
UnsplashのMarjolein vVが撮影した写真
の続きです。
前回はクラスタリング分析をしたのですが、少し気になる結果になりました。
それは、
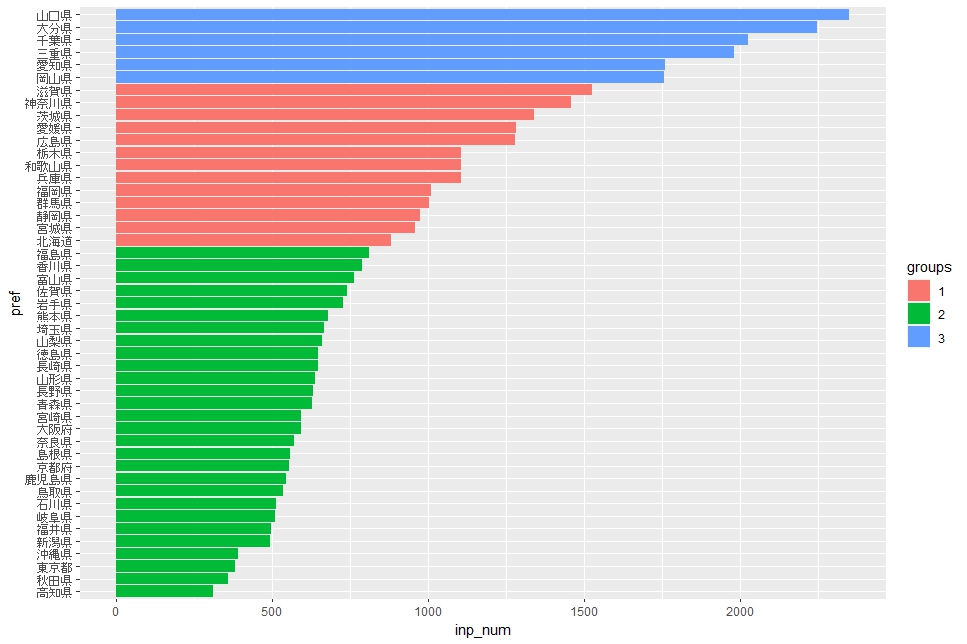
このように、inp_numの値ではっきりとグループが分かれたことです。
考えてみると、クラスタリングする前に変数を標準化していませんでした。
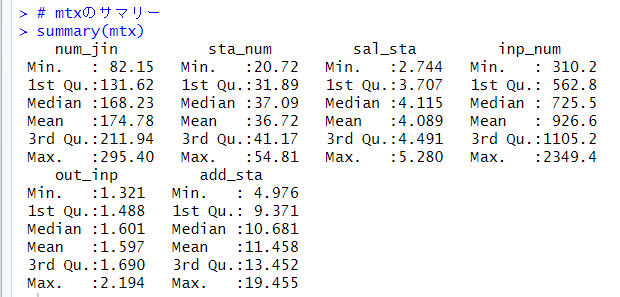
summary()関数で各変数を比べると、上のようにinp_numが突出して値が大きいため、この変数にクラスタリング全体が大きく影響されていたのですね。
そこで、今回は変数を標準化してから同じ手法でクラスタリングをしてみます。
まず、sclae()関数でマトリックスオブジェクトを標準化します。
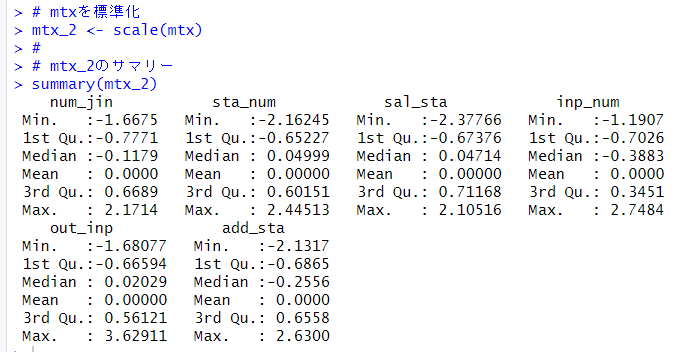
このように、各変数の平均値が0に統一されました。標準偏差は、1になっています。

このように各変数を平均値0、標準偏差1に標準化してからクラスタリングします。

dist()関数で距離を計算して、

hclust()関数でクラスタリング処理します。
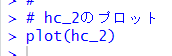
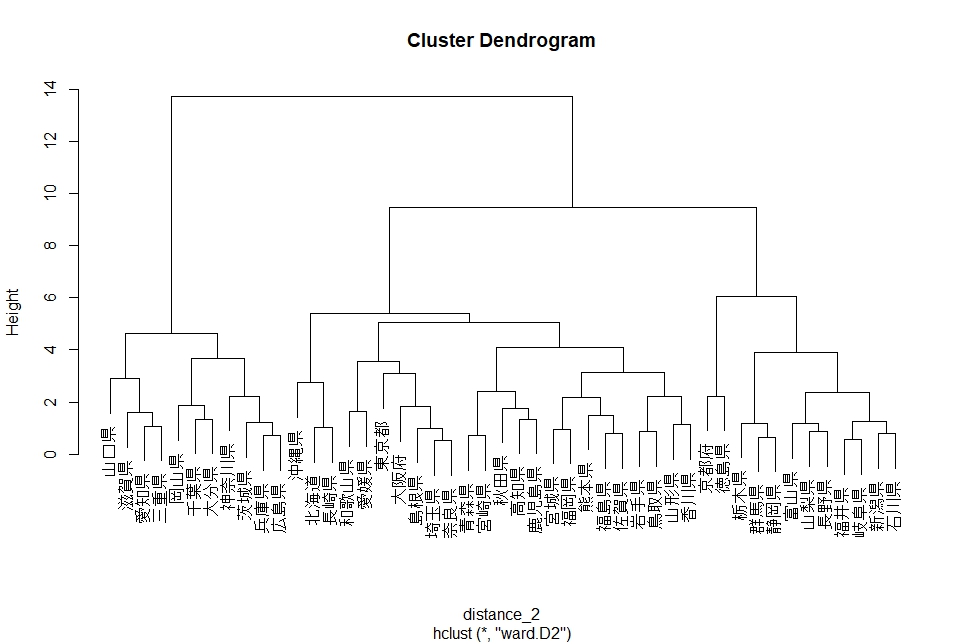
plot()関数で樹形図を描きます。前回のように東京都と沖縄県が隣同士とはなっていないです。

cutree()関数で3つのグループに分けました。

新しいクラスタリングの結果をdfに追加しました。
前回と同じようにグラフにしてみます。

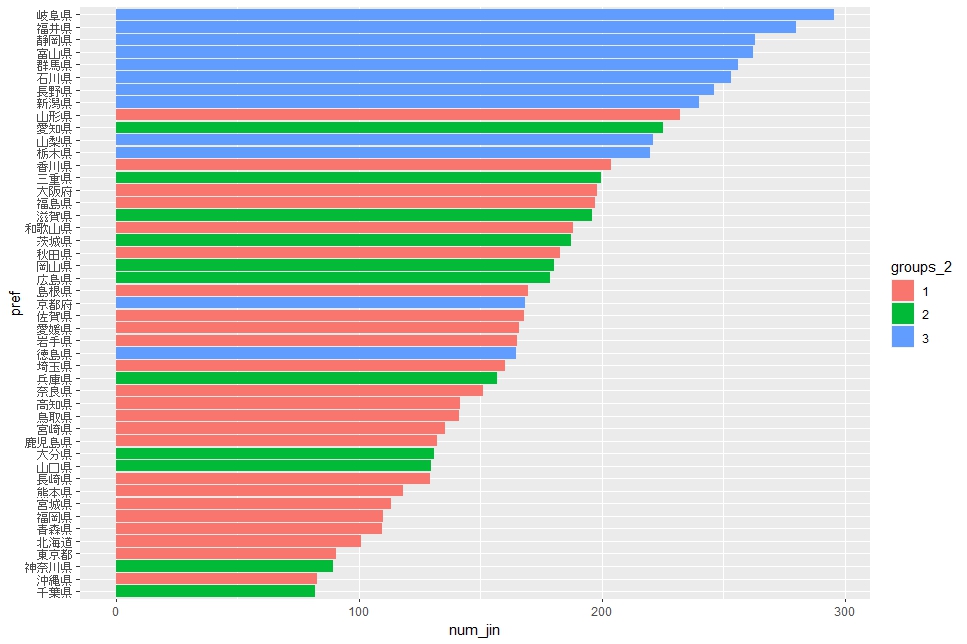
num_jin : 人口当たりの事業所数はグループ3が上位となりました。
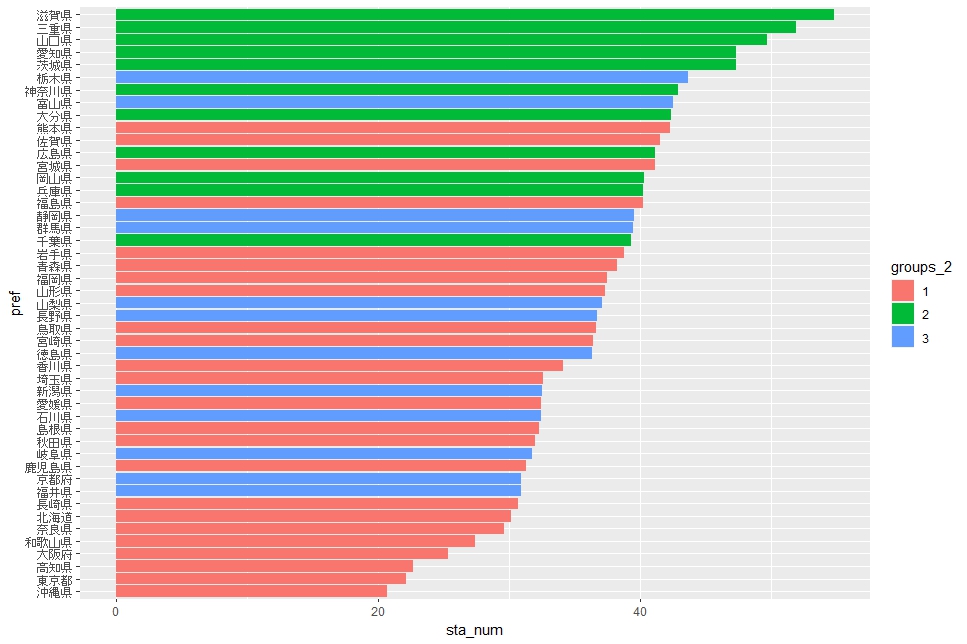
事業所当たりの従業員数は、グループ2が上位で、グループ1が下位です。

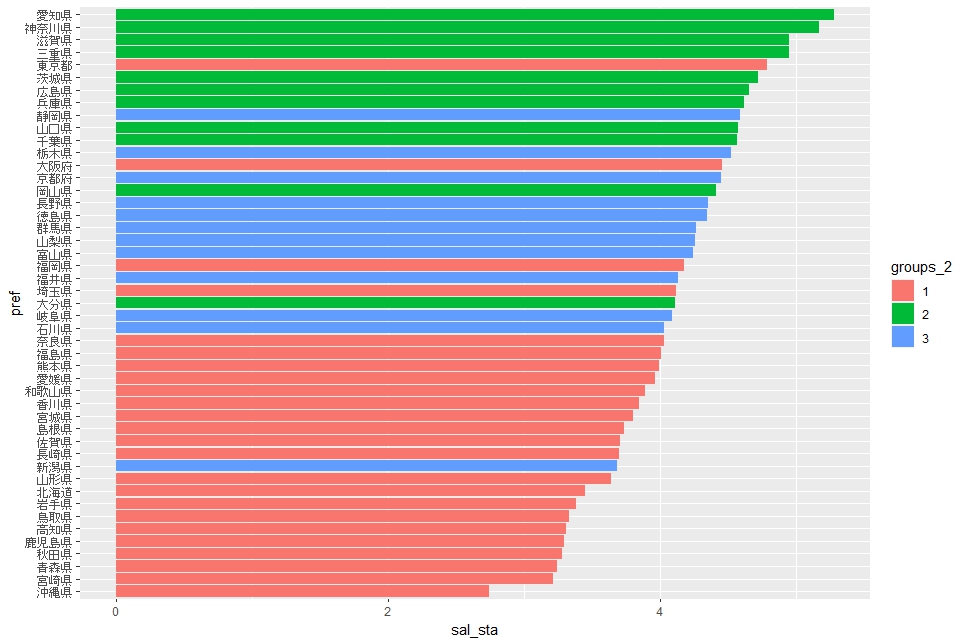
sal_sta : 従業員当りの給与総額はグループ2が上位でグループ1が下位です。

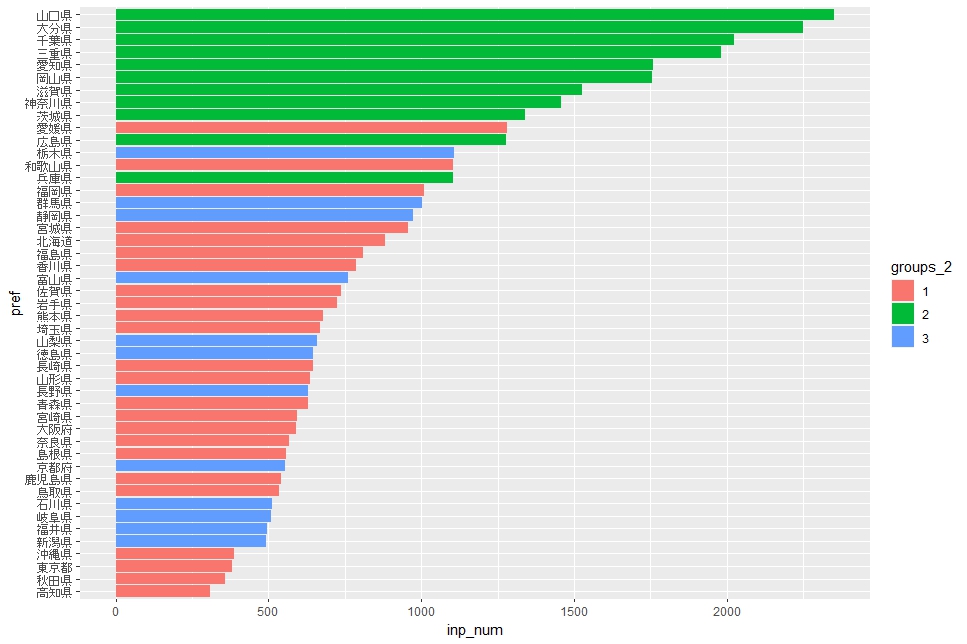
inp_num : 事業所当たりに原材料使用額はグループ2が上位独占です。

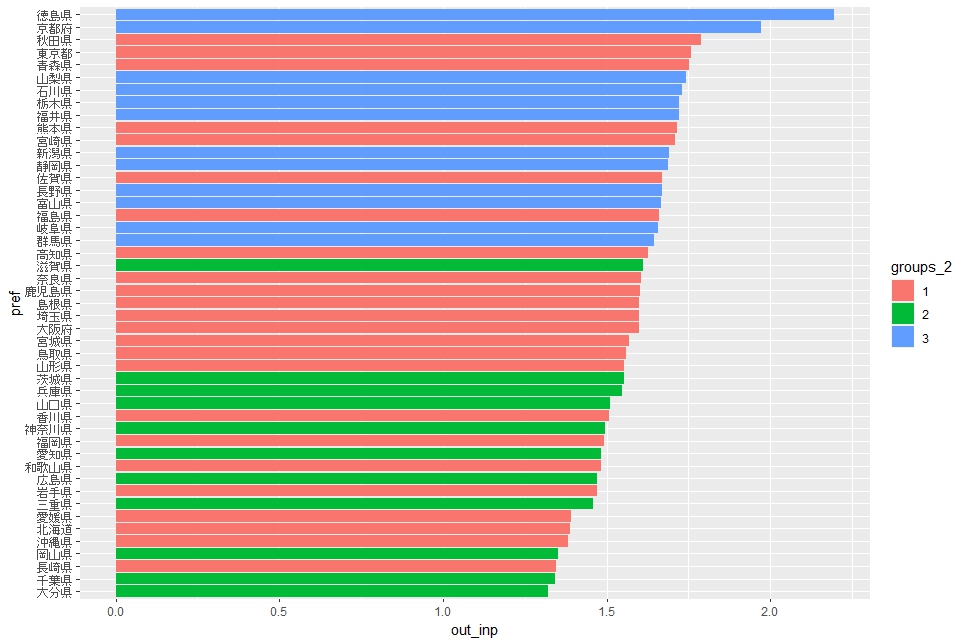
out_inp : 原材料使用額当たりの製造品出荷額はグループ3が上位です。

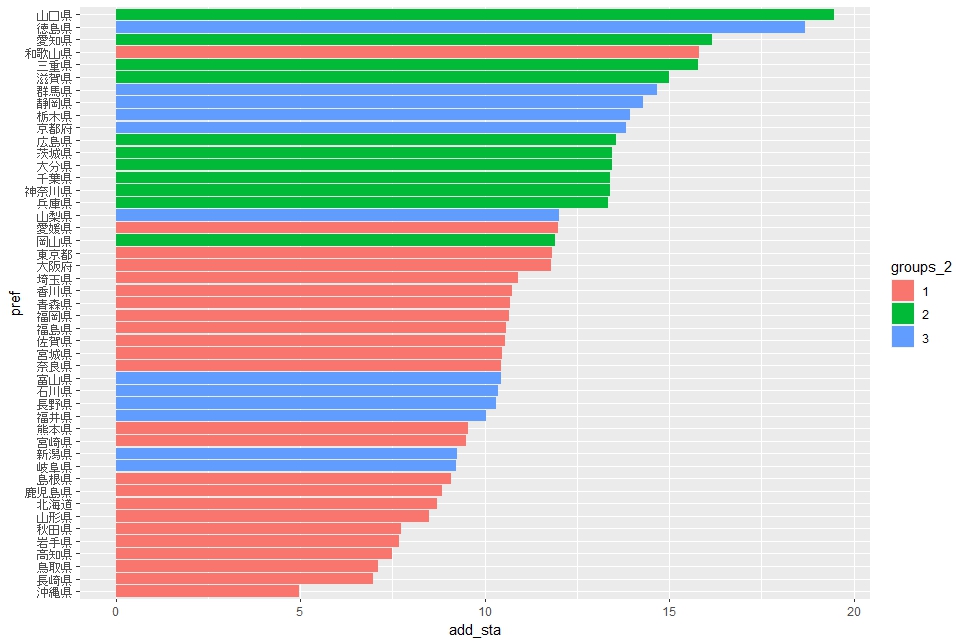
従業員当りの付加価値額はグループ2が上位です。
前回のグループ分けと今回のグループ分けがどのくらい一致、不一致かみてみます。
まず、前回のgroupsをgroups_1にrename()関数で変更します。
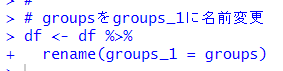
table()関数でgroups_1とgroups_2を比較します。
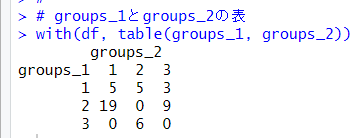
groups_1とgroups_2では違っていることがわかります。
今回は以上です。
次回は、
です。
初めから読むには、
です。