の続きです。
今回は、R言語のggplot2パッケージのgeom_point関数で散布図を描きます。


7月の価格と6月の価格なので、ほぼ一直線上に並んでいます。軸のスケールを対数にします。scale_x_log10()とscale_y_log10を使います。


こちらのほうがわかりやすいですね。
Month_chgとYear_chgの散布図を描いてみましょう。


これも軸を対数変換しましょう。


あまりかわらない感じですが、特に傾向は無いようですね。
今回は以上です。
の続きです。
今回は、R言語のggplot2パッケージのgeom_point関数で散布図を描きます。
7月の価格と6月の価格なので、ほぼ一直線上に並んでいます。軸のスケールを対数にします。scale_x_log10()とscale_y_log10を使います。
こちらのほうがわかりやすいですね。
Month_chgとYear_chgの散布図を描いてみましょう。
これも軸を対数変換しましょう。
あまりかわらない感じですが、特に傾向は無いようですね。
今回は以上です。
の続きです。
今回は各変数のヒストグラムを見てみようと思います。ggplot2パッケージの中のgeom_histogram()関数を利用します。


ほとんどの品目は低下価格ですが、6つの品目が高額なため、よくわからないヒストグラムになっています。
dplyrパッケージのarrange関数で高額な品目とその価格を見てみましょう。

ピアノが72万6000円で、ピアノの次が自動車保険料の7万4330円です。自動車保険ってこんなに高いいんですね。自動車に乗らないからわからなかったです。
filter関数でピアノや自動車を除いてから、もう一度ヒストグラムを作ってみます。


だいぶわかりやすくなりました。3万円以下の商品だけにしてヒストグラムを作ってみましょう。


こうしてみると、値段の安いものになるほど、品目が多いですね。
Y202007を対数変換してからヒストグラムを描いてみましょう。mutate関数とlog関数を使います。


ようやく分布の中心に多くの品目が集まるようになりました。
binwidth = 1にしてみます。


color = "white" にして見やすくしました。
Y202006も同じようにヒストグラムにします。


2020年7月とほとんど同じですね。
Y201907も同じようにヒストグラムにします。


こちらも同じような形状です。
続いて、価格の変化率、Month_chgを見てみます。


価格の変化が無い、1.0が圧倒的に多いことがわかります。
Year_chgを見ましょう。


右がわにポツンとあるのは確か、銀行振り込み料金でした。
これを除いてヒストグラムを描いてみましょう。


少しだけ価格が上昇している品目が多いです。
今回は以上です。
の続きです。
今回はR言語のdplyrパッケージのarrange関数でデータを並びかえてみようと思います。
Y202007の小さいものを見てみます。

通信料(IP電話, 通信料)が8.80円で一番安いです。
arrange関数は小さい順に並び替えます。大きい順に並び替えたいときは、desc関数をarrange関数の中で使います。

さきほどはselect関数でItemとY202007を選択したときに、Itemを先に選択したので、出力結果が少し見にくいかたちでした。今回はselect関数でY202007を先に選択したので見やすくなっています。乗用車(普通乗用車, 輸入品)が355万9172円で一番高い品目です。

月刊誌と宿泊料(1泊2食, 平日)の2品目だけが6月と比べて値段が下がっています。
値段が上がっているのは何でしょうか?

レンタカー料金(北海道)が一番値上がりしています。6月と比べて3割も値上がりしています。航空運賃、鉄道運賃が値上がりしています。
1年前との比較はどうでしょうか?

宿泊料(1泊朝食, 休前日)が一番値下がりしています。2割ぐらいです。自動車保険も値段が下がっています。

振込手数料が一番値上がりしています。4.59ってすごいですよね。あとは鉄道運賃です。
振込手数料、気になるので値段を見てみましょう。

filter関数を使いました。2019年7月は54円だったのが、2020年7月は248円になっています。
今回は以上です。
の続きです。
今回は、R言語のdplyrパッケージのmutate関数で新しい変数を作ります。
はじめにtidyverseパッケージを読み込みます。

tidyverseパッケージを読み込むと、dplyrパッケージをはじめggplot2などデータ分析で便利なパッケージをいっぺんに読み込みます。
では、mutate関数でY202007 / Y202006 を作ります。これは2020年6月と2020年7月なので、Month_chgと名前をつけましょう。

Month_chg:前月変化率は最小で0.9615ですから4%ぐらい価格が下がったものがあります。その一方で、最大が1.312なので3割も値上がりした品目があります。
同じように、Y202007 / Y201907 を作ります。これはYear_chgと名前をつけましょう。
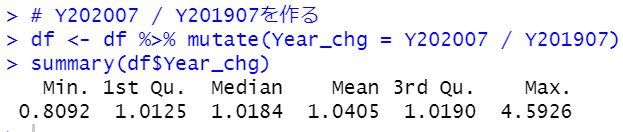
最小値は0.8092ですから2割ぐらい値下がりした品目があります。最大値は4.5926ですから、4.5倍に値上がりした品目もあるのですね。
Month_chgが1.000つまり前月の価格が同じだったらTrue, 価格が変わっていたらFalseという変数も作りましょう。これはMonth_sameと名前をつけましょう。

TRUEが109ということは、109品目は前月と同じ価格、FALSEが29ということは29品目は前月と違う価格ということです。
同じように、Year_chgが1.000ならTRUE, 違うならFALSEというYear_sameという変数を作りましょう。

TRUEが12ですので、12品目は昨年と価格が同じということですね。
最後にMonth_chg, Year_chgが両方ともTRUE, つまり価格が2019年7月、2020年6月、2020年7月で価格が変わっていないものをTRUE, そうでないものをFALSEとする変数を作りましょう、Anteiと名前をつけましょう。

TRUEが12ということは、Year_sameと同じ数なので、Year_sameがTRUEな品目12品目はすべてAnteiもTRUEということですね。Anteiは作らなくてもよかったですね。
NULLで削除しましょう。

str関数でみると、Anteiが無くなっていることが確認できます。
今回は以上です。
今回は、小売物価統計調査のデータから、全国統一価格品目のデータを分析してみようと思います。
政府統計の藏合窓口、www.e-stat.go.jpからデータファイルをダウンロードします。

ファイルをダウンロードすると、このようなファイルです。

必要な部分だけを抜き出しました。

これを、R言語のread.csvファイルで読み込みます。

str関数でファイルが読み込まれたかどうか確認します。

問題がいくつかあります。
Codeの変数名がX.U.FEFF.Codeになっています。それと価格の変数、Y202007, Y202006, Y201907が数値型でなくて文字列になっています。
直しましょう。
まずは、変数名の修正です。names関数で直します。

なおりました。
次に、Y202007, Y202006, Y201907をas.numeric関数で数値型に直します。

数値型になりました。
次に、Y202007, Y202006, Y201907にデータが入っていない、つまりNAな品目は削除します。is.na関数と!を組み合わせます。

summary関数でNAがなくなっていることがわかります。ただ、Y201907の最小値が0というのがあります。価格が0では分析できないので、この行も削除します。

Revise、これは価格改定です。価格改定があるとデータの連続性に疑義がありますから、ReviseがNAのものだけにします。

分析に必要な項目だけにします。Item, Y202007, Y202006, Y201907だけにします。

これで前処理は終わりました。
今回は以上です。
の続きです。
今回はggplot2でグラフを描く練習をします。
はじめにggplot2ライブラリを読み込みます。

続いて、ggplot関数でggplotオブジェクトを作ります。


この時点ではデータフレームを指定しただけなので、グラフには何も表示されません。
X軸とY軸をaes関数で指定します。

X軸とY軸が表示されました。
geom_~~~~関数でグラフの種類を指定します。散布図はgeom_point関数です。

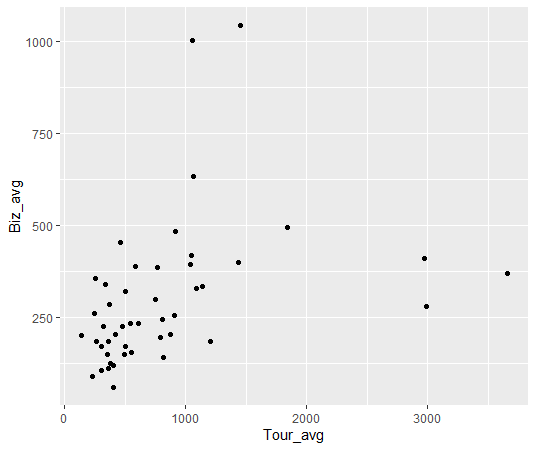
Stpe1からStep3を一度にすると以下のようになります。

geom_pointをgeom_density2dにすると、2次元のdinsity plotになります。
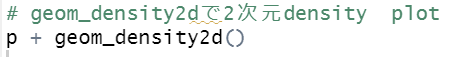
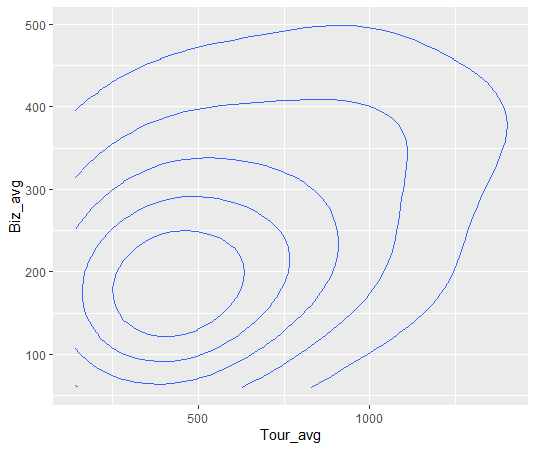
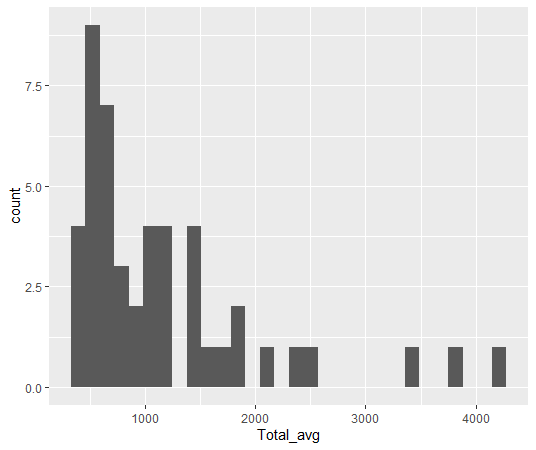
aes関数でY軸を指定しないで、X軸だけ指定すると、geom_histogram関数でヒストグラム、geom_densityでdensity plotを描くことができます。

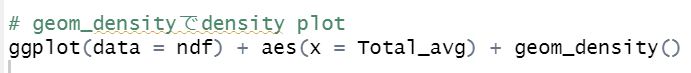
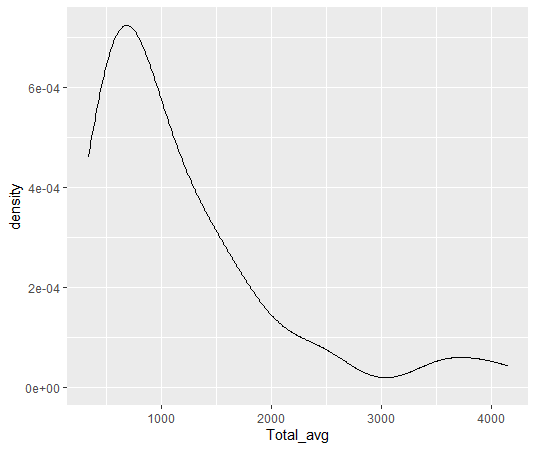
geom_boxplot関数で箱ひげ図です。
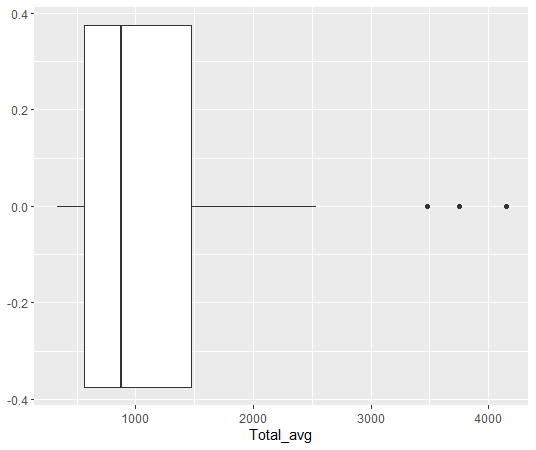
今回は以上です。
の続きです。
今回は、R言語のlm関数で回帰分析をしてみようと思います。
response variable(反応変数)をTotal_chgにしてその他の変数をexplanatory variables(説明変数)にします。

p-valueは2.2e-16よりも小さな係数ですが、各項のp値が大きいですね。
update関数で単純化します。

update関数で、Tour_chg:Biz_chg:Tour_Biz_Ratioの項を削除しました。
anova関数でmodel1とmodel2を比較しました。p値は0.1858と0.05よりも大きいですので、model1とmodel2では有意な違いはありません。より単純なmodel2を採用します。

Biz_chg:Tour_Biz_Ratioは削除してもよさそうです。update関数で削除します。

P値が0.4481ですからmodel2とmodel3では有意な差はありません。
より単純なmodel3を採用します。

もう削除はできないです。
もうひとつ、交差項の無いモデルを作ってみます。

こちらもp-valueは2.2e-16より小さいの有意なモデルです。Adjusted R-squaredは0.8663です。
Total_chg = 0.182 + 0.534 x Tour_chg + 0.253 x Biz_chg + 0.015 x Tour_Biz_Ratioです。
残差プロットを見てみましょう。


左上のグラフが残差プロットですが、特に明確なパターンを形成しているようには見えないので大丈夫です。
多重共線性(Multocollinearity)があるかどうか調べます。carパッケージを読み込んで、vif関数で調べます。


どの変数も2以下、ほとんど1に近いので多重共線性の問題はありません。
交差項を含んだモデル、model3でVIFを計算してみます。

どの変数も10以上なので、よくないです。多重共線性があります。
今回は以上です。