の続きです。前回の分析で、女性の給与は男性よりも確かに低いことがわかりました。
今回は、R言語のlm関数で男性か女性かを分類するモデルを作ってみます。
まず、mutate関数とifelse関数でgendarをm, f ではなくて1, 0という2つの数値をとるデータフレームを作成します。

次に、このdf_classificationをモデル作成用のデータフレームとモデル評価用のデータフレームに分割します。
set.seed関数で乱数のセットを決めます。

str_classificationは134行ありますので、そのうちの100個の観測をモデル作成用にして、残りの34個の観測をモデル評価用にしましょう。
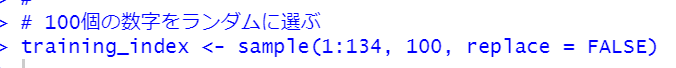
sample関数で1から134の数字のうちランダムに100個の数字を選択しました。

df_trainとdf_testの男女比率があんまり違っていたらよくないので、t.test関数で確認してみます。

p-valueが0.696なので違いは無いといっていいです。
mena of x がdf_trainのほうで、0.49なので、男性49%, 女性51%ですね。
mean of y がdf_testのほうで、0.53なので、男性53%、女性47%ですね。
lm関数でgendarを被説明変数にしたモデルを作成します。

summary関数でモデルの概要を表示します。
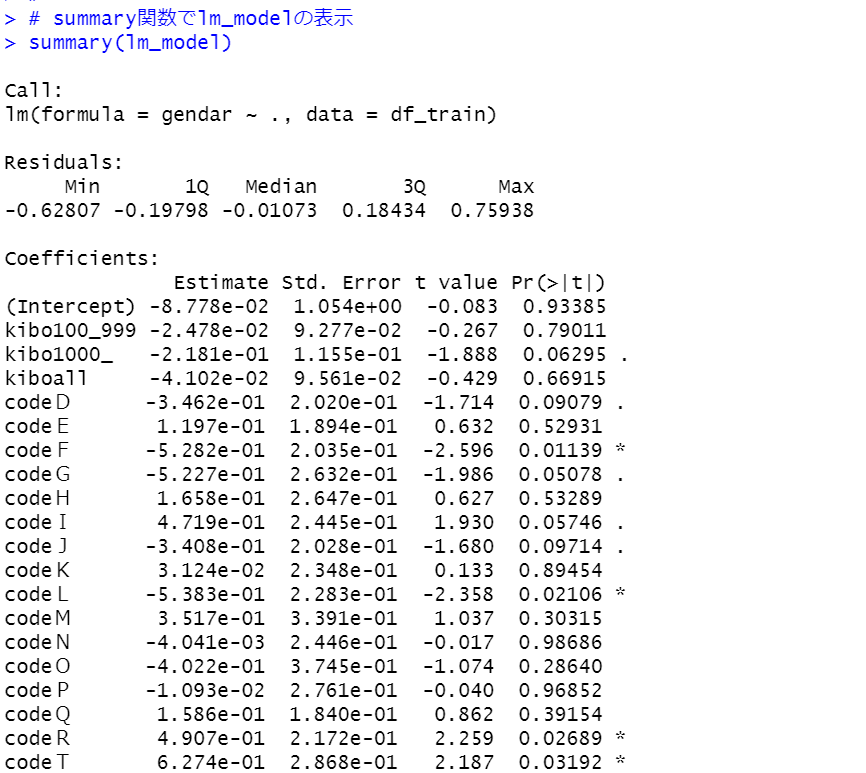
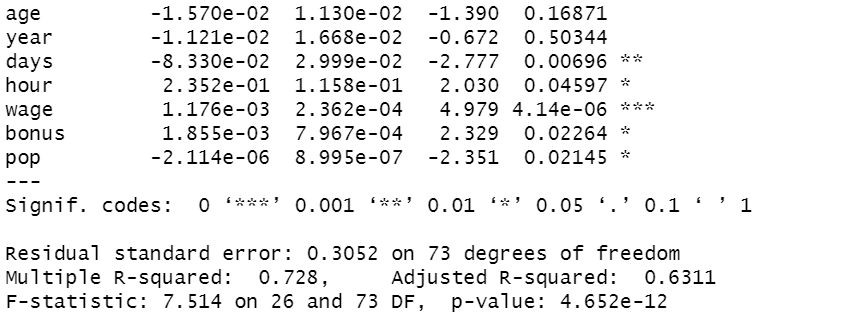
p-valueが4.652e-12なので有意な統計モデルです。
wageのt値が一番高いですから、やはり給与は男女間で違いますね。
predict関数でこのモデルをつかってdf_testデータからgendarを予測します。

table関数で結果を見てみましょう

lm_modelが女性だと予測して実際にも女性だったのが16個、本当は男性だったのが4個。
lm_modelが男性だと予測して実際に男性だったのが14個、本当は女性だったのが0個です。
正解率は、(16+14)/34=88%でした。
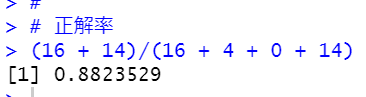
今回は以上です。
次回は
です。
はじめから読むには、
です。