
Photo by Mylon Ollila on Unsplash
This post is following of the above post.
In this post, I will do clustering.
First, I use hierarchial clustering.
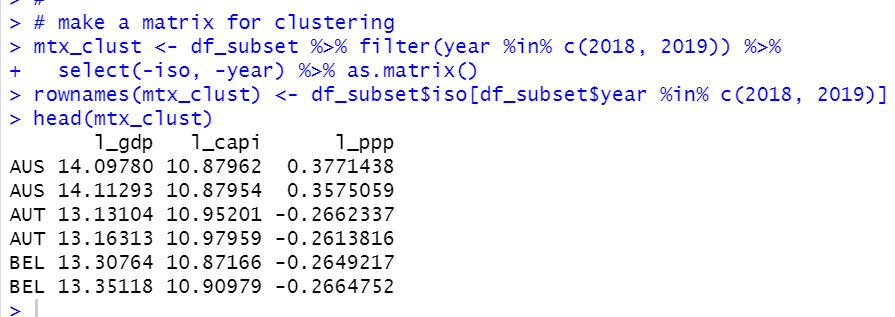
I make a matrix for clustering. I use 2018 and 2019 data.
Then, I use dist() function to calculate distance between each data.
Then, I use hclust() dunction to do hierarchial clustering.
Then, I use plot() function to make a dendrogram plot.

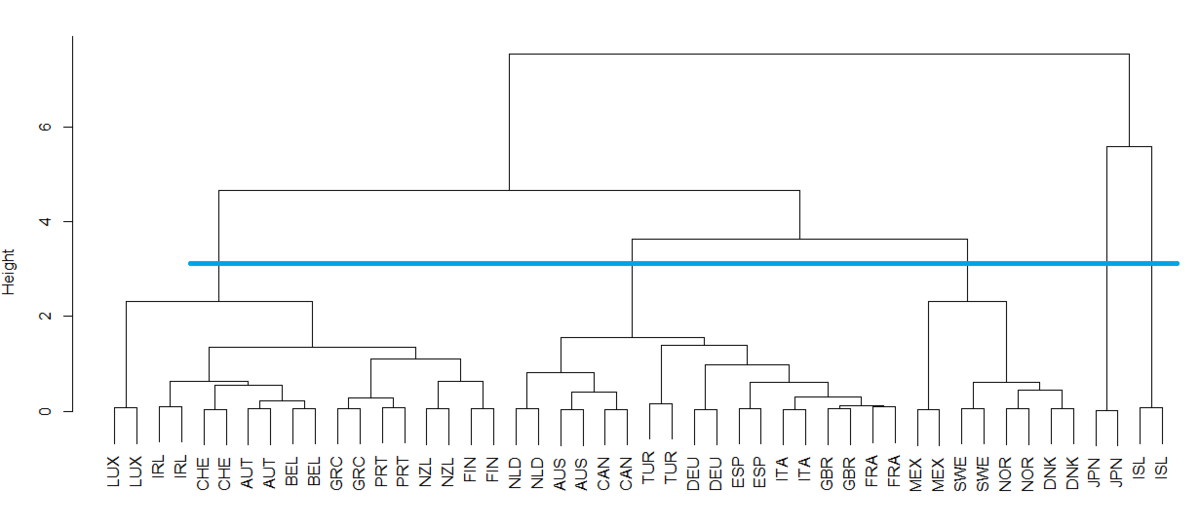
I see there are 5 groups,
Hierarchial Group 1 - LUX, IRL, CHE, AUT, BEL, GRC, PRT, NZL, FIN.
Hierarchial Group 2 - NLD, AUS, CAN, TUR, DEU, ESP, ITA, GBR, FRA.
Hierarchial Group 3 - MEX, SWE, NOR, DNK.
Hierarchial Group 4 - JPN.
Hierarchial Group 5 - ISL.
I use cutree() function to divide into 5 groups.

Now, let's do another clustering method, k-means clustering.
I use kmeans() function.
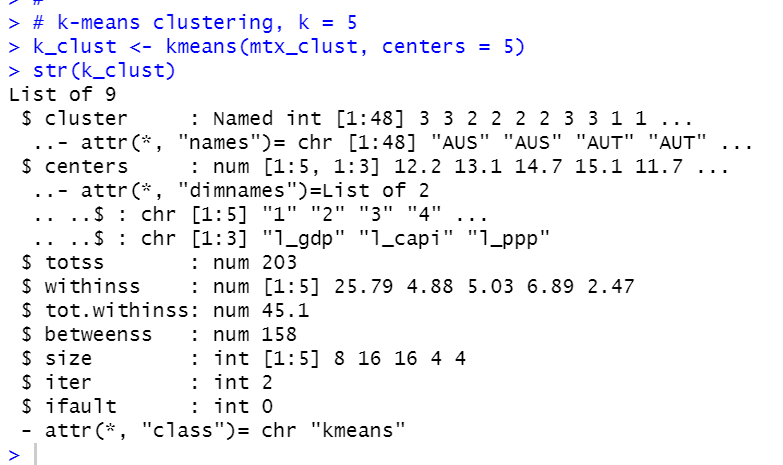
Let's see the result.

Kmeans Group 1 - DNK, ISL, NOR, SWE.
Kmeans Group 2 - AUT, BEL, FIN, GRC, IRL, NLD, PRT, CHE.
Kmeans Group 3 - AUS, CAN, FRA, DEU, ITA, ESP, TUR, GBR.
Kmeans Group 4 - JPN, MEX.
Kmeans Group 5 - LUX.
I see Hierarchial Group 3 and Kmeans Group 1 are similar, Hierarchial Group 2 and Kmeans Group 3 are similar, Hierarchial Group 1 and Kmeans Group 2 are similar.
That's it. Thank you!
The next post is
To read from the 1st post,