の続きです。
データの数が多いので、東京都だけのデータフレームを作ってこれから分析してみます。

prefは必要ないので削除しましょう。

2010年から2017年の8年間のデータです。一番少ない月で3万0833冊、一番多い月で6万9727冊の発行です。
年ごとのデータをグラフであらわしてみます。散布図と箱ひげ図を組み合わせます。


2013年、2014年が発行が少ないですね。
月ごとでも同じようにやってみます。


東京都単独でも8月や7月の発行が多く、11月や12月の発行が少ないことがわかります。
それでは、東京都の8月の発行数と11月の発行数はたまたま違うのか、有意に違うのか調べてみます。
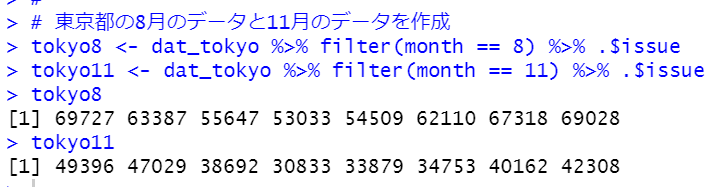
このように、8月のデータのベクトルと11月のデータのベクトルを作成しました。
まず、var.test関数で分散が同じといえるのか、有意に違うのかを確認します。

p-valueが0.9221なので、8月と11月のデータで分散の大きさに有意な違いがあるとは言えません。
分散に違いはありませんので、t.test関数でt検定をして8月と11月のデータの平均値に違いがあると言えるかどうか調べます。

p-value = 9.58e-06と0.05よりも小さいので、8月と11月の平均値は有意に違います。
今回は以上です。
次回は、
です。
第1回目は
です。