の続きです。今回は2017年度の男女の1日当りの所定内給与額の比率を2005年度のデータを使って重回帰分析をしてみたいと思います。
まず、filter関数をつかって2005年度だけのデータフレームを用意します。
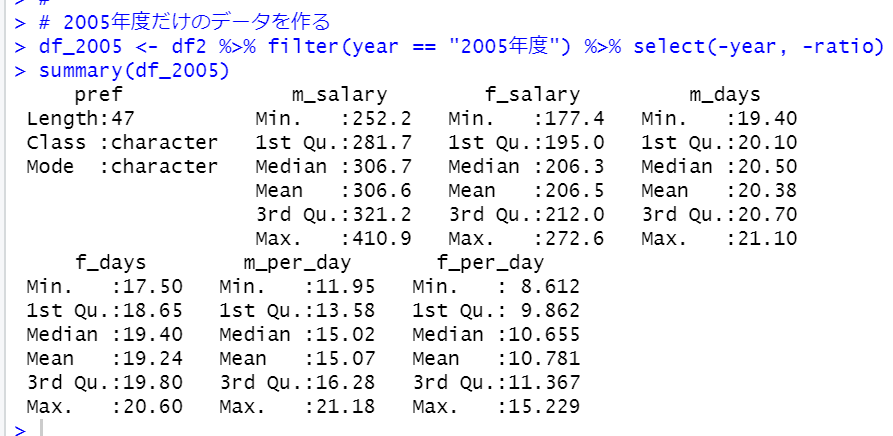
このdf_2005というデータフレームとdf2というデータフレームをinner_join関数を使って結合します。

Y2017が被説明変数で、説明変数はY2005, m_salary, f_salary, m_daysにします。f_daysやm_per_day, f_per_dayを入れないのは、Y2005, m_salary, f_salary, m_daysを使えばm_per_dayとf_per_dayは計算できるからです。
lm関数で重回帰分析をしてみます。
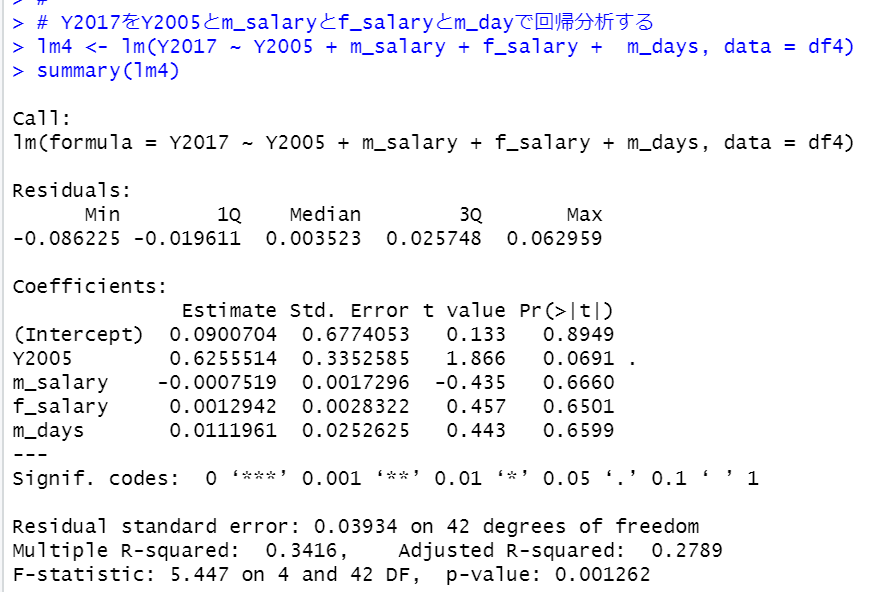
p-valueは0.001262と0.05より小さく有意な統計モデルです。でもその説明変数も有意ではないですね。
tidy関数でモデルを出力してみます。
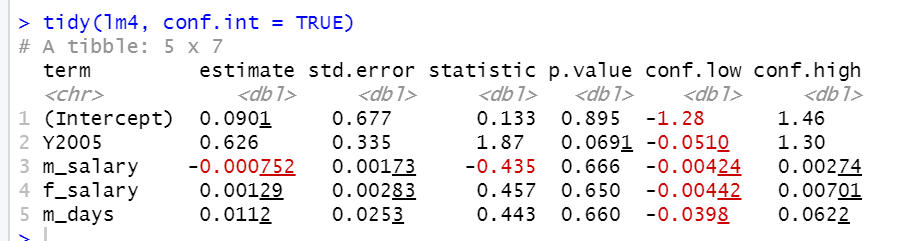
係数の信頼区間がすべて0を含んでいます。
step関数で不要な説明変数を除いてみます。

あら、残った説明変数はY2005: 2005年度の男女の1日当りの所定内給与額の比率 だけでした。p-valueは3.236e-05と0.05よりも低く、Y2005の係数のp値も3.24e-05と0.05よりも低いです。
Y2005の2乗項、3乗項も加えてみたモデルを作ってみましょう。

2乗項、3乗項を加えるのは意味ないようですね。
lm5の残差プロットを見てみます。

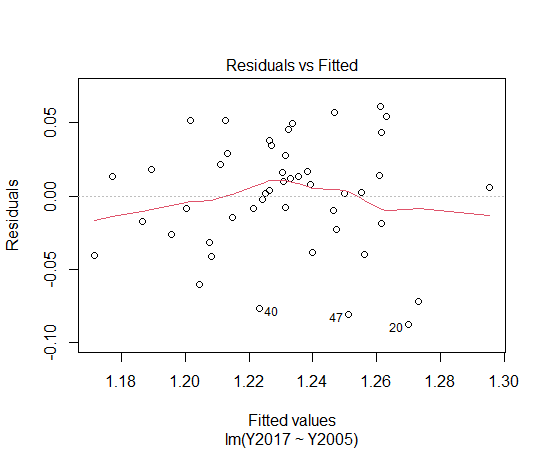
今回は以上です。
はじめから読むには、
です。