
UnsplashのMarek Piwnickiが撮影した写真
の続きです。
前回はCSVファイルにあるデータをR言語に読み込ませ、分析用のデータフレームを作成するところまで進みました。
まず、hist()関数でvalue: 売上高(百万円単位)の分布をみてみましょう。

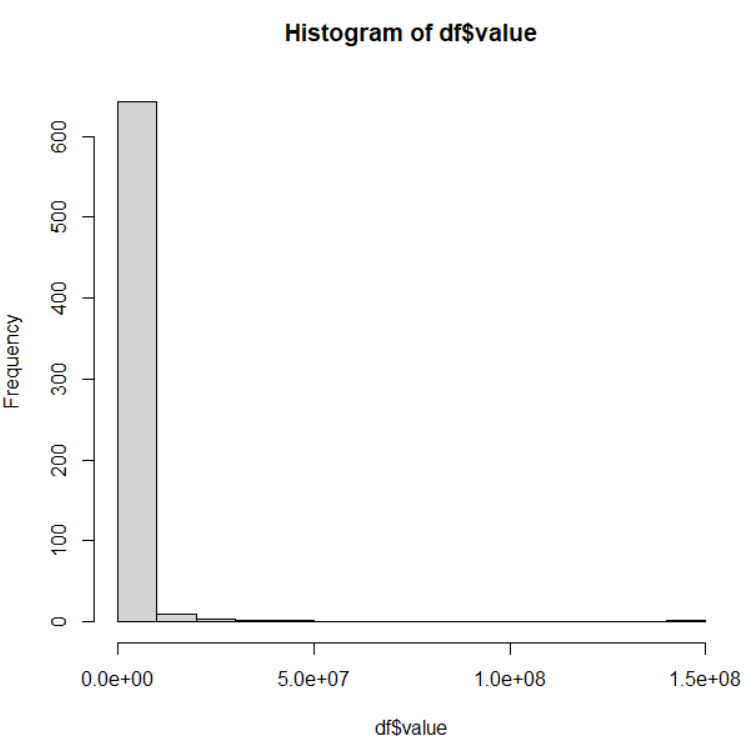
左に分布がかたまってしまっています。
summary()関数でvalueの最小値や最大値などをみてみます。

最小値が0で最大値が143兆4432億15百万円です。
あまりにもデータにバラツキがありますので、一人当たりの売上高を計算して、そのヒストグラムを見てみます。

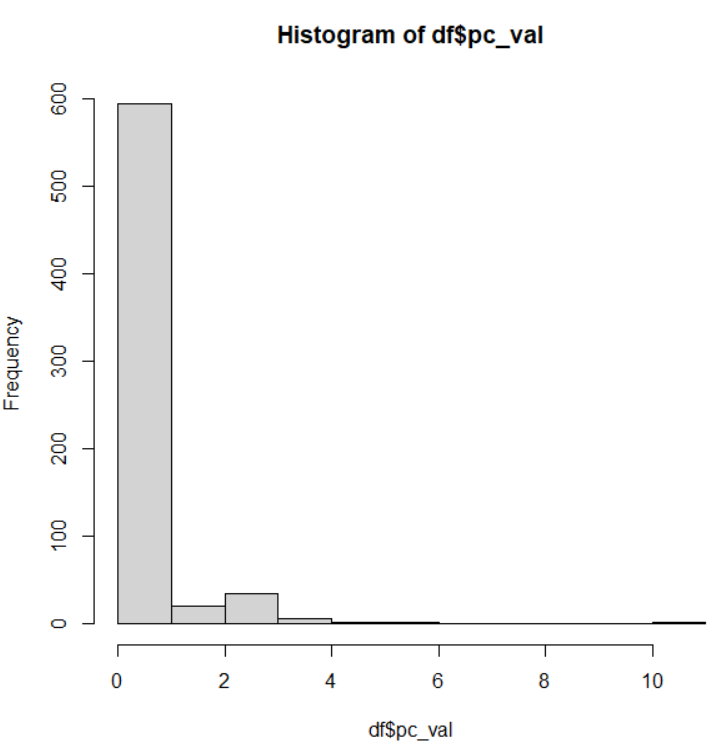
一人当たりの売上高にしても、左に分布が偏っていますね。
このpc_valのサマリーも見てみましょう。

最小値は0、最大値は1030万円、平均値は35万円、中央値は9万6千円です。平均値と中央値がかなり違います。
industry: 産業種類ごとのpc_valを見てみます。plot()関数を使います。

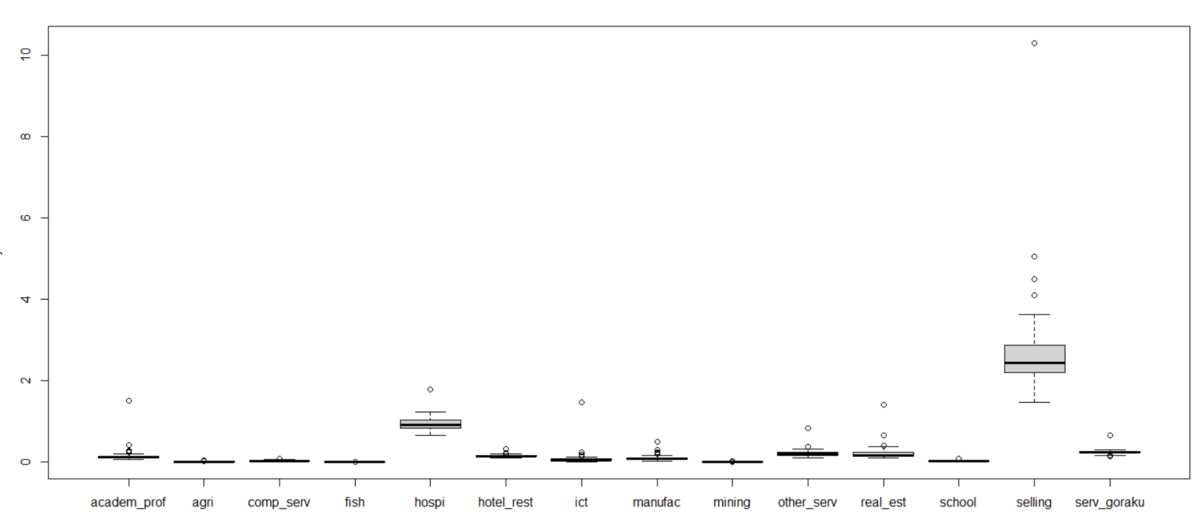
selling : 卸売、小売のセクターが突出しています。
selling を除外してグラフを描いてみます。

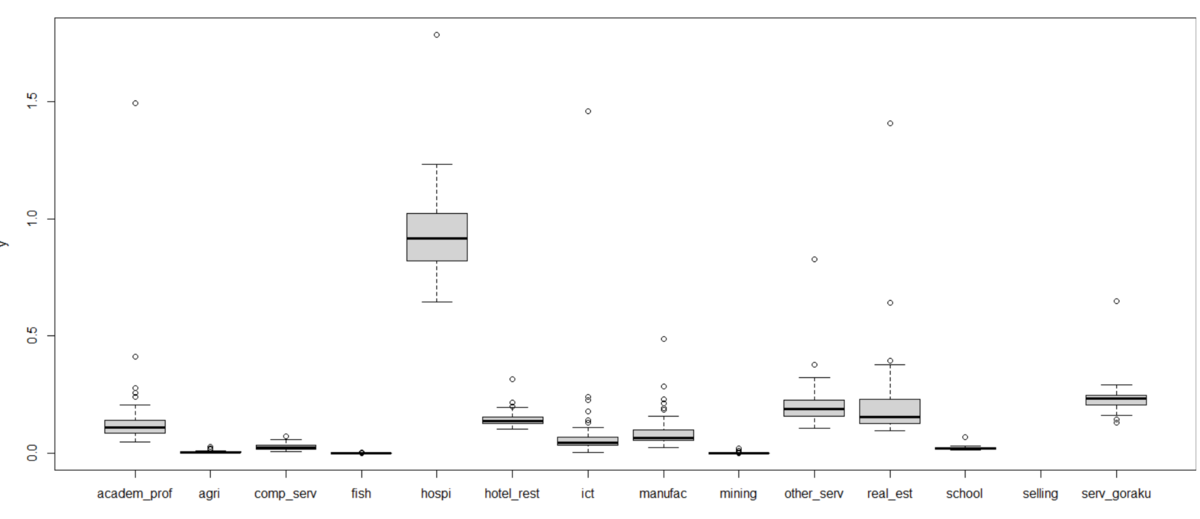
hospi : 医療、福祉が一人当たりの売上高が高いのですね。
tapply関数でindustryごとの最小値や平均値などを確認します。
tapply()関数で計算したindustryごとの結果をcbind()関数でまとめて一つのオブジェクトにしています。ound()関数で小数点以下第3位までを出力しました。

。sd : 標準偏差 / mean : 平均値 = cv : 変動係数も計算しましょう。
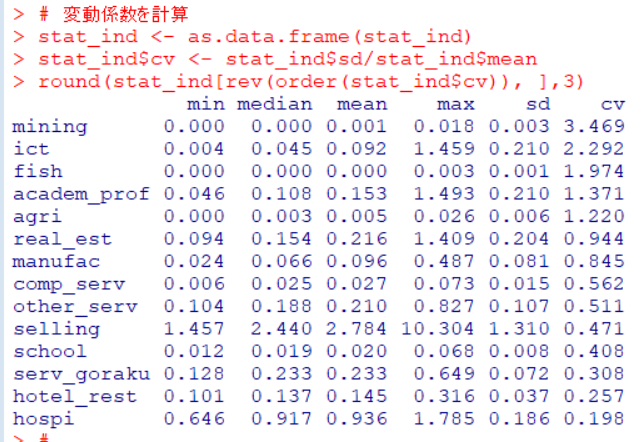
データ処理をしやすいように、as.data.frame()関数でデータフレーム型にstat_indのオブジェクトを変換してからcvを計算しました。order()関数とrev()関数をつかってcvの大きい順に表示してみました。miningt : 鉱業のセクターが一番バラツキがありますね。
今度は、都道府県ごとのpc_valをみてみます。

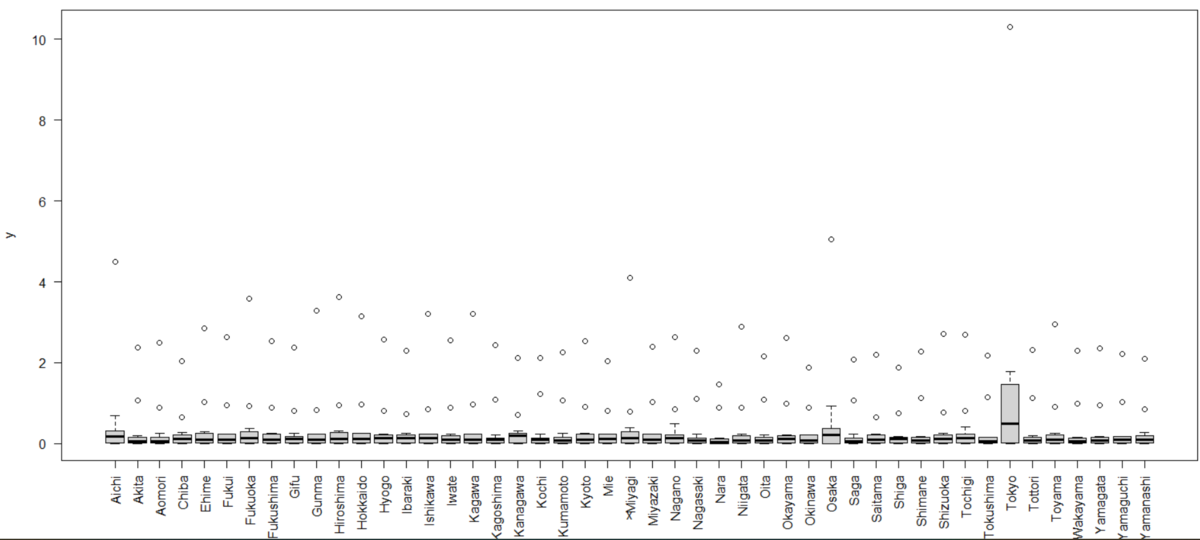
ちょっとわかりにくいかもしれませんが、Tokyoが一番バラツキがあり値が大きいですね。
industryと同じように、都道府県ごとの最小値などを計算しましょう。
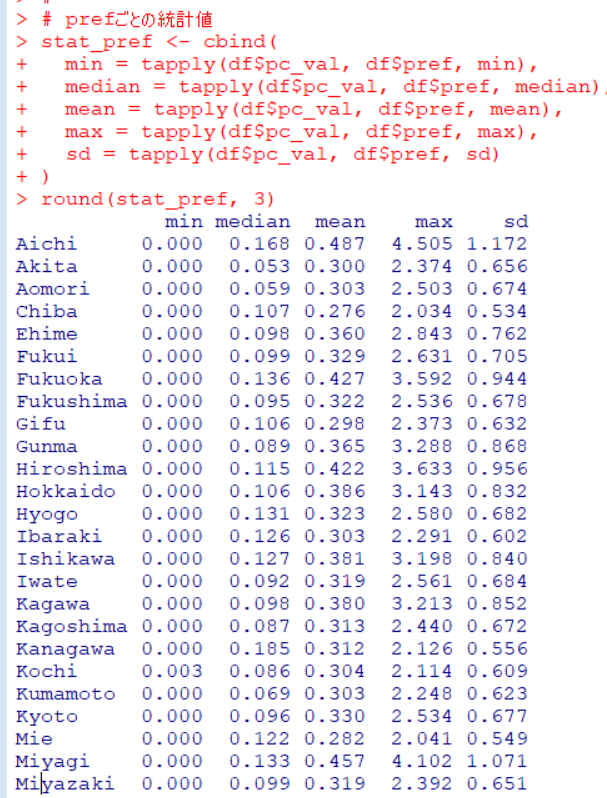
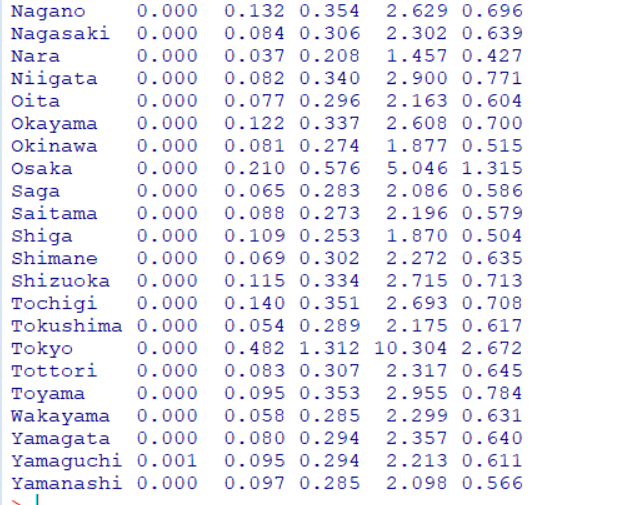
cv : 変動係数も計算しておきます。
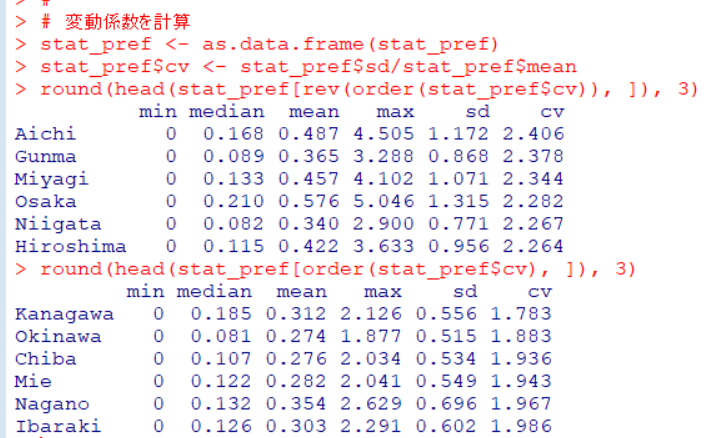
変動係数が大きいところは、愛知県や群馬県、小さいところは神奈川県や沖縄県でした。
今回は以上です。
今回は、1人当たりの売上高を計算して、産業種類別と都道府県別の1人当たり売上高を計算してみました。
次回は、
です。
初めから読むには、
です。