
Photo by Ana Markovych on Unsplash
今回は都道府県別の通院者率のデータを分析してみようと思います。
データは、政府統計の総合窓口(e-stat)から取得しました。www.e-stat.go.jp
まず、47都道府県を選択しました。

続いて、65歳以上人口割合、就業者率、社会体育施設数、通院者率の4項目をデータとして選択しました。
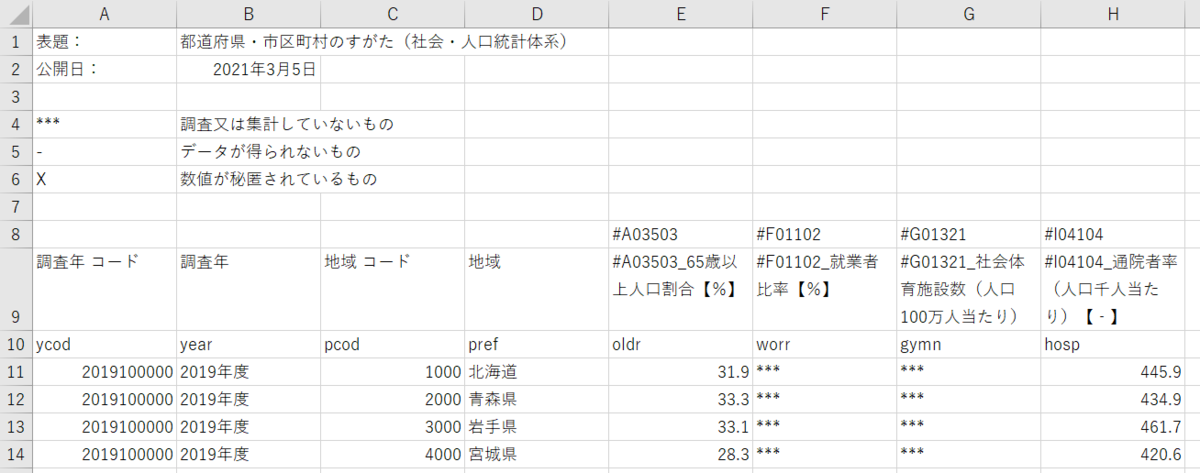
ダウンロードしたCSVファイルはこのようなものです。10行目に変数名を作って挿入しています。
このCSVファイルのデータをR言語に読み込みます。
まず。tidyverseパッケージの読み込みをしておきます。

read_csv関数で読み込みます。

head関数でどんな感じで読み込まれたか見てみましょう。
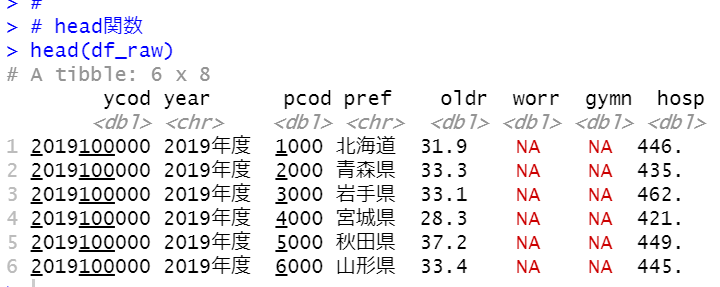
あ、今回は文字化けせずに上手く読み込んでいますね。
変数名を説明します。
ycod: year code - 調査年のコード
year: year - 調査年
pcod: prefecture code - 都道府県コード
pref: prefecture - 都道府県名
oldr: old ratio - 65歳以上の人の人口割合(%)
worr: work ratio - 就業者の人口割合(%)
gymn: gym number - 人口100万人当たりの社会体育施設数(数)
hosp: hospital - 人口1000人当たりの通院者率(人)
です。
ycodを100000を引いて1000000で割って4桁の西暦の数値に直しましょう。
yearとprefを文字列型からファクター型に変更しましょう。

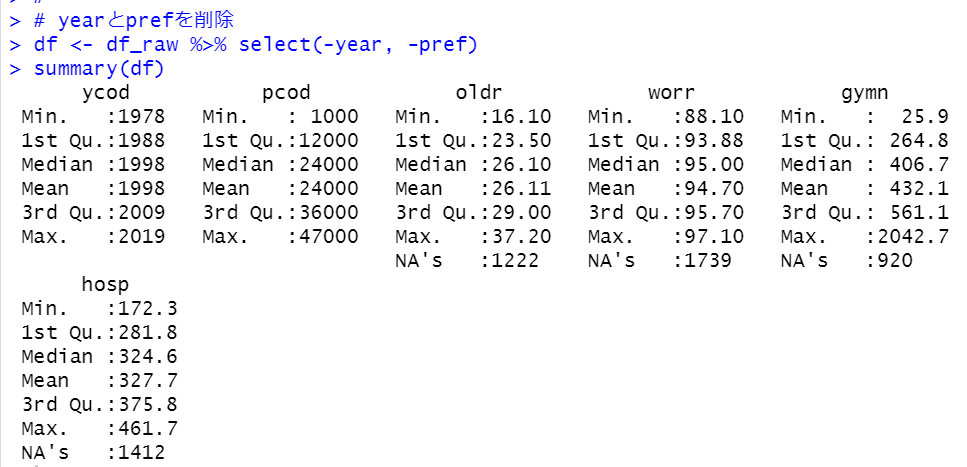
summary関数でdf_rawを見てみます。

あらら。。。
yearとprefが文字化けしてしまいました。。
仕方ないですね。yearとprefは削除してしまいます。
pcodが1000は北海道で、47000は沖縄県なのですが、このままではわかりにくいので、あらかじめ用意してある、
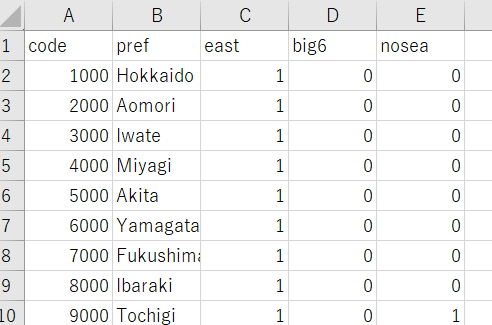
このCSVファイルを読み込んで、このデータと結合します。
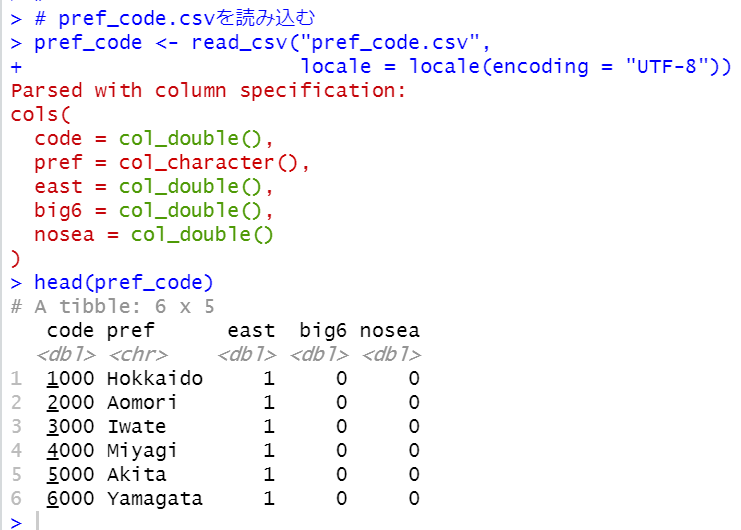
inner_join関数で結合します。dfのpcodとpref_codeのcodeが同じデータです。

うまく結合できました。pcodはもう必要ないので削除して、変数の並び順を少し直します。
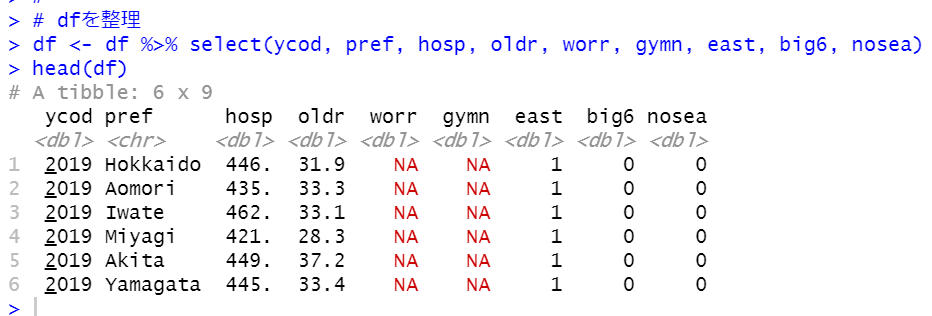
できました。新しく追加された変数を説明します。
east: 東日本なら1、西日本なら0のダミー変数
big6: 東京都、千葉県、神奈川県、埼玉県、愛知県、大阪府なら1、その他は0のダミー変数
nose: 海が無い県は1、ある県は0のダミー変数
今回は以上です。
次回は
です。