
Bing Image Creator で生成: Long view landscape, ancient trees, small lakes, some flowers, blue sky, Photo
の続きです。
今回は、class パッケージの knn() 関数で k-nearest neighbors の手法で M を予測します。
class パッケージを読み込みます。

k-nn は k というパラメータがあって、これは、周りの何個の観測データから値を決定するか、というパラメータです。
最適な k を決定するために、df_train をさらにトレーニング用とテスト用にわけます。
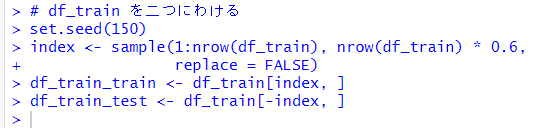
さらにこれらをマトリックスにします。

これで knn() 関数の準備ができました。
k = 1 で試してみます。

正解率は 96.7% と好成績ですね。
k = 3 ではどうでしょうか?

正解率は 97.3% とさらによくなりました。
このように k の値によって正解率が変わるので、k を引数にして正解率を計算する関数を作成します。

関数が正常に動くかどうかテストします。
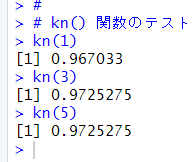
うまく作動しているようです。
k = 1 から k = 100 までの正解率のグラフを描いてみます。

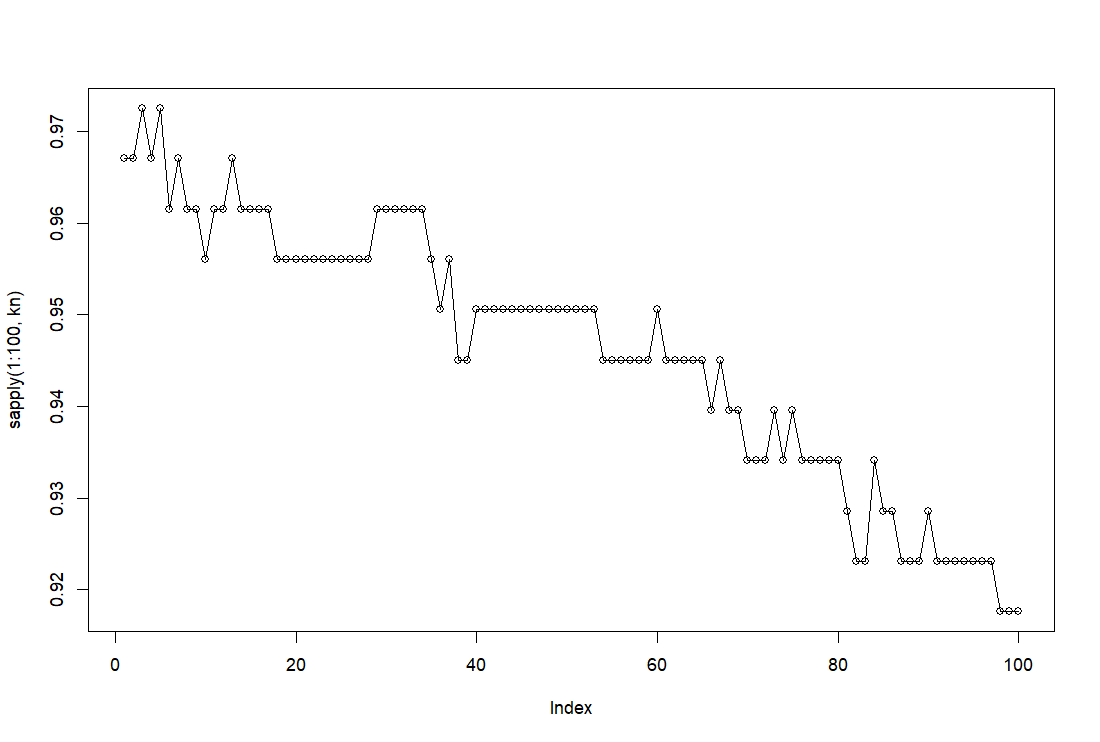
k = 3, k = 5 のときが正解率が一番高いです。
なので、 K = 3, k = 5 に加えて、k = 1 も使って、この3つの予測の多数決を最終予測にしましょう。

これら3つの予測を合計して、2 以上なら1、1 以下なら 0 として最終予測とします。

正解率はどのくらいでしょうか?

正解率は 98.2% でした。いままでで一番良い結果でした。
今回は以上です。
次回は、
です。
初めから読むには、
です。