
Bing Image Creator で生成: Beautiful early spring nature landscape Japan
今までクロスセクションのデータばかりを扱ってきましたので、今回は時系列データの分析の練習をしてみたいと思います。
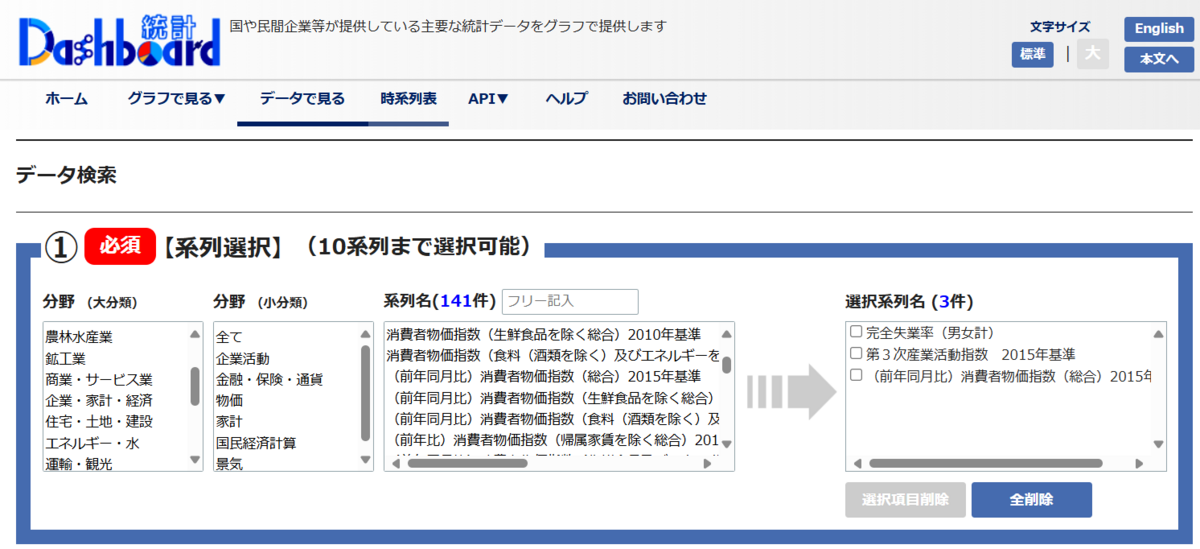
使用するデータは、全国ベースの失業率、第3次産業活動指数、物価の時系列です。
データは統計ダッシュボードのウェブサイトから取得しました。
統計ダッシュボード - データ検索画面 (e-stat.go.jp)
理論的な背景は、
")
R のコードは、

を参考にしています。
ウェブサイトからデータをダウンロードして、変数名を加えたCSVファイルはこんな感じです。
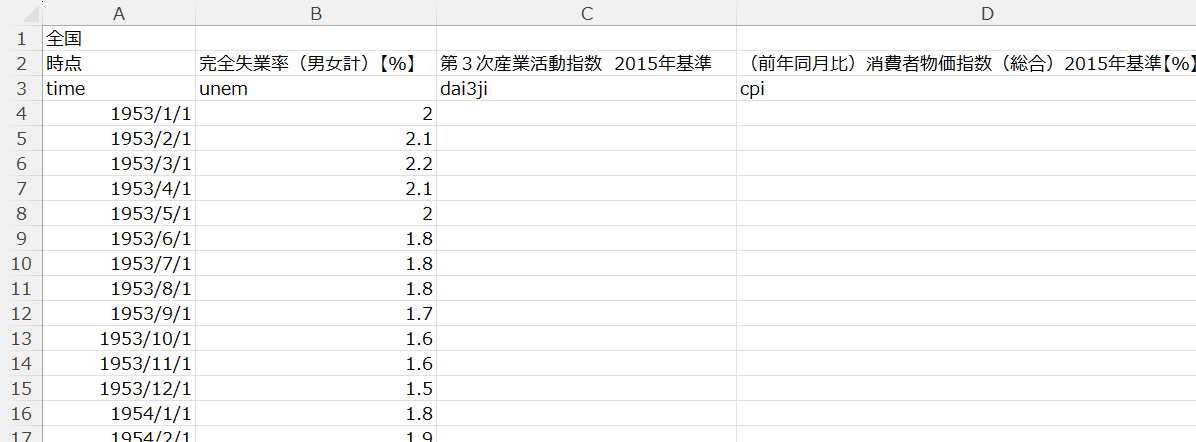
これを R に読み込みます。
はじめに tidyverse パッケージ、lubridate パッケージと dynlm パッケージを読み込んでおきます。
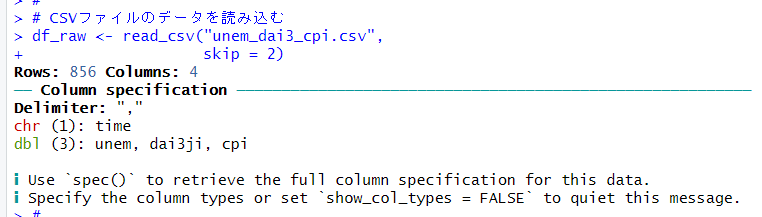
read_csv() 関数で CSVファイルにデータを読み込みます。
glimpse() 関数で、読み込んだデータがどんな様子かみてみます。

time が 文字列型になっているので、これを日付型にするのと、NA がある列をの削除する処理をします。

summary() 関数で df をみてみましょう
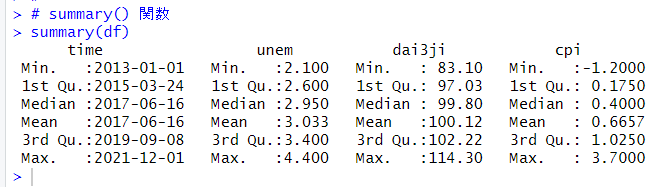
2013年1月から2021年12月までのデータです。
失業率は、最小値は2.1%, 最大値は4.4%, 平均値は3.033% です。
第3次産業活動指数は、最小値は83.10, 最大値は114.30, 平均値は100.12 です。
消費者物価指数の前年同期比は、最小値は -1.2%, 最大値は3.7%, 平均値は0.6657% です。
ts() 関数で ts オブジェクトも作成しておきます。

これで、分析のためのデータフレームオブジェクトの df と、時系列オブジェクトの dts が用意できました。
今回は以上です。
次回は、
です。