
前回はsalary: 決まって支給する現金給与額【千円】と各変数の関係を視覚化しました。
今回はそれらの変数で重回帰分析をしてみたいと思います。
私の頭の中にあるモデル式は、
現金給与額 = beta0 + 年ダミー + 業種ダミー + 性別ダミー + 年齢クラスダミー + 勤続年数 + 総労働時間 + 労働者数(自然対数)
というものです。R ではファクター変数はそのままダミー変数に変換して回帰分析してくれますが、一応、わかりやすくダミー変数変換してから回帰分析してみようと思います。
年は、2020年と2023年の二つがあります。
業種は、卸売業、小売業と金融業、保険業の二つがあります。
年齢クラスは30~34歳と50~54歳の二つがあります。
回帰分析用のデータフレームを作成します。
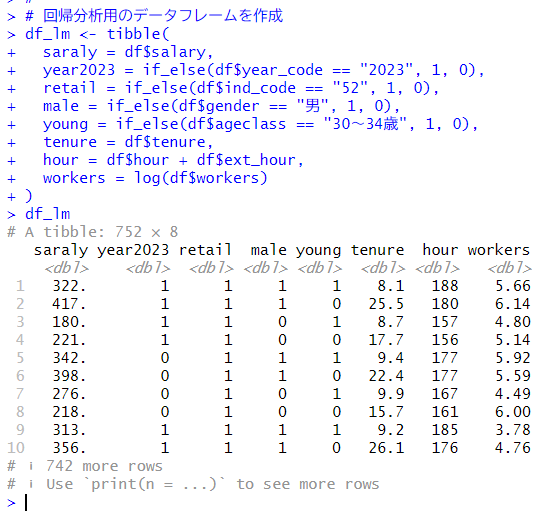
year2023は、2023年なら1、2020年なら0のダミー変数です。
retailは、卸売業、小売業なら1、金融業、保険業なら0のダミー変数です。
maleは、男性なら1、女性なら0のダミー変数です。
youngは30~34歳なら1、50~54歳なら0のダミー変数です。
tenureは勤続年数です。
hourは所定内労働時間と超過労働時間の合計です。
workersは労働者数を自然対数変換した値です。
なので、モデル式は、
salary = β0 + β1 * year2023 + β2 * retail + β3 * mail + β4 * young + β5 * tenure + β6 * hour + β7 * workers + u
です。uは誤差項です。
それでは、各βをOLSで推計します。lm()関数で簡単にできますね。
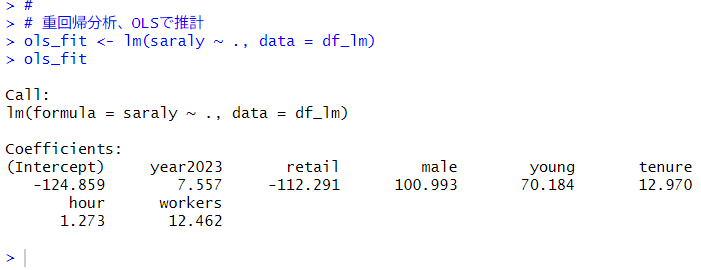
2023年のほうが2020年と比べて、7500円お給料が多い、卸売業、小売業のほうが金融業、保険業より11万2千円お給料が少ない、男性のほうが女性より10万円お給料が多い、30~34歳のほうが50~54歳より7万円お給料が多い、勤続年数が1年延びると1万3千円お給料が増える、労働時間が1時間伸びると、1200円お給料が増える、労働者数が1%多いとお給料が1万2千円多い、という推計結果です。
summary()関数で各変数のt値、p値をみてみます。

全ての変数でp値は0.05よりも小さな値です。つまり全ての変数が統計的に有意であることになります。
Heteroskedasticityかどうかを確認します。
lmtestライブラリーのbptest()関数で確認できます。

p値が0.05よりも小さい値ですので、Heteroskedasticityがあるようです。
こんなときは、Heteroskedasticity-robust inference です。
carパッケージ、lmtestパッケージを読み込みます。
coeftest()関数を使います。
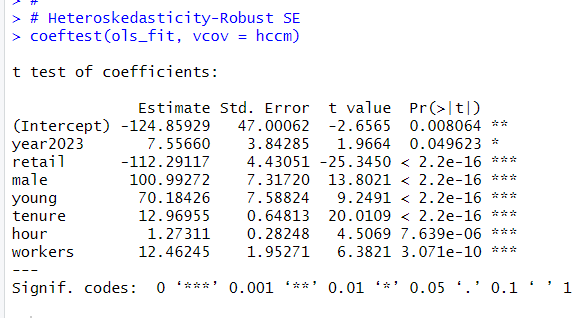
どの変数も有意な変数という結論は変わらないですね。
私が意外に思ったのは、youngがプラスの値だったということです。30~34歳のほうが50~54歳よりも、(他の条件が同じなら)7万円もお給料が多いということです。勤続年数が説明変数に入っていますからこういう結果になっているんですね。同じ勤続年数だったら、年齢の若い人のほうがお給料が多いということですね。
今回は以上です。
次回は、
です。
はじめから読むには、
です。
今回のコードは以下になります。
#
# 回帰分析用のデータフレームを作成
df_lm <- tibble(
saraly = df$salary,
year2023 = if_else(df$year_code == "2023", 1, 0),
retail = if_else(df$ind_code == "52", 1, 0),
male = if_else(df$gender == "男", 1, 0),
young = if_else(df$ageclass == "30~34歳", 1, 0),
tenure = df$tenure,
hour = df$hour + df$ext_hour,
workers = log(df$workers)
)
df_lm
#
# 重回帰分析、OLSで推計
ols_fit <- lm(saraly ~ ., data = df_lm)
ols_fit
#
# 各変数のt値、p値
summary(ols_fit)
#
# Heteroschedasticityの確認
lmtest::bptest(ols_fit)
#
# car, lmtestパッケージの読み込み
library(car)
library(lmtest)
#
# Heteroskedasticity-Robust SE
coeftest(ols_fit, vcov = hccm)
#
(冒頭の画像は、Bing Image Creator で生成しました。プロンプトは、White Gardenia flowers in the deep woods. Photo です。)