の続きです。
今回はデータフレームの構成を作る変えたいと思います。現在のデータフレームは、

このようになっています。
これを、
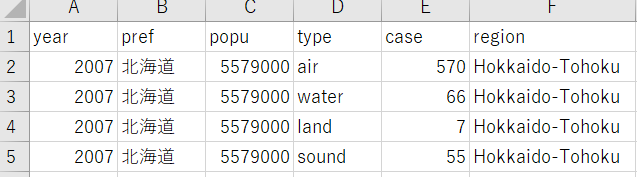
こんな感じにしたいのです。
どうしたらいいのかな。。。
まず、airのデータフレームだけをつくりましょう。
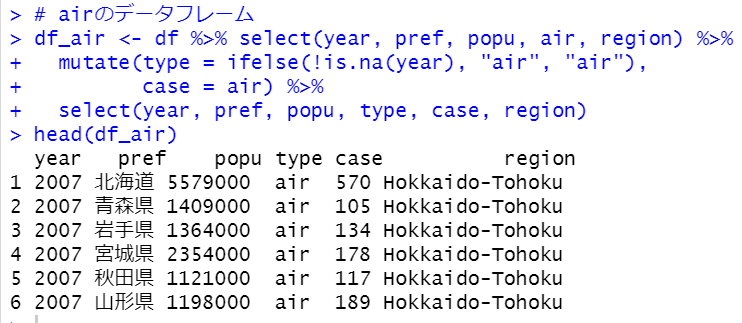
いい感じですね。
同じようにして、warterの他のデータフレームも作ります。
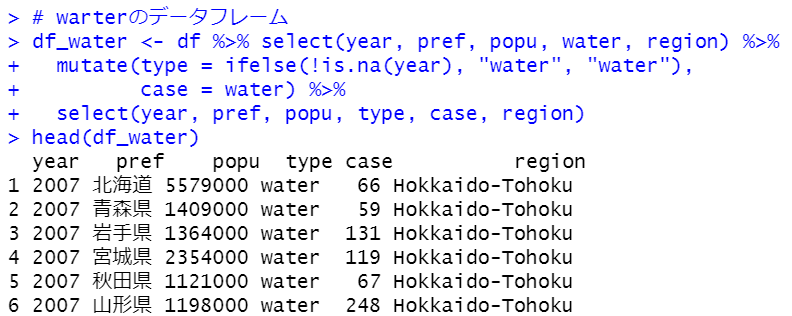
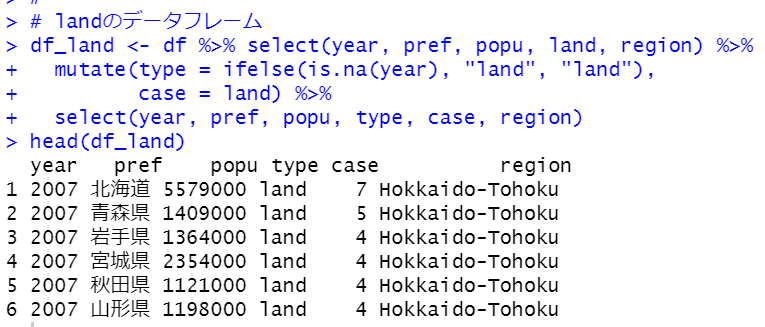
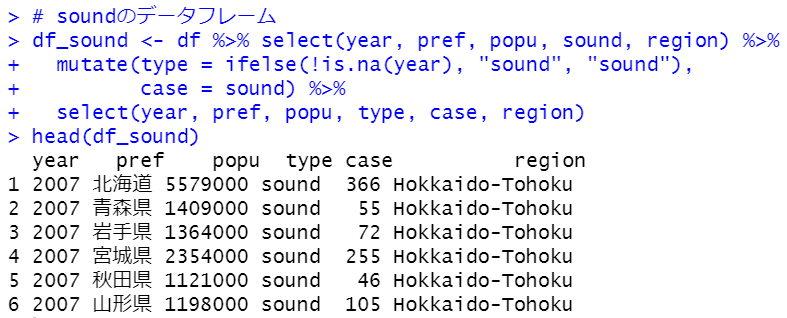


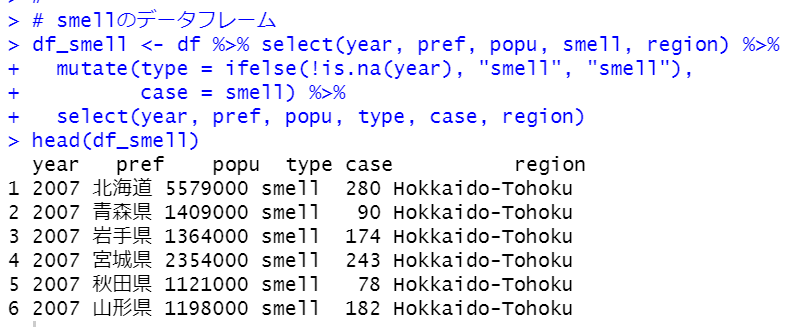
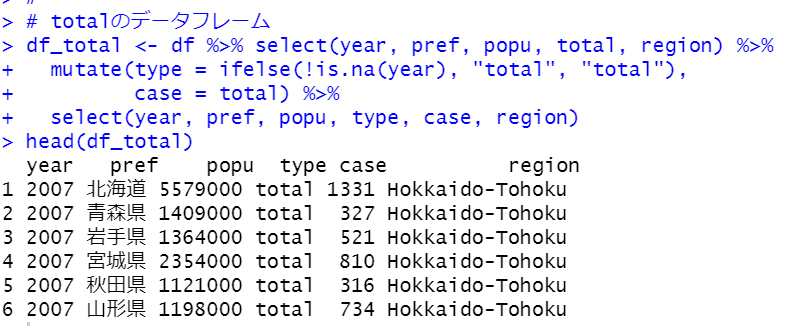
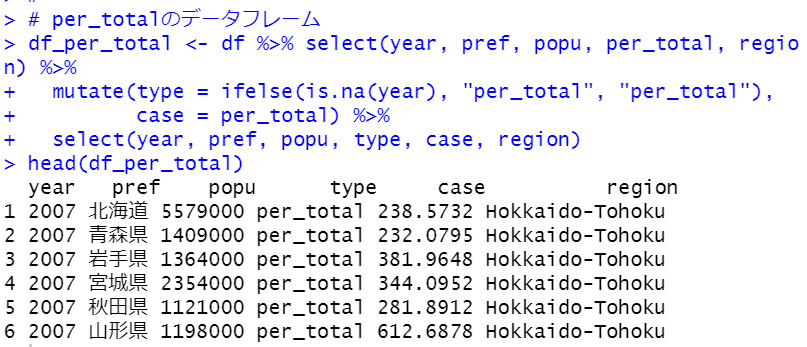
これらのデータフレームをrbind関数で結合すればOKです。
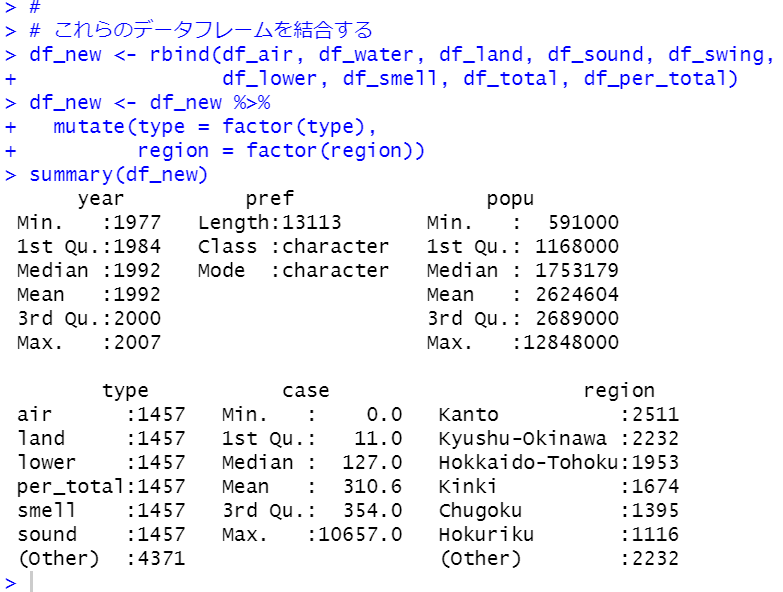
typeとregionをfactor関数で文字列型からファクター型に変換しました。
今回は以上です。
の続きです。
今回はデータフレームの構成を作る変えたいと思います。現在のデータフレームは、
このようになっています。
これを、
こんな感じにしたいのです。
どうしたらいいのかな。。。
まず、airのデータフレームだけをつくりましょう。
いい感じですね。
同じようにして、warterの他のデータフレームも作ります。
これらのデータフレームをrbind関数で結合すればOKです。
typeとregionをfactor関数で文字列型からファクター型に変換しました。
今回は以上です。
の続きです。
今回は、R言語でSlope chartを作ります。
Slope chartは少数のデータの2時点の変化を見るのに便利なチャートです。
今回は、1977年と2007年の2時点で、北海道、宮城県、東京都、愛知県、大阪府、広島県、福岡県の人口100万人当りの苦情件数の変化を見てみましょう。

はじめに上のように、年と都道府県を設定しました。

このように、年は1977年と2007年、都道府県は指定した7都道府県だけ、per_totalがNAでないデータフレーム、datを作りました。
ここからは、
https://rafalab.github.io/dsbook/data-visualization-principles.html#plots-for-two-variables
このサイトを参考にします。
これは、
この本のWebバージョンです。
それはでやってみましょう。
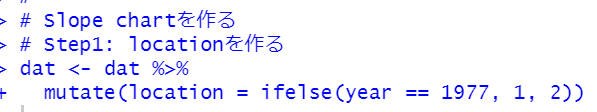
Step1は上のようになります。mutate関数でlocationというX軸の座標を作ります。
1977年だったら1で、そうでなかったら、つまり2007年だったら2です。
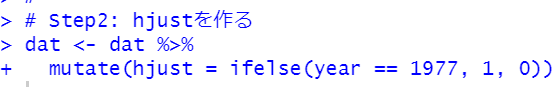
次に、hjustを作ります。1977年だったら1、そうでなかったら、つまり2007年だったら1です。
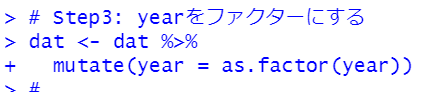
step3では、yearをas.factor関数で数値型からファクター型に変換します。
ここまでで、データフレーム、datの処理は終了しました。
次からは、グラフ作成になります。

Step4ではggplot関数でggplotオブジェクトを作ります。pと名前をつけました。
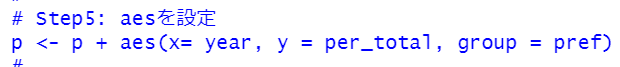
Step5ではaes関数で、X軸をyearに、Y軸をper_totalに、groupをprefに指定しました。

Step5ではgeom_line関数で線グラフを描きます。これでグラフの骨格はできています。ためしに表示してみます。

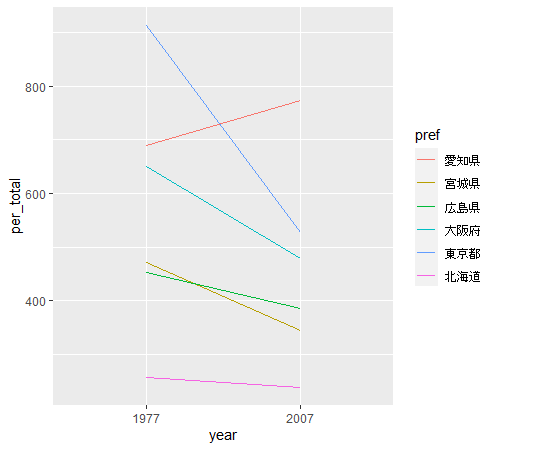
こんな感じです。

Step6では、geom_text()関数でグラフに都道府県名を付けたします。
これも試しに表示してみましょう。

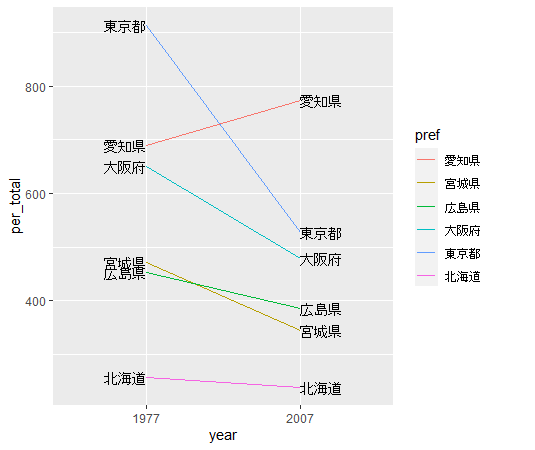
できましたね!愛知県だけ苦情件数が増えていることがわかります!

Step7でY軸ラベルを削除し、ggtitle関数でタイトルをつけで完成です。
表示してみます。

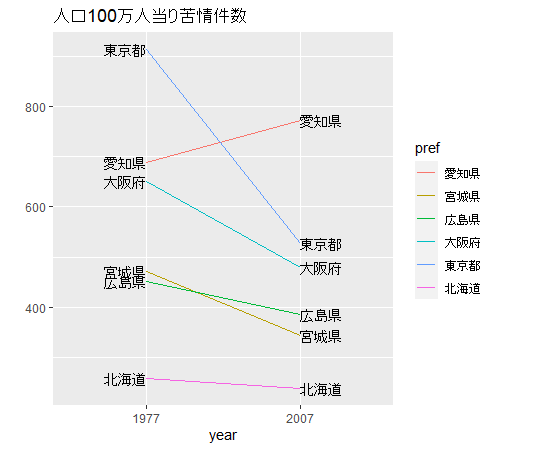
できました!
今回は以上です。
の続きです。
今回は、R言語のdplyrパッケージのcase_when関数を学びましたので、さっそく使ってみたいと思います。
case_when関数はifelse関数の複数バージョンでしょうか?
百聞は一見にしかず。やってみます。
今回は、47の都道府県をe-stat(政府統計の総合窓口)の地方類型Iの基準でわけてみようと思います。

北海道と東北は一つに、九州と沖縄も一つにしてみます。
まずは、それぞれの地方を表すベクトルを作ります。

こうして各地方を表すベクトルを作ったら、case_when関数でファクターを作ります。

これで47都道府県が各地方に割り当てられました。
2007年の人口100万人当りの苦情件数を各地方ごとに箱ひげ図であらわしてみましょう。


このように地方別の苦情件数の箱ひげ図になります。
北海道・東北地方は少なくて、東海地方は多いとわかります。
最後にreorder関数を使って、中央値の小さい順にregionを並び替えてから箱ひげ図を描いてみます。


reorder(region, per_total, FUN = median)はregionをper_totalの中央値の順番に並び替える、ということです。
今回は以上です。
の続きです。
今回は1977年と2007年の苦情件数の分布を比較してみましょう。
R言語のggplot2パッケージのgeom_histogram関数とfacet_grid関数を使います。


1977年に比べると、2007年のほうが左に移動しています。
これは有意に違っているのでしょうか?検定してみましょう。
まずは、1977年だけ、2007年だけの人口100万人当りの苦情件数のベクトルを作ります。

var.test関数でvec1977(1977年の人口100万人当りの苦情件数)とvec2007(2007年の人口100万人当りの苦情件数)のvarianceが同じかどうかを検定します。

p-valueは0.1337と0.05よりも大きいですから、帰無仮説:2つのvarianceは同じを棄却できません。つまりvec1977とvec2007は同じ分散とみなしても問題ありません。
分散が同じなので、t.test関数で平均値が同じかどうかを検定します。

p-valueが0.5789なので、0.05よりも大きいので、vec1977とvec2007の平均値は有意な違いがあるとは言えません。 となりますがこれは間違った検定方法ですね。
というのは、1977年と2007年で同じ47都道府県で比較していますから、対応のある検定にしないといけないです。

このように、arrange(pref)を途中で入れて、都道府県で並び替えてからベクトルにしています。
これで、t.test関数をpaired = TRUEを加えて検定します。

p-valueが0.4149ですから、0.05よりも大きいです。つまり、vec1977とvec2007では平均値に違いがあるとは言えない、ということです。
今回は以上です
今回はどこの都道府県が公害苦情件数が多いか、少ないかを調べてみましょう。
一番新しい年を確認します。

2007年が最新ですね。この年の人口100万人当りの苦情件数を見てみます。
dplyrパッケージの中のfilter関数、select関数とarrange関数、それとhead関数を使います。

filter関数で2007年だけのデータにして、
select関数で、prefとper_totalだけを選択して、
arrange関数でper_totalの小さい順に並び替えて、
head関数で10の都道府県だけを表示しています。
熊本県が一番少ないです。
大きい順に並び替えたいときは、desc(変数)とします。

三重県が一番多いです。東京都や大阪府は上位10には入っていないです。
ちょっと意外でした。
一番古い年でも見てみましょう。

1977年が一番古い年です。
この年の苦情件数の一番少ない都道府県はどこでしょうか?

島根県が一番少ないです。鳥取県が2番目です。山陰地方が少ないです。
苦情件数の多い都道府県はどこでしょうか?

東京都が一番おおく、三重県が二番目です。高知県、愛媛県、徳島県と四国の県が3つもあるのが印象的です。
今回は以上です。
の続きです。
今回は時系列のグラフをR言語で描いてみます。
はじめにtidyverseパッケージを読み込みます。
東京都の苦情件数の合計をグラフにしてみましょう。

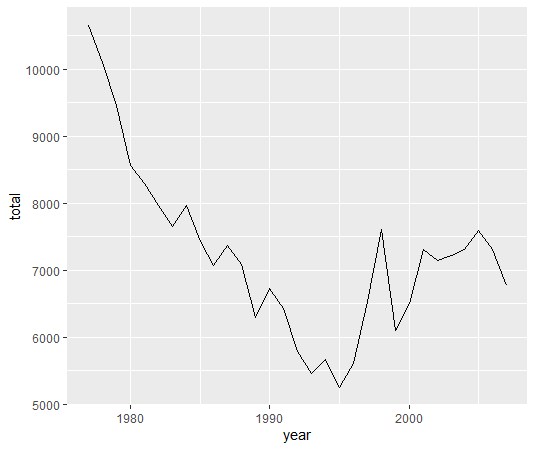
1995年までは低下傾向でしたが、そこからまた増えてきています。
東京都と大阪を比較してみます。

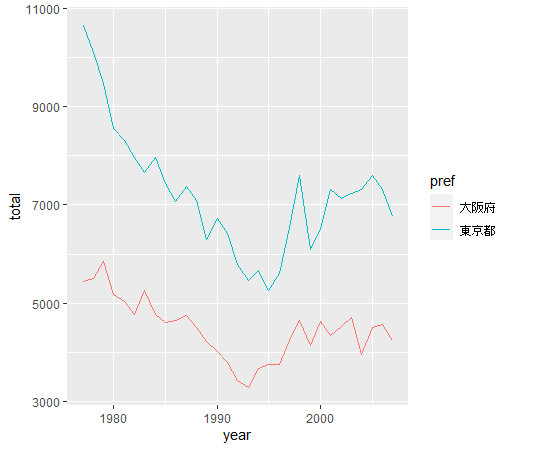
件数の水準に違いはありますが、トレンドは同じですね。
人口100万人当りの苦情件数をグラフにしてみましょう。
はじめに、全体の苦情件数をtotal, 人口100万人当りの苦情件数をper_totalと名前をつけて変数として保存してしまいましょう。
mutate関数を使います。
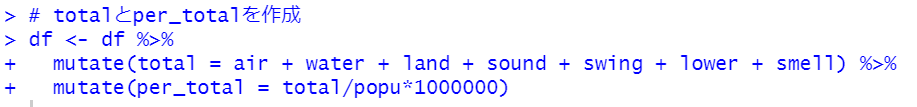
totalとper_totalをsummary関数で確認しましょう。
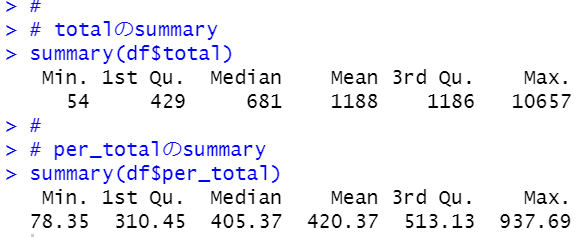
totalは最小は54, 最大は10657, 中央値は681, 平均値は1188です。
人口100万人当りの件数、per_totalは最小値は78, 最大は937, 中央値は405, 平均値は420です。
それでは、東京都と大阪府のper_totalをグラフにしてみましょう。

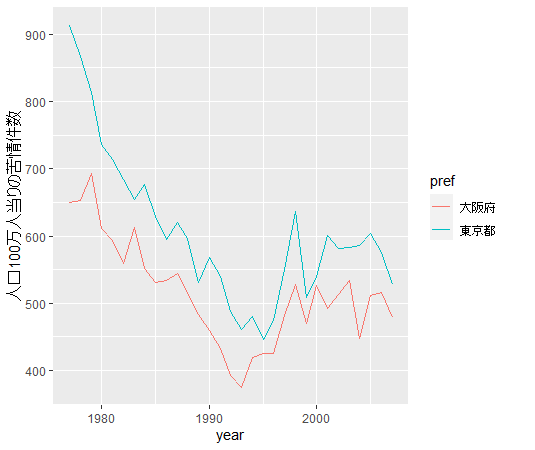
東京都のほうが多いですね。
今回は以上です。
今回は、都道府県別の公害苦情件数のデータを分析してみようと思います。
データは、政府統計の総合窓口、e-statから取得しました。
www.e-stat.go.jp

データのファイルはこんな感じです。

9行目は私が変数名として追加しています。
このファイルをR言語のread.csv関数で読み込みます。

skip = 8 としています。これは8行はとばして、9行目からデータを読み込むという意味です。
na.strings = c("***", "-", "X") は***, -, X はNAとして読み込みなさい、という意味です。
encoding = "UTF-8" はこのファイルのエンコードがUTF-8なのでそのように指定しています。よくわかりませんが、これを入れないと文字化けして読み込んでいました。
str関数で読み込まれたどうか確認します。

うまく読み込んだようです。
yearが2007年度となって文字列型になっていますので、数値型に変換してみましょう。
どうすればいいでしょうか?
substr関数ではじめの4文字だけを抜き出しましょう。

"2007", "2007"と””がついています。これは、文字列型だということです。
as.numeric関数で数値に変換します。

summary関数でyearを見てみると、最小値、最大値などが表示されていて、数値型に変換されていることがわかります。1977年から2007年までの30年間のデータです。
2007年というと今から13年前ですね。それ以降は統計を取っていないのでしょうか?
今回は以上です。
")