
の続きです。
今回は、クラスタリング分析をしてみます。
まず、クラスタリング分析をするためのマトリックスオブジェクトを作成します。

今回は、num_jin : 人口当たりの事業所の数、sta_num : 事業所当たりの従業員の数、sal_sta : 従業員当りの現金給与総額、inp_num : 事業所当たりの原材料使用額、out_inp ; 原材料使用額当りの製造品出荷額、add_sta : 従業員当たりの付加価値額の6つの変数を使ってクラスタリング分析してみます。
まず、dist()関数で各観測値、この場合は都道府県間の距離を計算します。

47都道府県ありますから、それぞれの距離の組み合わせは、47 * 46 / 2 = 1081 ですね。
この距離オブジェクトをhclust()関数で処理します。

hclust()関数の引数のmethodはいくつか方法がありますが、今回は、ward.D2 : ウォード法(最小分散法)にしてみました。
こうして作成した、hculstオブジェクトは、plot()関数で樹形図になります。
![]()

左の枝を見ると、山口県、大分県、愛知県、岡山県、千葉県、三重県が入っています。規模の大きな工場がメインの県、というイメージですね。
意外だったのが東京都と沖縄県が隣同士に配置されていることです。
この樹形図をもとにして、

このように3つのクラスターに分類してみます。

北海道と宮城県は1で、青森県と岩手県は2ですね。ということは、山口県や大分県は3ですね。
このデータを基のdfに加えます。

それでは、こんどはこのクラスタリングで分類された3つのグループがわかるようにグラフを描いてみます。
まずは、num_jin : 人口当たりの事業所数 です


各グループが分散されていて、特徴的なことはなさそうです。
次は、sta_num : 人口当たりの従業員数です。


2番グループが値が低い傾向がありますね。
次は、sal_sta : 従業員当りの現金給与です。


1番、3番グループが高く、2番グループが低い傾向です。
次は、inp_num : 事業所当たりの原材料使用額です。

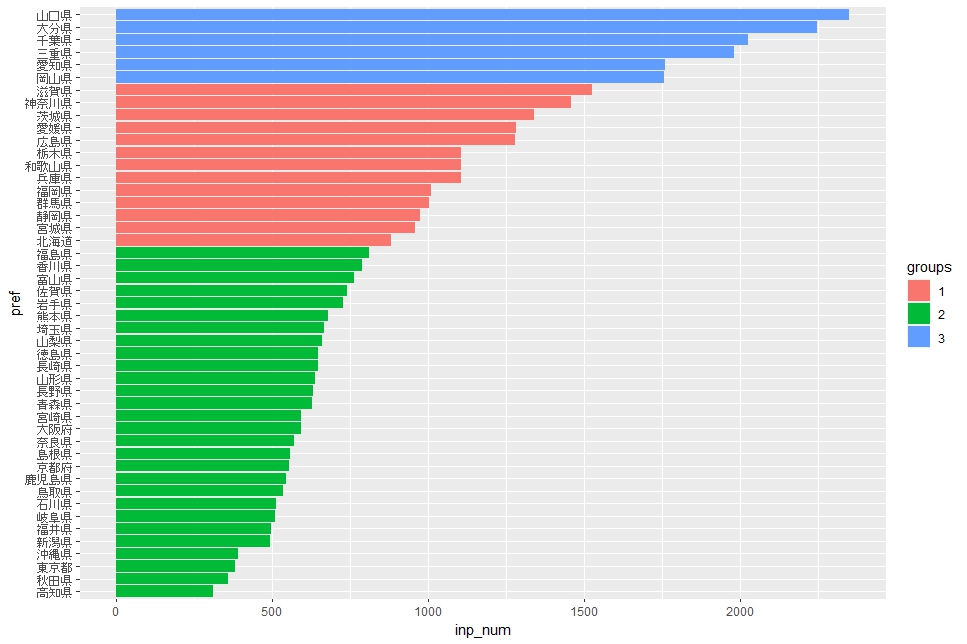
これは! これはハッキリと別れましたね。3番グループが一番の原材料使用額で、2番グループが一番少ないということですね。
次は、out_inp : 原材料使用額当たりの製造品出荷額です。


これは2番グループが値が大きいですね。
次は、add_sta : 従業員当りの付加価値額です。


これは2番グループが値が小さい傾向です。
今回は以上です。
次回は、
です。
初めから読むには、
です。