
Photo by Roland Lösslein on Unsplash
今回はTicketの分析をします。
まずは、NAの有無を確認します。

NAは無いようです。
始めの数個のデータを眺めてみます。
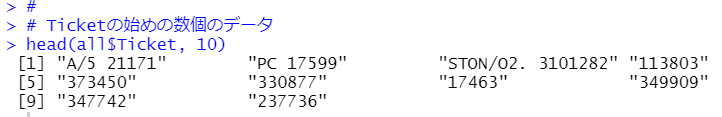
数字だけのデータもあれば、アルファベットのあるデータもあります。
数字だけのデータがどのくらいの比率なのかみてみます。

数字だけのTicketは73%ぐらいですね。
Ticketが数字だけなら1, アルファベットも含むなら0というダミー変数を作成します。

trainとtestでこのnum_ticketの比率に差があるかを確認します。
まずは、それぞれの比率を確認します。
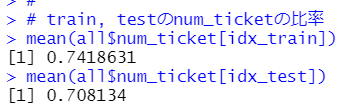
trainは74%でtestは71%ほどですね。この差は有意な差なのでしょうか?
prop.test関数で検定します。
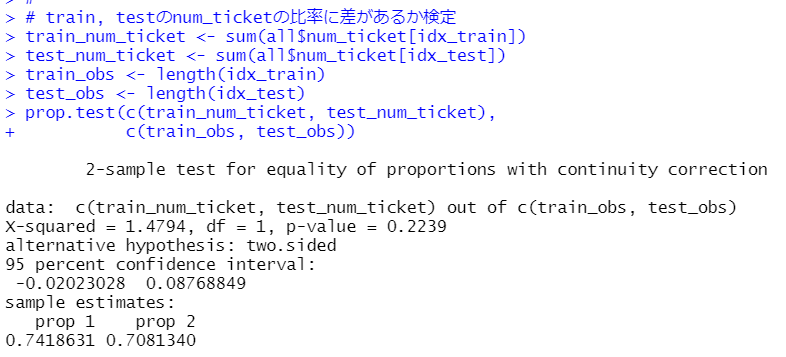
p-value = 0.2239 と0.05よりも大きい値なのでtrainとtestではnum_ticketの比率に有意な違いは無いとわかりました。
せっかくtrain_num_ticketなどとオブジェクトを作りましたからグラフにしてみます。

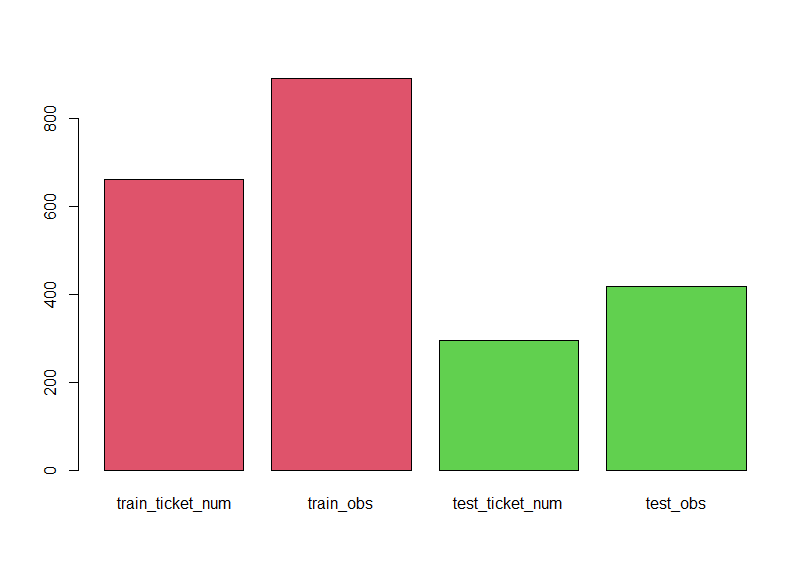
グラフで見比べると、比率に大きな違いはないように感じますね。
Surviedとnum_ticketの関係を見てみます。
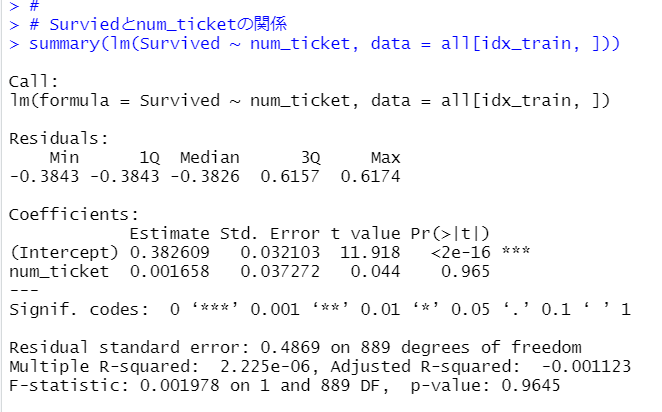
num_ticketの係数は0.001658と非常に小さく、p値も0.965と大きいです。
Ticketが数字だけなのか、アルファベットも入っているのかは生存確率とは関係が無いようです。
今回は以上です。
次回は
です。
初めから読むには、
です。