
Unsplashのmicheile dot comが撮影した写真
の続きです。今回はR言語でクラシフィケーション分析をしてみようと思います。
まず、caretパッケージの読み込みをします。

2019年と2020年のデータをトレーニング用のデータ、2021年のデータをテスト用のデータにします。

indu: 製造業か、卸売小売業かを被説明変数にして、wageとopを説明変数にしてクラシフィケーション分析をしましょう。
分析する前にwage, op, induを視覚化します。
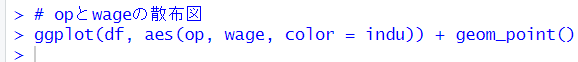
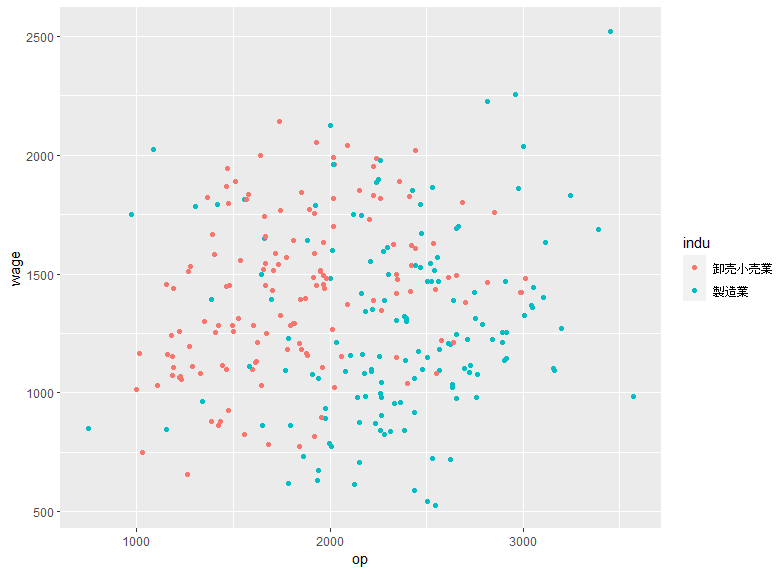
この散布図を見ると、右下エリアは製造業で、左上エリアは卸売小売業が多いことがわかります。
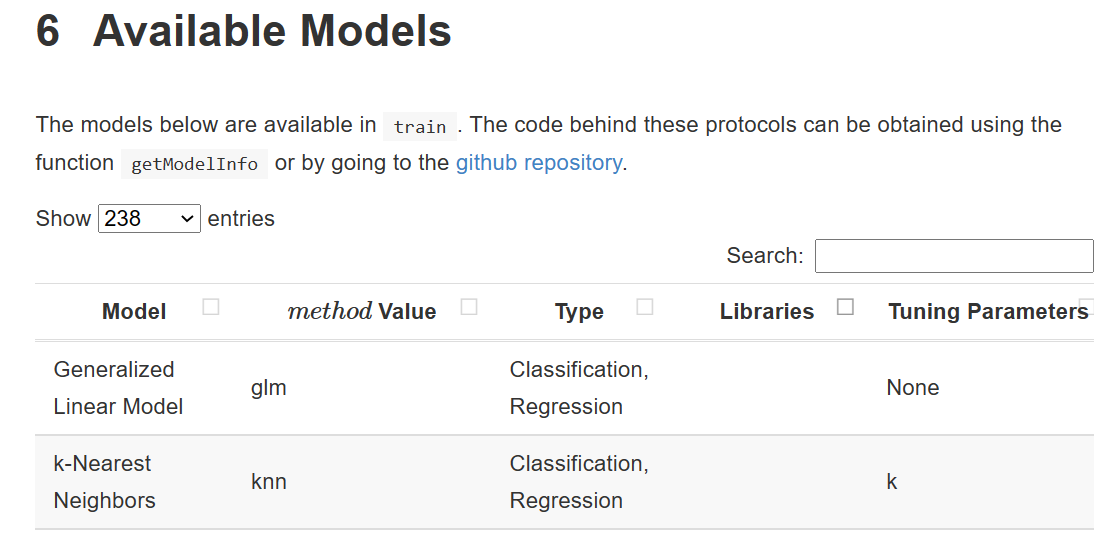
caretパッケージのウェブページ(6 Available Models | The caret Package (topepo.github.io)を見ると、Generalized Linear Modelとk-Nearest Neighborsの2つのモデルが追加のパッケージがいらないでクラシフィケーションをできるようなので、この2つのモデルをやってみます。
train()という関数でモデルを作ります。
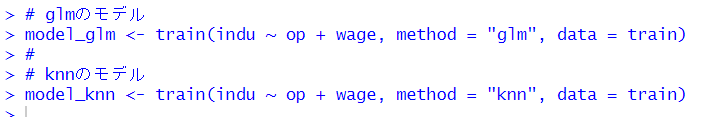
そして、predict()という関数で予測します。

そうしたら、confusionMatrix()という関数で答え合わせができます。
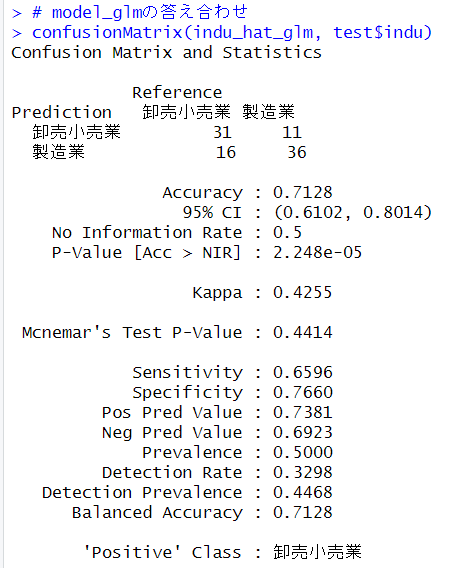
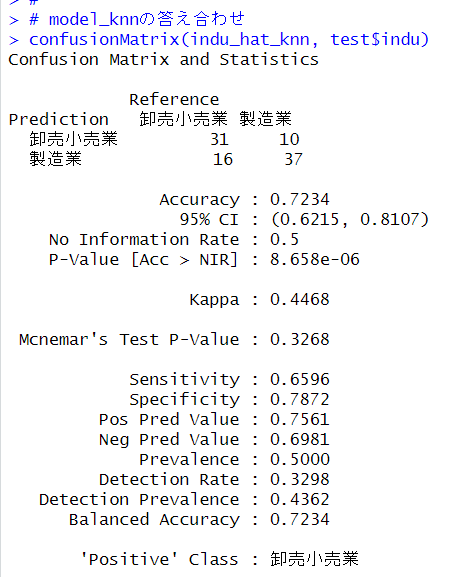
Accuracyの値が正解率です。
glmのモデルの正解率は、71.28%で、
knnのモデルの正解率は、72.34%でした。
glmのモデルの正解数は67個、knnのモデルの正解数は68個でしたので、knnのモデルのほうが1個だけ多く正解しました。
今回は以上です。
次回は、
です。
初めから読むには、
です。
今回使用した関数は
library() --- caretパッケージの読み込みに使用
filter() --- データフレームをフィルター
ggplot() + geom_point() --- 散布図
train() --- モデルを作る
predict() --- 予測する
confusionMatrix() --- 実際のカテゴリーと予測されたカテゴリーの答え合わせ