対値よりも大きいですね。1得点の価値のほうが1失点の価値よりも大きいです。
以上の分析結果から、J. Leagueでは「攻撃は最大の防御なり」ということが言えるようです。









")





























")