の続きです。
今回は、R言語のmutate関数を使って、mitsudo: 人口密度、per_capita17: 1人当りの県内総生産額(平成17年基準)、per_capita23: 1人当たりの県内総生産額(平成23年基準)、per_setai: 1世帯当たりの人数を作ります。

summary関数でデータフレーム: df1 の概要を見てみます。
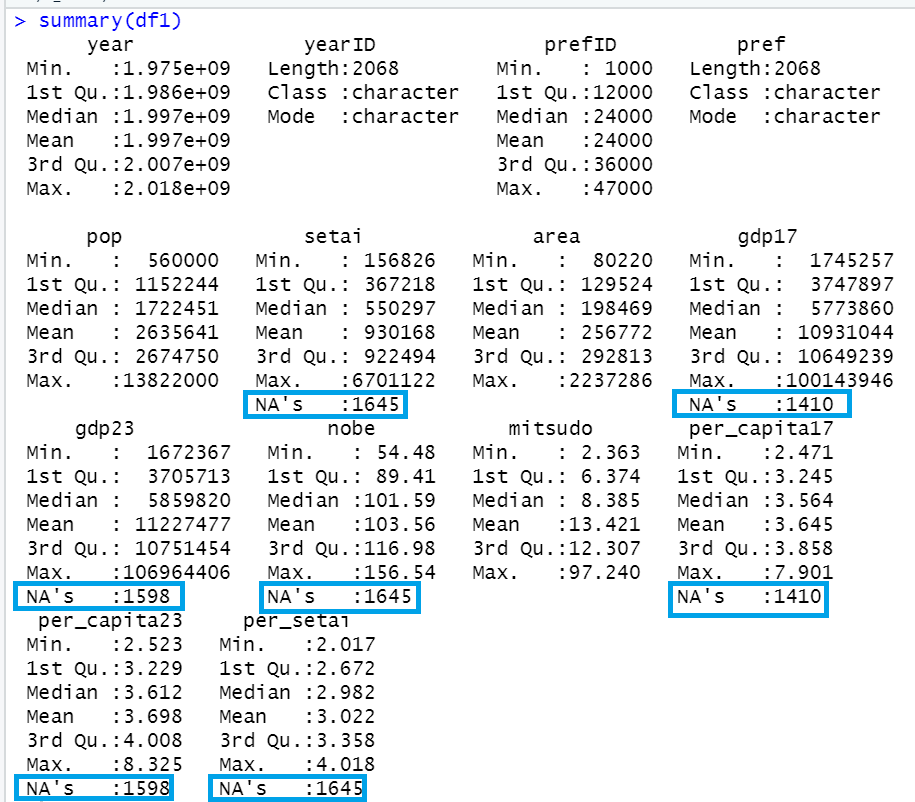
yearID, year, prefID, pref, pop, area, mitsudoはNAがありませんが、その他はNAがありますね。それと、yearとprefIDは数字のコードですが、桁数を整えましょう。

yearの最小値が1975で最大値が2018ですから、調査年度は1975年度から2018年度まであることがわかります。
今回の分析では、nobe: 都道府県別の1住宅当たりの延べ面積(m2) が分析対象ですから、nobeを中心にした分析用のデータフレームを作ります。
まず、NAの無い変数とnobeのデータフレームを作り、nobeがNAの調査年度を削除します。
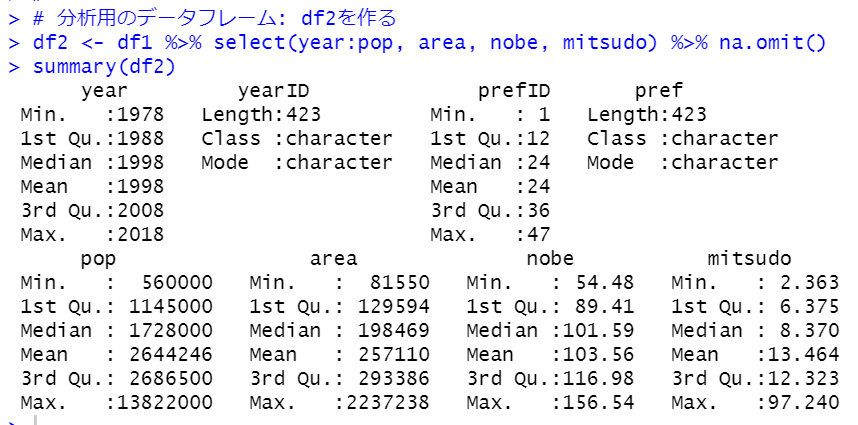
yearは1978年から2018年まであります。具体的にどの年があるのかtable関数でみてみます。

1978年から1983年、1988年と5年ごとにあるのですね。
次は、per_capita17がどの年にデータがあるかを見てみます。
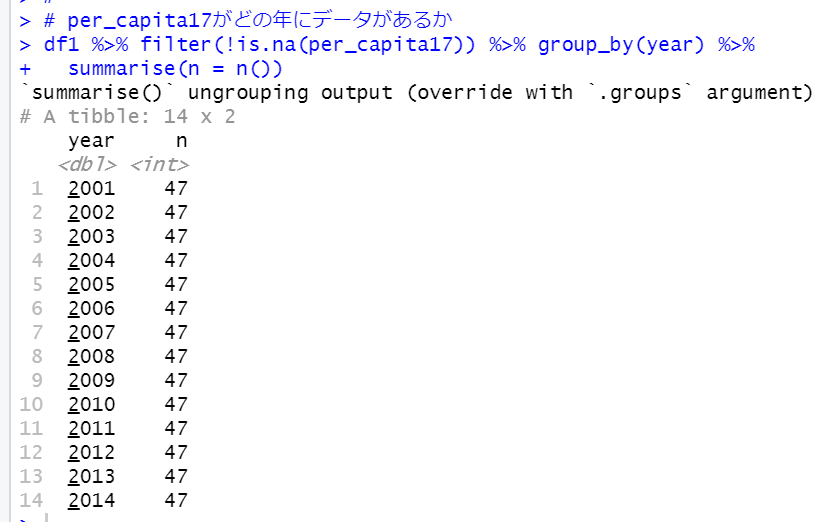
per_capita17がある年は2001年から2014年です。
per_capita23はどうでしょうか?

per_capita23は2006年から2015年です。2015年だけper_capita17が無い年です。
2015年はnobeも無いですから、per_capita17を使うのがいですね。
per_setaiはどうでしょうか

per_setaiは1975年から5年ごとに2015年度まであります。nobeが1978年からなので2年ずれています。仕方がありませんね。per_setaiは2年ずらした値を使いましょう。
以上の分析でわかったことをもとにして、次のようなデータフレームを作ります。
必要な項目は、year: 調査年、pref: 都道府県名, nobe: 1住宅当たりの延べ面積(m2)、
mitsudo: 1ha当たり人口、per_capita17: 1人当たり県内総生産額(平成17年基準)、per_setai: 1世帯当たり人数、です。
per_setai以外は調査年がそろっているので、いったん全てを抜き出してから、na.omit関数でNA行を削除します。これをdf3 としましょう。
そして、df4としてyear, pref, per_setaiのデータフレームを作り、year - 2 で調査年度を揃えます。そして、inner_join関数でdf3とdf4を結合させて、df5としましょう。
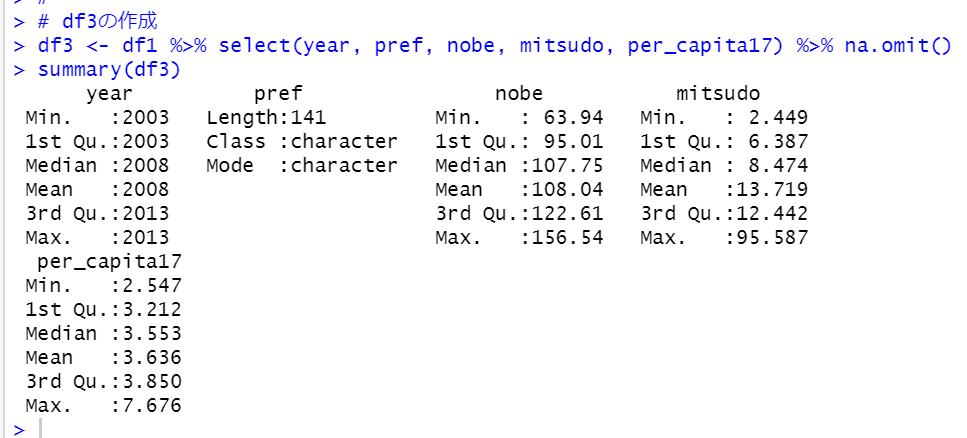
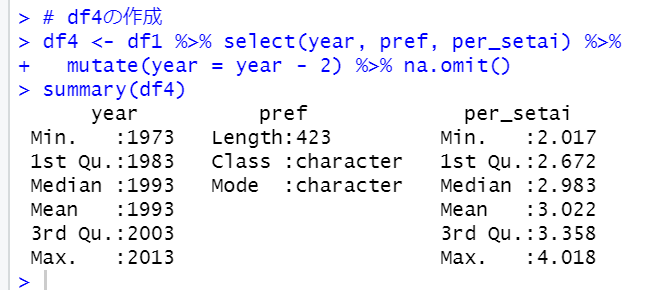
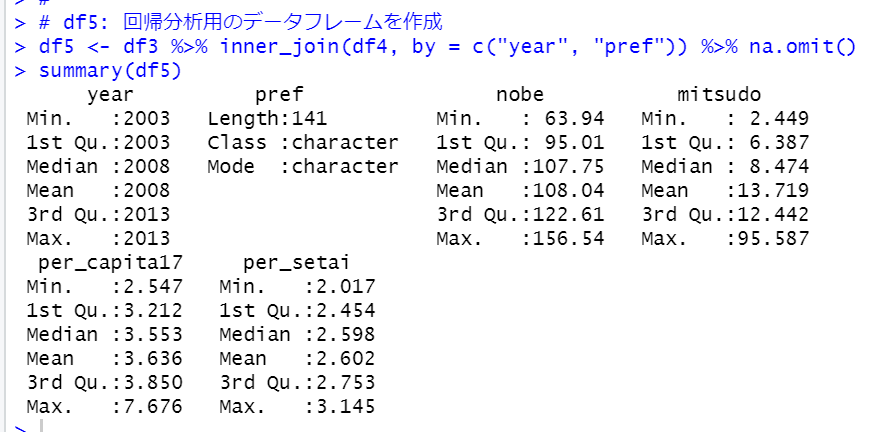
これで分析用のデータフレームを作りが完了です。yearは2003年、2008年、2013年と3つの調査年度(per_setaiは実際は2005年、2010年、2015年)があるデータフレームです。
今回は以上です。
次回は、
です。
はじめから読むには、
です。