
Photo by Peter Pryharski on Unsplash
RのHistDataパッケージのArmadaデータセットはスペインの無敵艦隊のデータです。
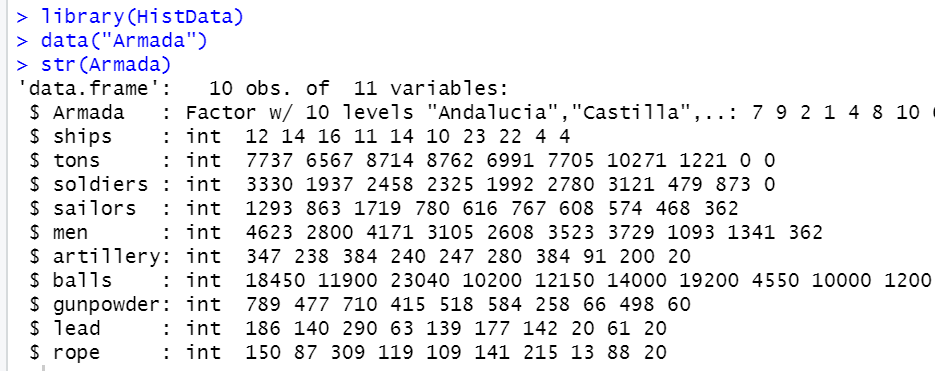
str()関数でデータ構造を見ると、10行 x 11列のデータフレームです。
それぞれの変数が何かというと、
Armada: designation of the fleetとあります。艦隊の行先でしょうか?
ships: 船の数
tons: total tonsとあります。艦隊のトン数ですかね。。
soldiers: 兵士の数
sailors: 船員の数
men: 兵士の数と船員の数の合計
artillery: 大砲の数
balls: 玉の数です。砲弾の数ですかね?
gunpowder: 火薬の数
lead: リードの数、リードってなんでしょうかね?海軍というか船関係のものだと思いますが、わからないです。
roap: ロープの数、ロープは紐のロープでしょうね。。
ヘルプページにあるコードを動かしてみます。
まずは、単純に全データの表示です。
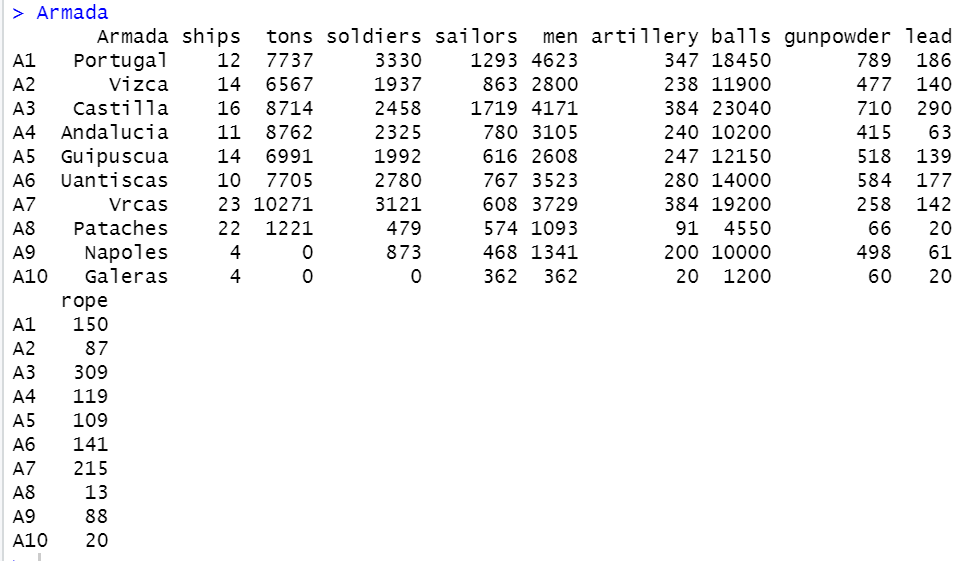
ArmadaはPortugalやNapolesなど地名になっているので艦隊の行先なのですかね?
その他の変数はすべて数値データです。
続いてのヘルプのコードを実行します。
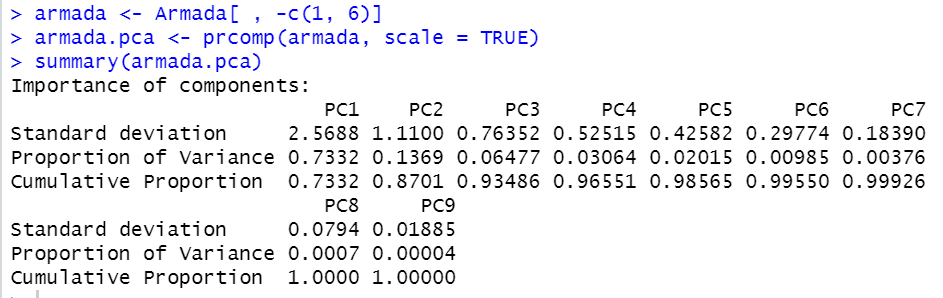
armada <- Armada[ , -c(1, 6)] で1番目の変数、Armadaと6番目の変数、menを削除して新しいデータフレーム、armadaを作っています。men = soldiers + sailors なのでいらないということですね。次に、prcomp()関数でPCA分析ですね。Principal Component Analysys, 日本語だと主成分分析です。summary()関数で結果を表示しています。元のデータフレームは9つの変数がありますが、それをPC1, PC2 という合成変数にすると、この2つだけで87%ほど全部のデータのバラツキを説明できる、ということですね。
さらにヘルプのコードを実行します。
![]()
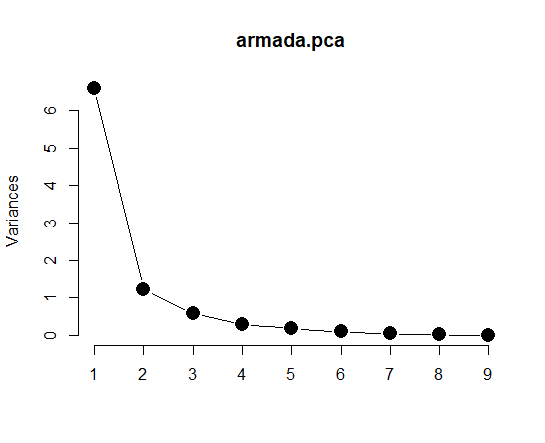
このコードは、PCAのサマリーの表の proportion of variance をグラフにしたものですね。PC1だけで全体の変動の7割以上を表現できるということですね。
続いてのヘルプのコードを実行します。
![]()
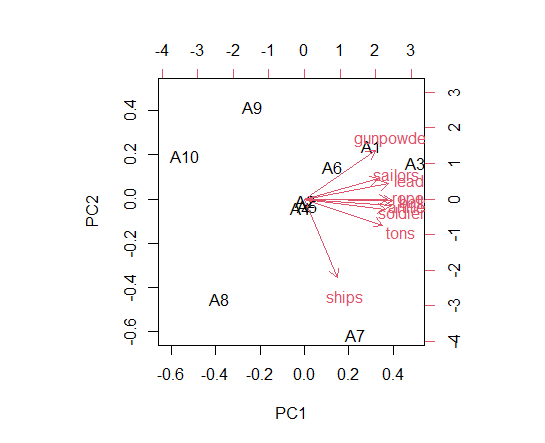
biplot()関数で、PC1とPC2のグラフにしています。
以上でヘルプのコードは終了です。
下に記載します。
library(HistData)
data("Armada")
str(Armada)
Armada
armada <- Armada[ , -c(1, 6)]
armada.pca <- prcomp(armada, scale = TRUE)
summary(armada.pca)
plot(armada.pca, type = "lines", pch = 16, cex = 2)
biplot(armada.pca)