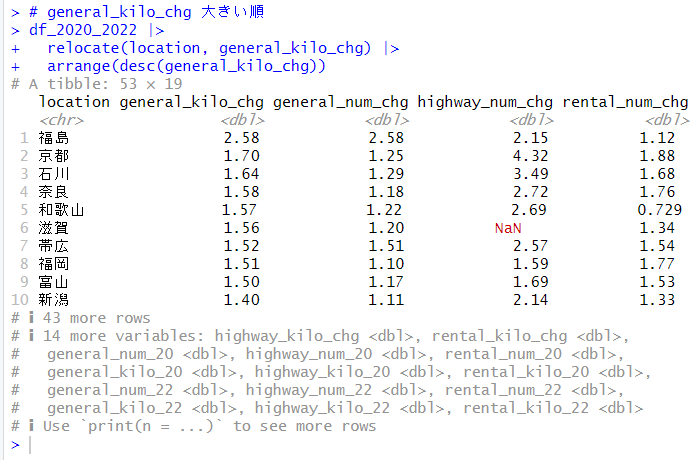
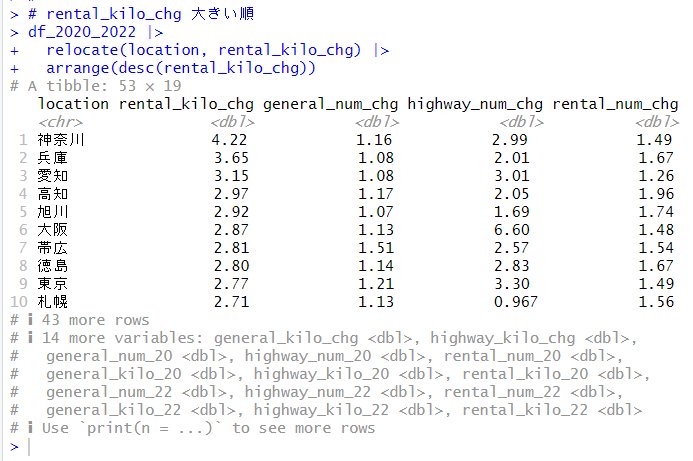
Bing Image Generatorで生成: Photo, Winter snow field with red cameria
の続きです。
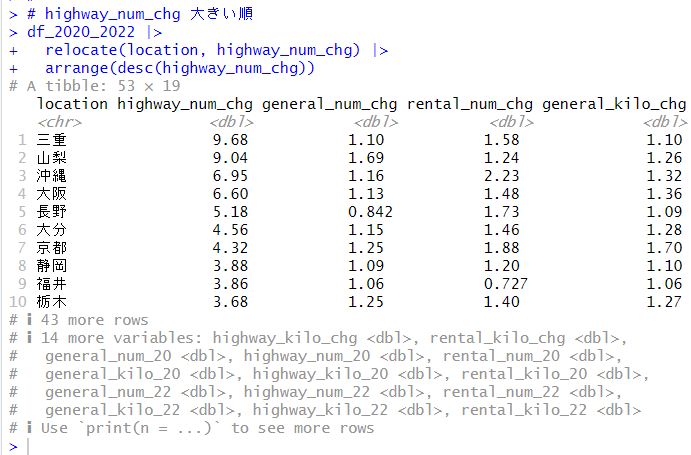
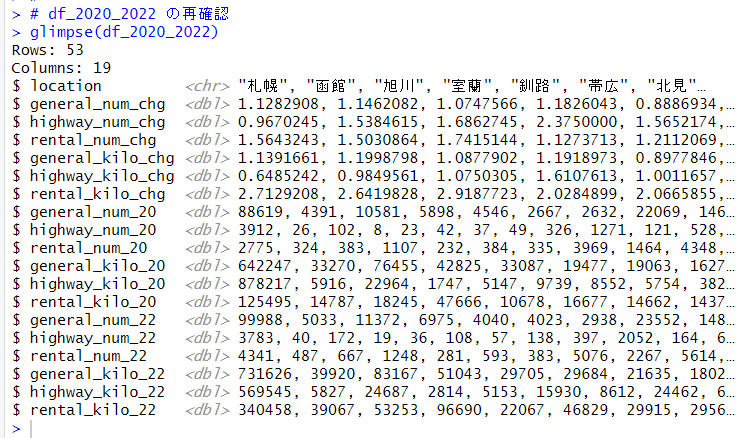
今回は、R で主成分分析をしてみようと思います。
:データ解析の基礎から最新手法まで")
を参考にしてやってみます。
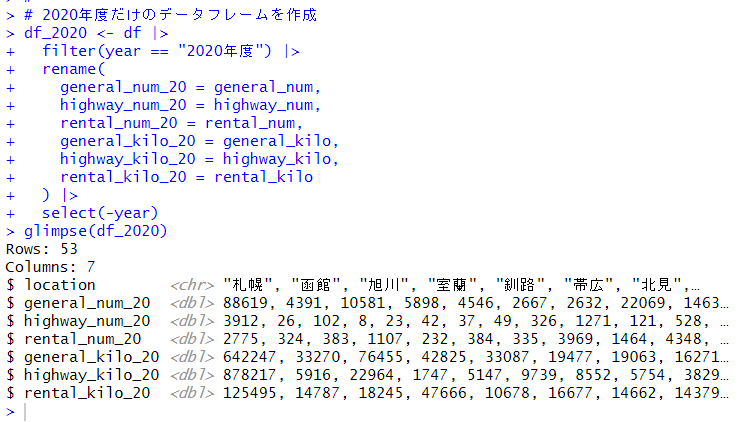
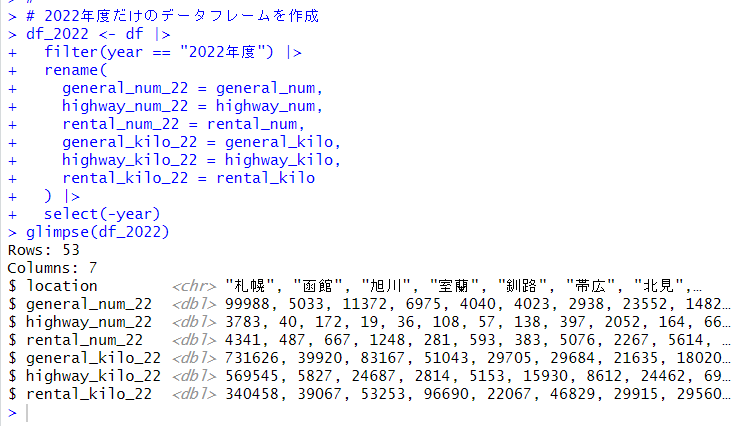
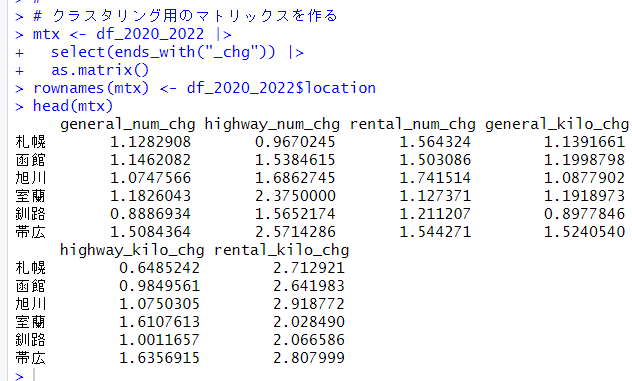
まず、princomp() 関数で主成分分析のオブジェクトを生成します。使用するデータは、前回作成した、mtx です。

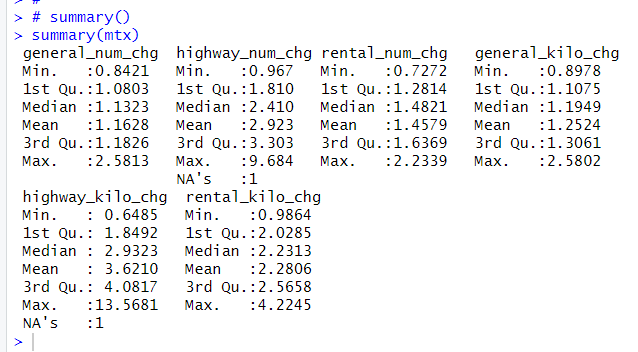
summary() 関数で結果を見ることができます。

mtx の変数は 6つありましたが、Comp.2 の Cumulative Proportion が0.9549なので、Comp.1 と Comp.2 の2つの成分で6つの変数の 95.5% を説明できる、ということですね。
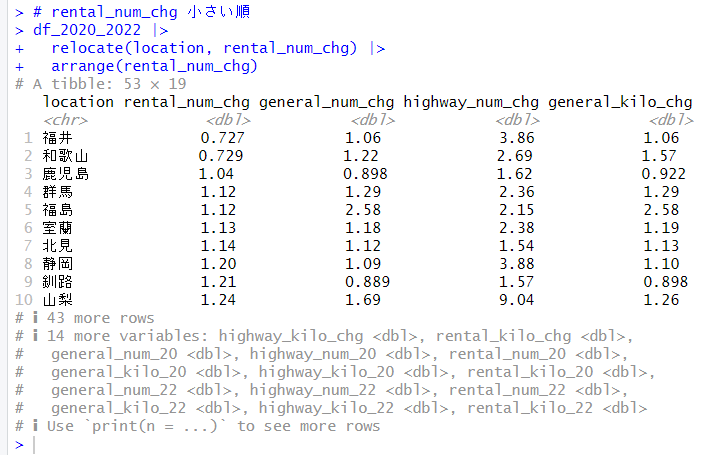
$loadings で主成分がわかります。

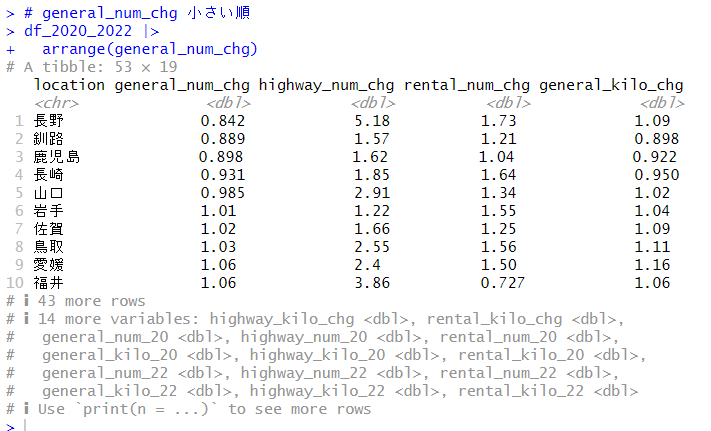
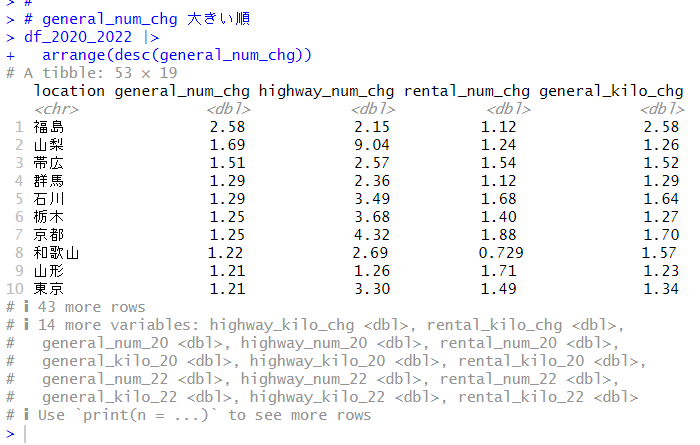
Comp.1 はhighway_num_chg, highway_kilo_chg の2つの変数、Comp.2 はそれらに加えて、rental_kilo_chg が採用されています。
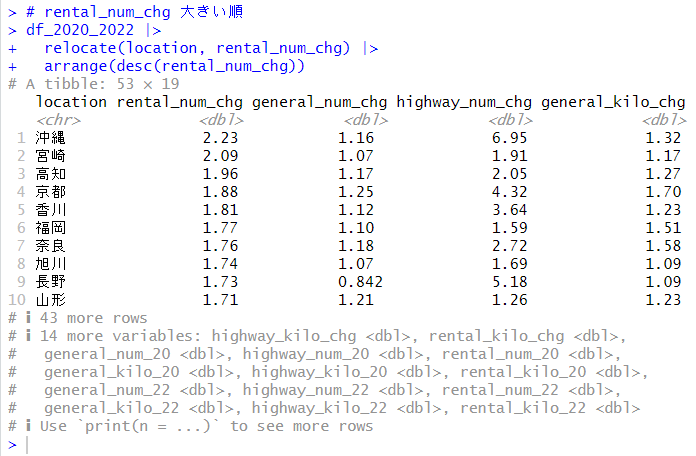
Comp.1 と Comp.2 の散布図を描いてみます。


highway_num_chg, highway_kilo_chg, rental_kilo_chg の他の3つの変数は、ほとんど同じ位置にあることがわかります。
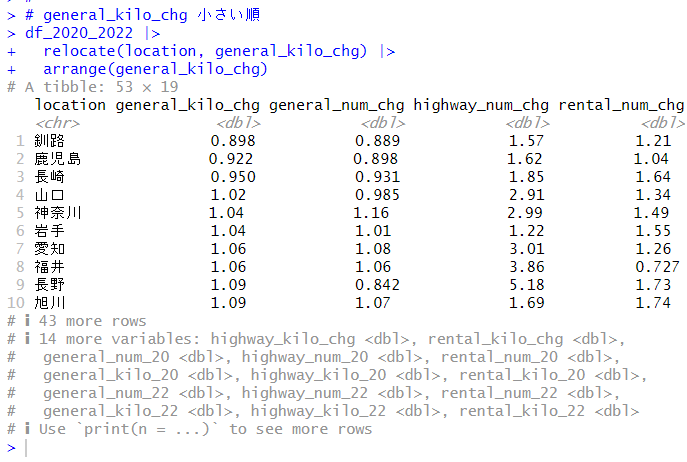
$scores で主成分得点がわかります。


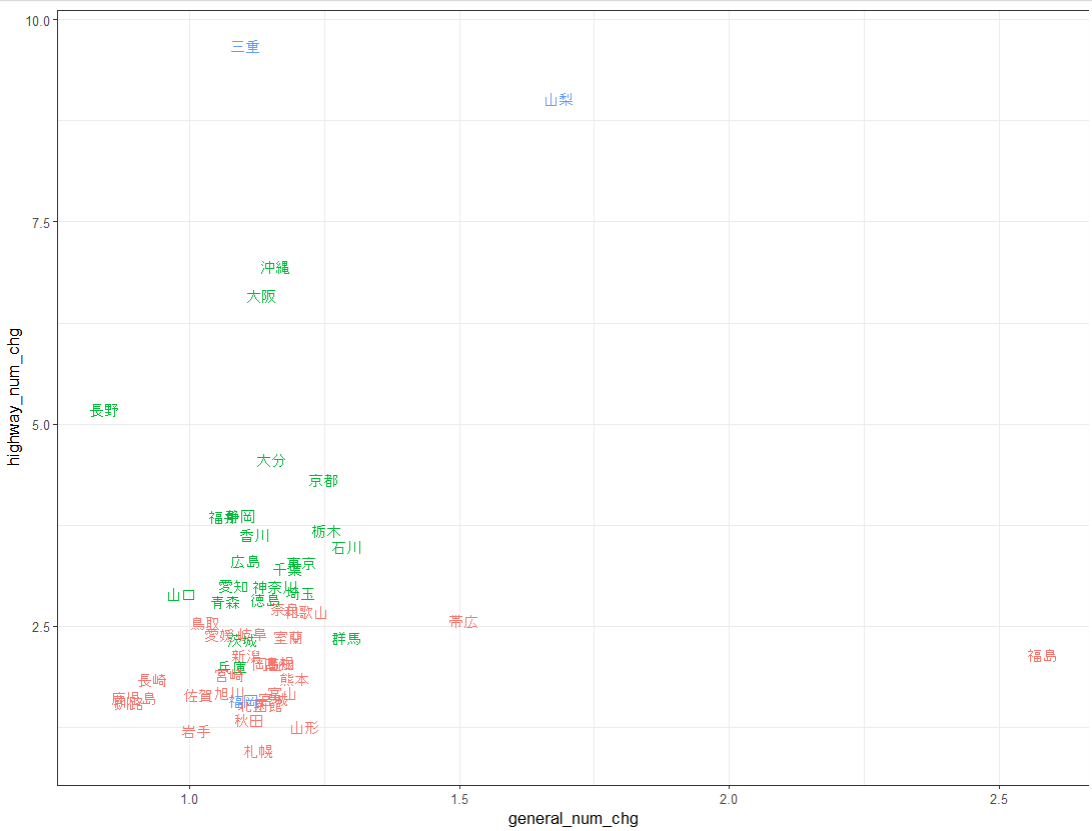
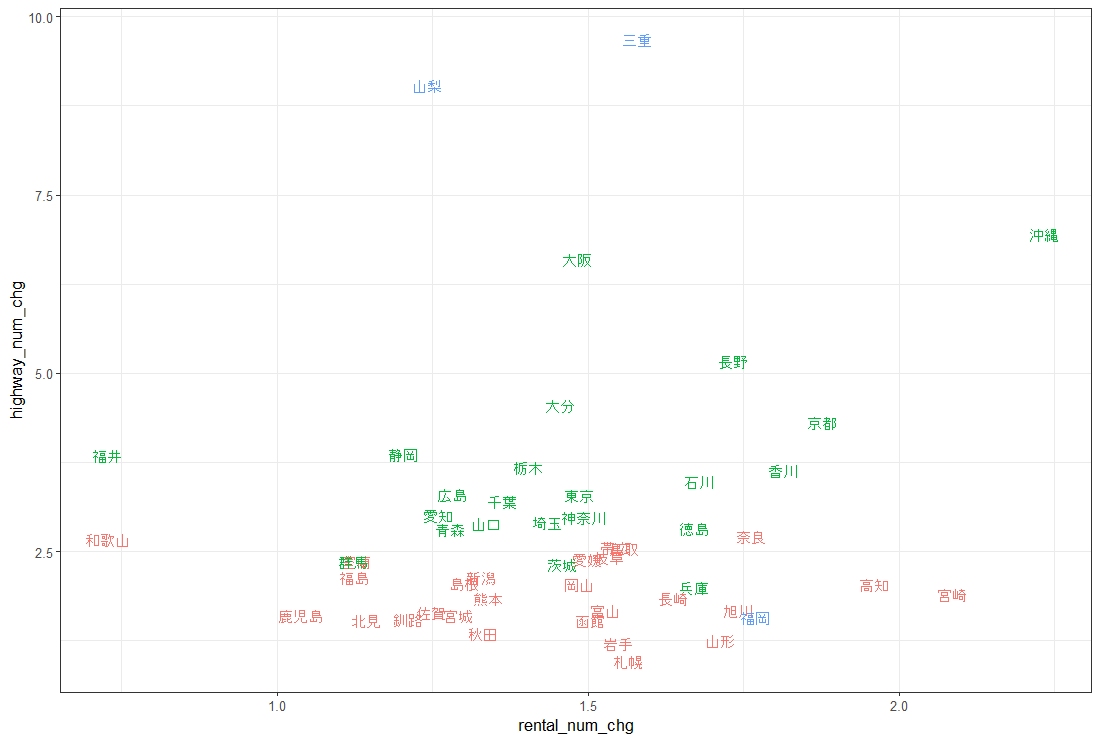
この主成分得点の Comp.1 と Comp.2 の散布図を描いてみます。


福岡や山梨は他の都道府県とは違ってユニークな存在だとわかります。
次は、biplot() 関数でbiplot を描いてみます。


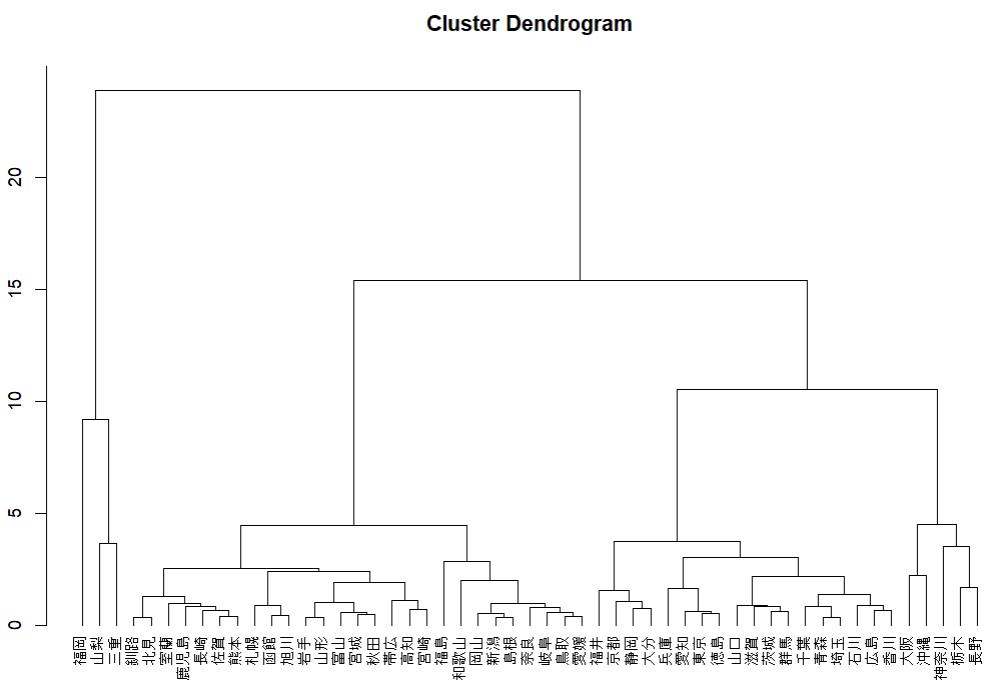
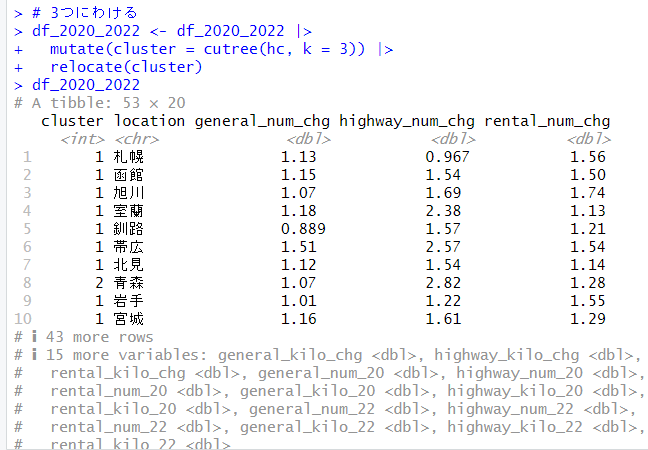
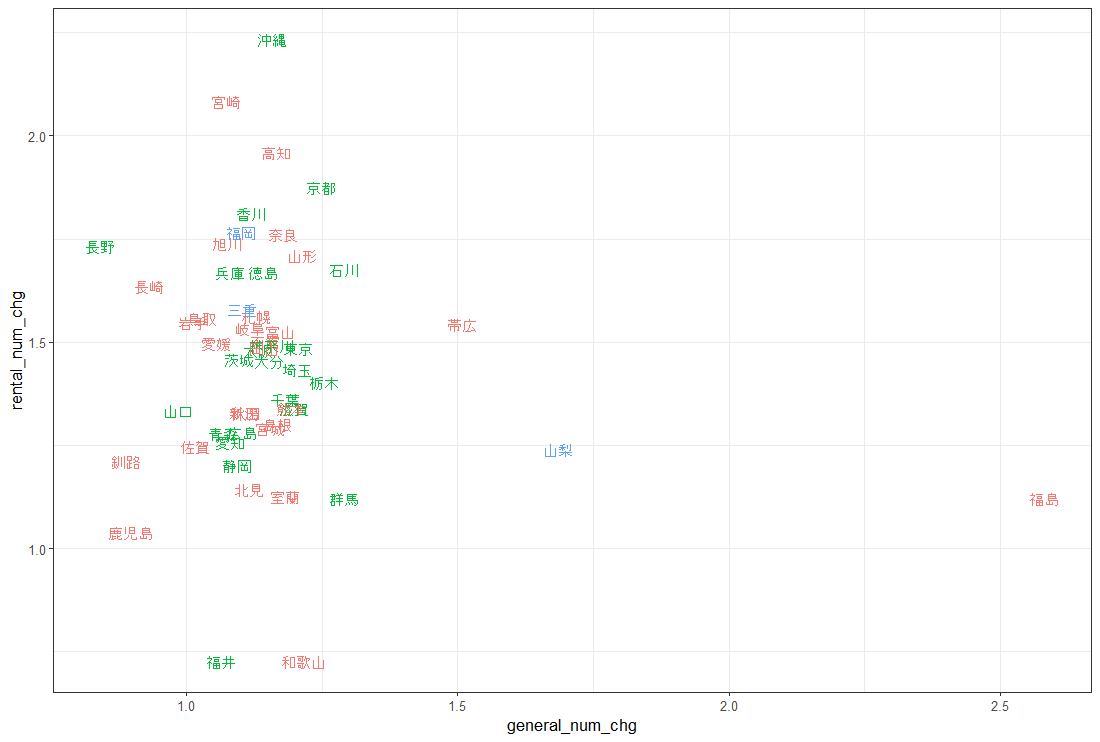
最後に今回の主成分分析の散布図に、前回のクラスタリングの結果を組みわわせてみます。


きれいに3つのクラスターが散布図上で分類されていますね。
今回は以上です。
初めから読むには、
です。
")

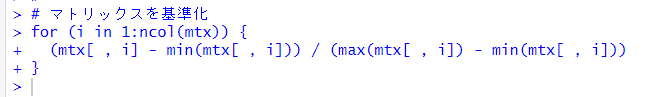






























")