今回は国民栄養・健康調査のデータを分析してみます。
政府統計の総合窓口(www.e-stat.go.jp)からデータを取得します。


たくさんデータベースがありましたが、今回は栄養素等摂取量 - エネルギー・栄養素等、地域ブロック別、平均値、標準偏差、中央値 - 総数、1歳以上
というデータを取得します。
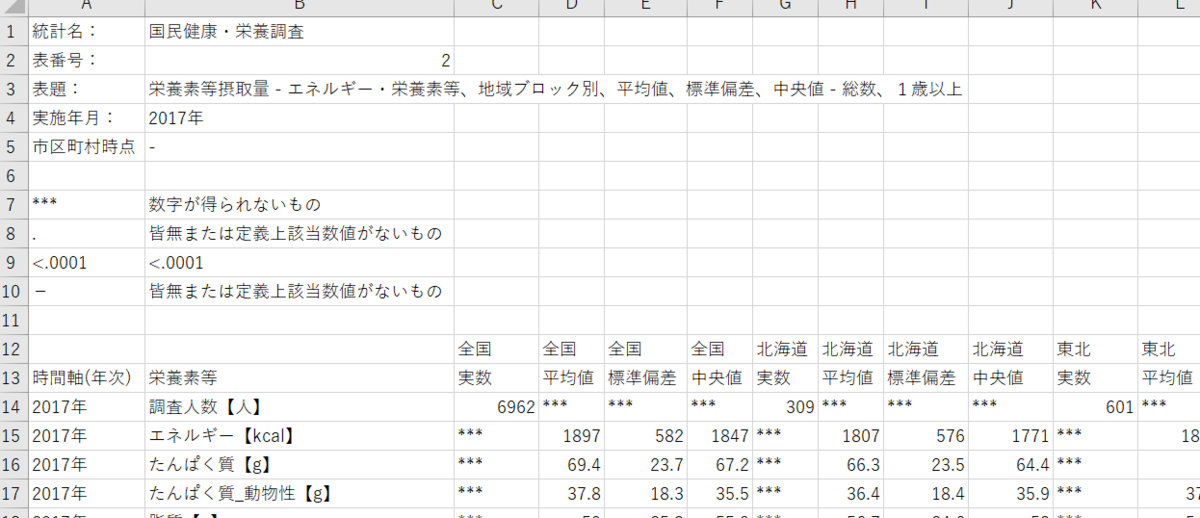
このようなExcelファイルでした。これをR言語で読み込みます。
まず、tidyverseパッケージの読み込みです。
read_csv関数で読み込みます。

locale = のところでファイルのエンコードはUTF-8だと教えています。
skip = 11のところで12行目から読み込んでねと教えています。
na = のところで***や.や-はNAですよと教えています。
col_names = のところでコラム名は無いですよと教えています。
str関数でデータが読み込まれたかどうか見てみます。

問題なく読み込まれています。
このraw_datを分析しやすいように整理整頓しないといけないです。
どうしましょうか?
とりあえず、1行目と2行目をpaste関数で結合してみましょう。

raw_data[1, ]のままではtibbleのオブジェクトなのでas.matrix関数でマトリックスのオブジェクトにして、さらにas.vector関数でベクトルのオブジェクトにしてからpaste関数でくっつけました。1番目の時間軸(年次)と2番目の栄養素等を少し変えます。

このcolumn_kouhoをコラム名にします。

str関数で確認します。

コラム名がかわりました。1行目と2行目を削除します。

str関数で確認してみます。

これをgather関数で全国 実数や全国 平均値をkeyにしてデータフレームの形を横長から縦長に変えます。

datを表示してみます。

だいぶいいところまで来ました。
データタイプの全国 実数となっているところを、全国というコラムと実数というコラムに分割します。separate関数です。

うまくできたかどうか見てみます。

うまくできました。
year, region, typeをファクター型に、valueを数値型にします。

summary関数でみてみます。
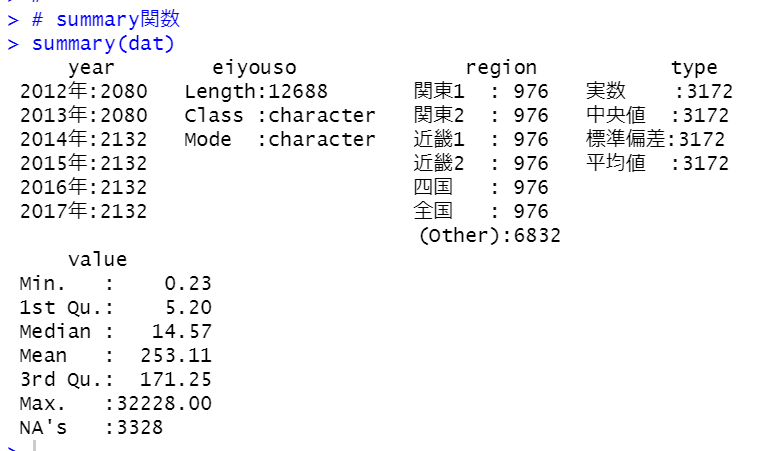
valueにNAがあります。これらは削除してしまいます。

もういちどsummary関数で見てみます。
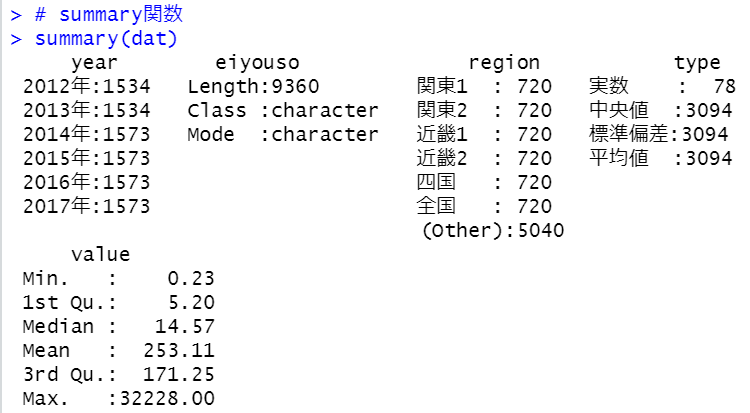
これでデータフレームが整理整頓できました。
今回は以上です。
次回は
です。