
UnsplashのLeonid Antsiferovが撮影した写真
の続きです。引き続き、caretパッケージでratioを予測するモデルを作成していきます。
まずは、linear regression modelで、もう少し複雑なモデルにしてみます。
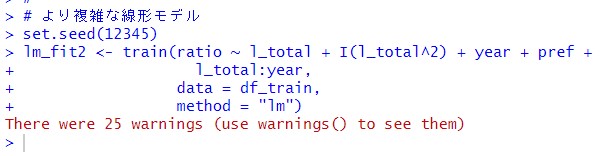
l_totalの2乗項と、l_total x year を追加してみました。
このlm_fit2と名付けたオブジェクトを表示してみます。
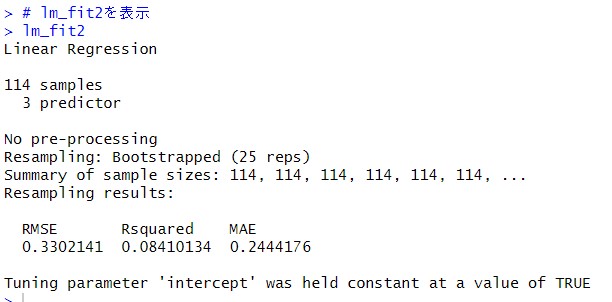
names()関数でどういう要素があるか見てみます。

たくさんありますね。finalModelが最終的なモデルですかね。みてみます。
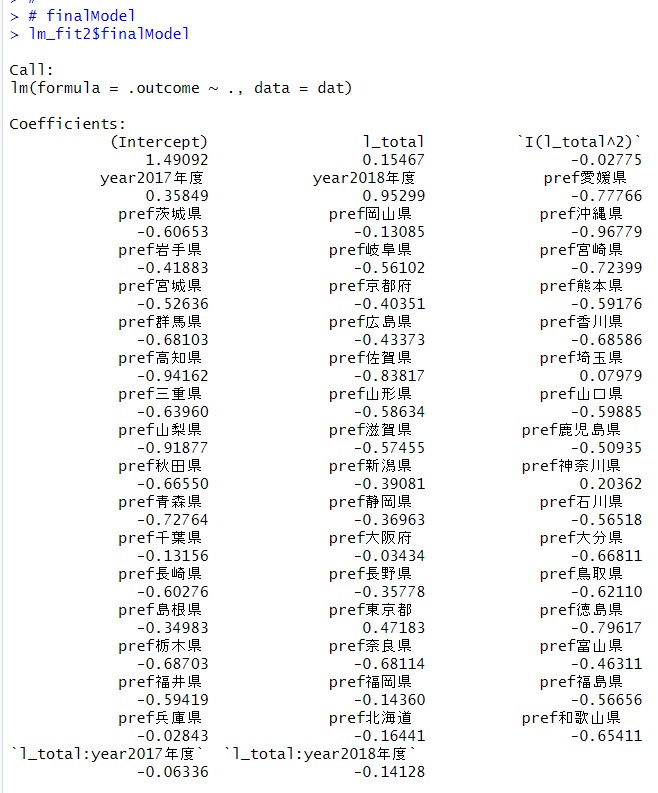
このような推定結果でした。
では、このモデルを使って、df_testのデータを使い、ratioを予測してみます。

predict()関数で予測できます。
これを評価します。

この評価結果を保存しておきます。
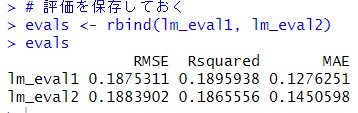
複雑な式のほうが、予測精度は低いですね。
この調子で、他のモデルも試していきます。まずは、Random Forestモデルです。
method = "rf"にするだけです。

rf_fitをみてみます。
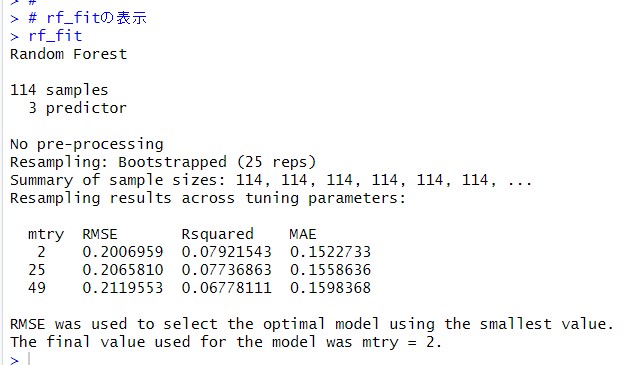
mtryというのがパラメータで、mtry = 2 が最終的に採用されたようです。
finalModelを表示してみます。

見方がわからないですが、500回の決定木モデルを試したってことですかね。。
予測と評価をします。
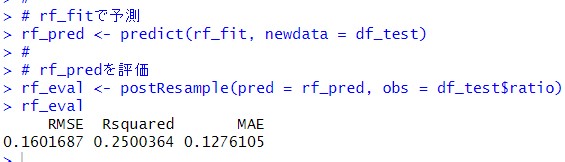
この結果も保存しておきます。
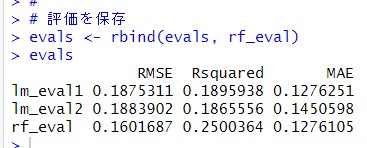
いままでの3つのモデルの中では、Random Forestが一番予測精度が高いですね。
次は、gam, Generalized Addaptive Model with using Splinesを試してみます。

gam_fitを表示してみます。
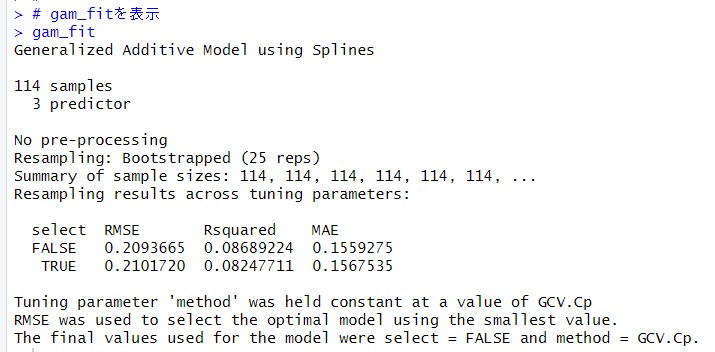
finalModelを表示してみます。
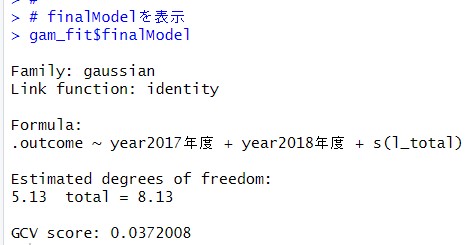
GVC scoreってなんでしょうね。わからないです。
予測して、評価します。
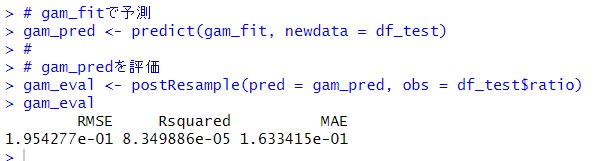
この評価結果も保存しておきます。
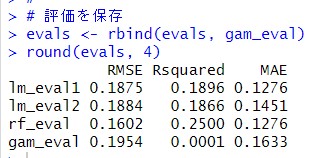
round()関数で小数点以下4桁までの表示にしました。
最後にSupport Vector Machines with Linear Kernelのモデルをやってみます。

svm_fitオブジェクトを表示してみます。

final modelを表示してみます。

パラメータには、spsilionとcost C というのがあるようです。
予測をして結果を評価します。
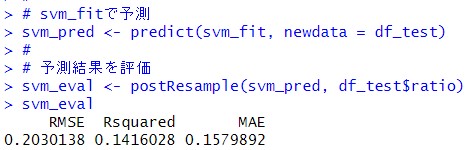
全部の予測結果を表示してみます。
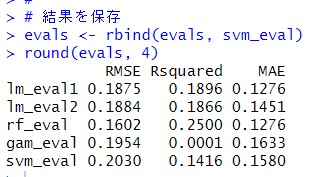
RMSEの小ささで評価すると、Random Forestが一番予測精度が高く、2番目が単純なlinear regression modelでした。
今回は以上です。
次回は、
です。
初めから読むには、
です。