
Generated by Bing Image Creator:beautiful clear phot of a flower, wisteria, background is Technopolis
の続きです。
前回は、男子と女子では、女子のほうが睡眠時間が短いこと、2001年と2011年では2011年のほうが睡眠時間が短いことがわかりました。
今回は、県民一人当り県内総生産額との関係性をみてみます。
まず、df_longのデータフレームを使って、sleepをgp, year, prefで回帰分析してみましょう。lm()関数を使います。
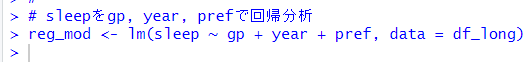
summary()関数を使って結果を見てみます。
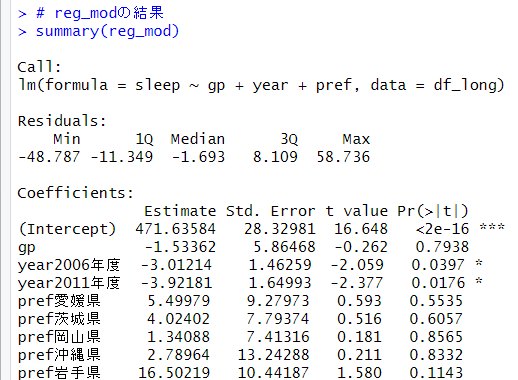
都道府県の係数については省略しました。gp:県民一人当り県内総生産額の係数は-1.53ですが、p値は0.7938と統計的に有意な結果ではありませんでした。yearは2006年も2011年も2001年と比べると有意な違いがあることがわかります。
県民一人当り県内総生産額と一番関連してそうなのは、mw:有業者男子の睡眠時間だと思われますので、df_wideのデータフレームを使って、mwをgpとyearとprefで回帰分析してみましょう。

confint()関数で係数の信頼区間をみてみましょう。
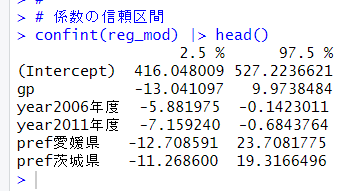
gpの係数の信頼区間は、-13 ~ 10と0を含んでいますので、mwだけに絞ってもgpは有意な関係性は無いようです。
それでは、その反対にgpをmw, year, prefで回帰分析してみたらどうでしょうか?

summary()関数で結果をみてみます。
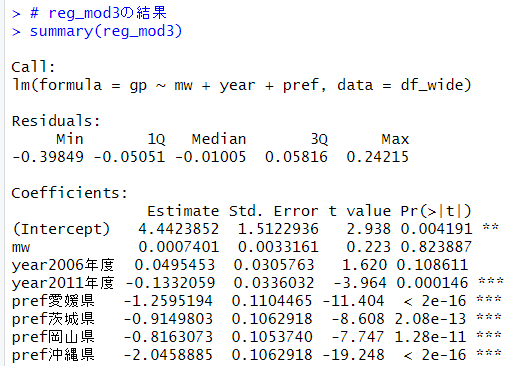
mwは有意な変数では無いようです。2011年度の-0.133という係数は統計的に有意に0とは違います。つまり、2001年度と比べて、2011年度は県民一人当り県内総生産額が減少したことがわかります。
summary()関数でもp-valueやconfint()関数での信頼区間は、公式ベース(理論ベース)の値です。
前回も実行した、inferパッケージを使って、シミュレーションベースのp-valueや信頼区間を求めてみましょう。
まず。observed_fitを計算します。
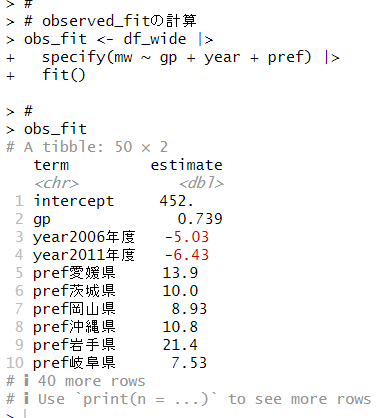
次は、null distributionを生成します。

結果を視覚化してみます。

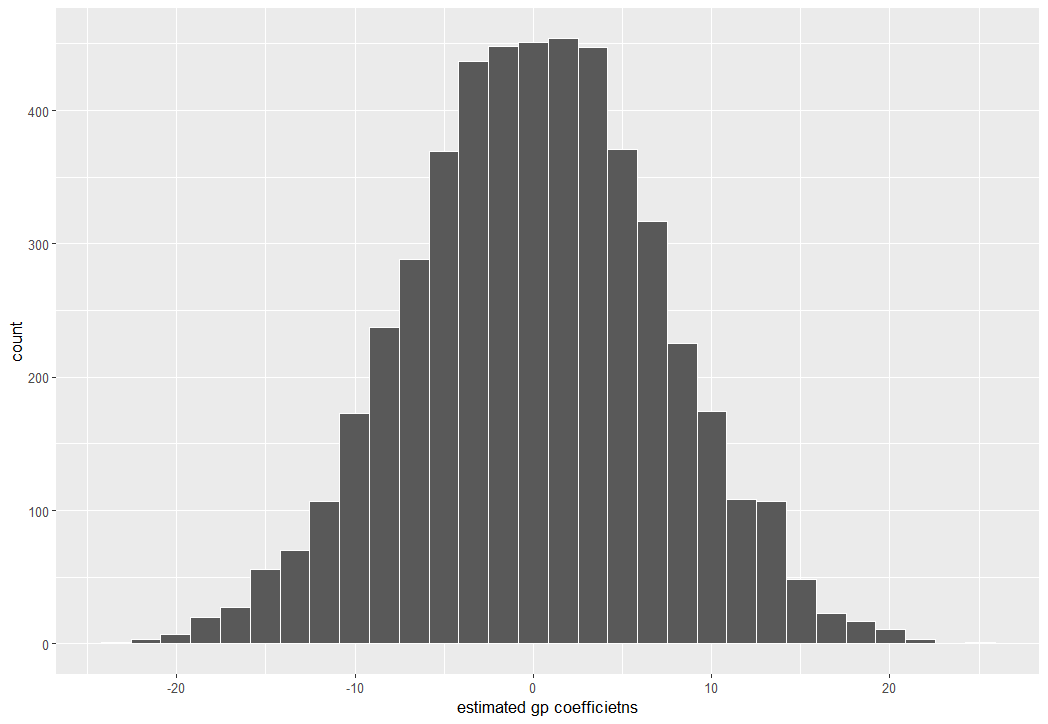
0を中心とした分布となりました。
p-valueを計算してみましょう

公式ベースのp-valueと比較します。
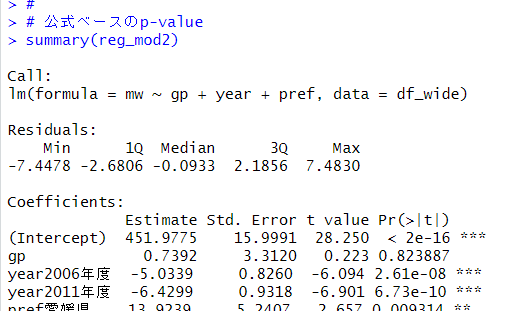
シミュレーションベースのp-valueのほうが大きいですね。
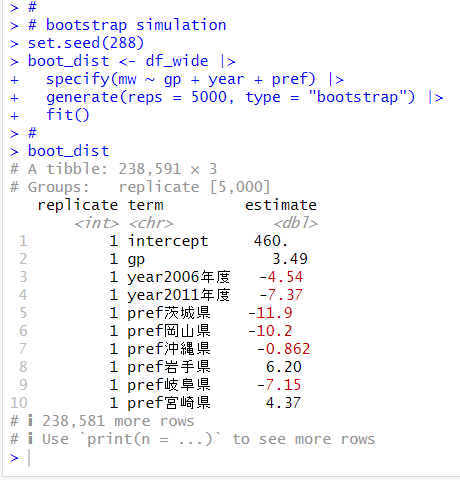
こんどは、シミュレーションベースの信頼区間を求めましょう。
まずは、ブートストラップで係数の分布を生成します。
gpの係数の分布をヒストグラムでみてみます。

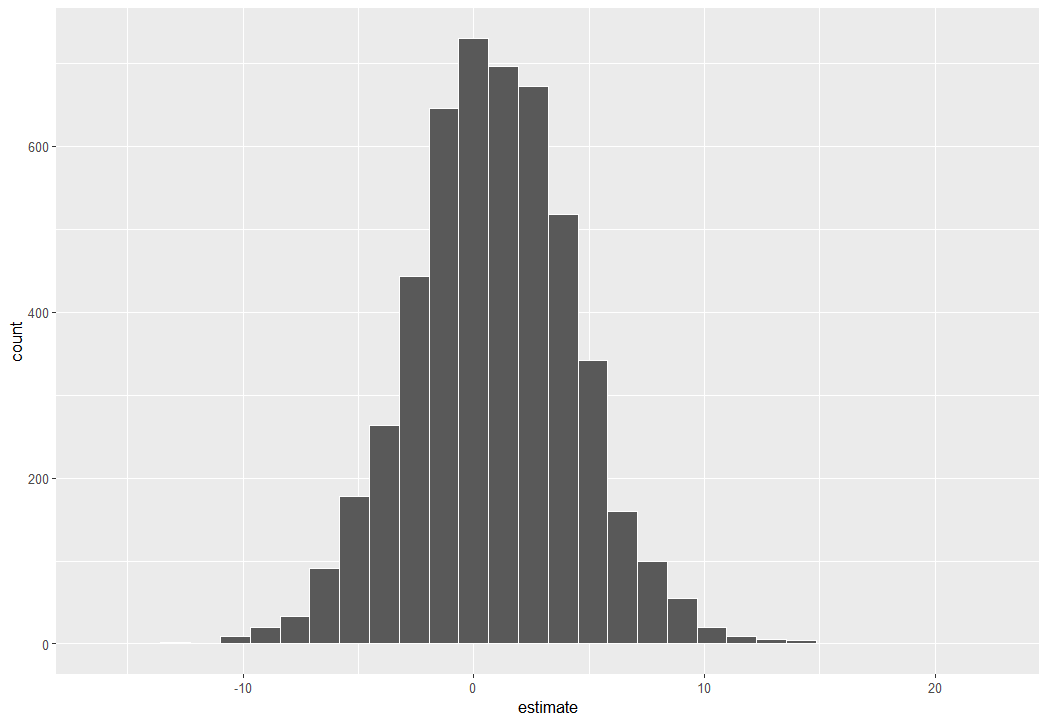
gpの信頼区間を求めてみましょう。
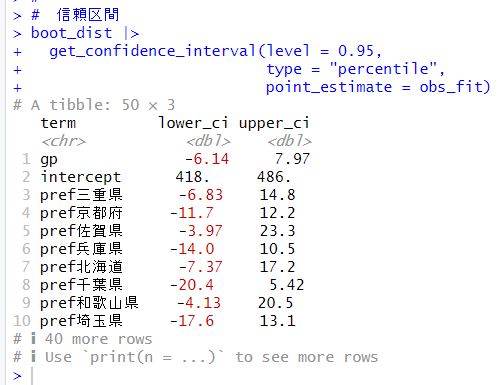
gpの95%信頼区間は-6.14~7.97でした。理論ベースの信頼区間よりも幅が狭いですね。
同じ結果は、get_confidence_interval()を使わずにできます。

いずれにしてもgp:県民一人当り県内総生産額は睡眠時間の平均値とは関係ないようです。
今回は以上です。
はじめから読むにには
です。