
UnsplashのAlex Personが撮影した写真
の続きです。
前回行ったクラスタリングの結果をデータフレーム、dfにくっつけます。
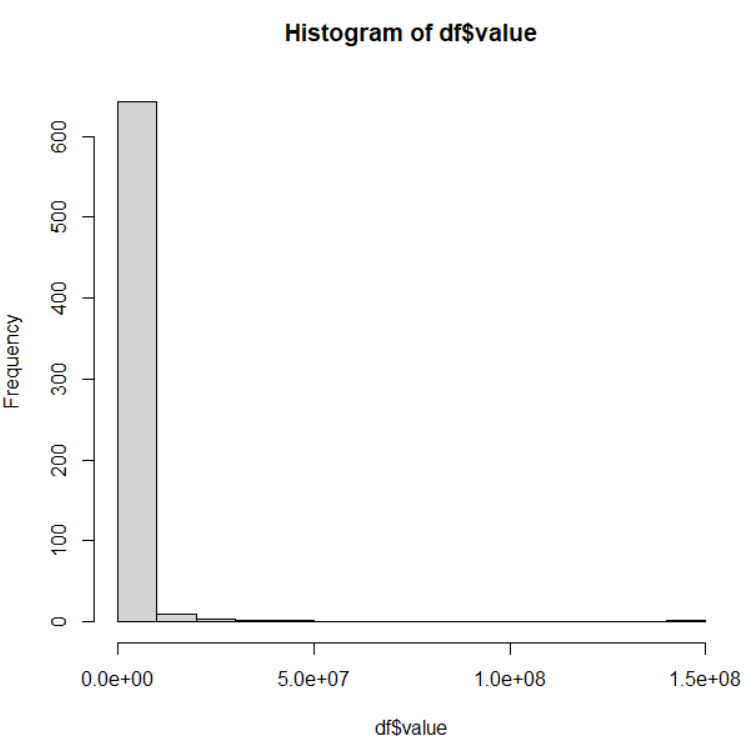
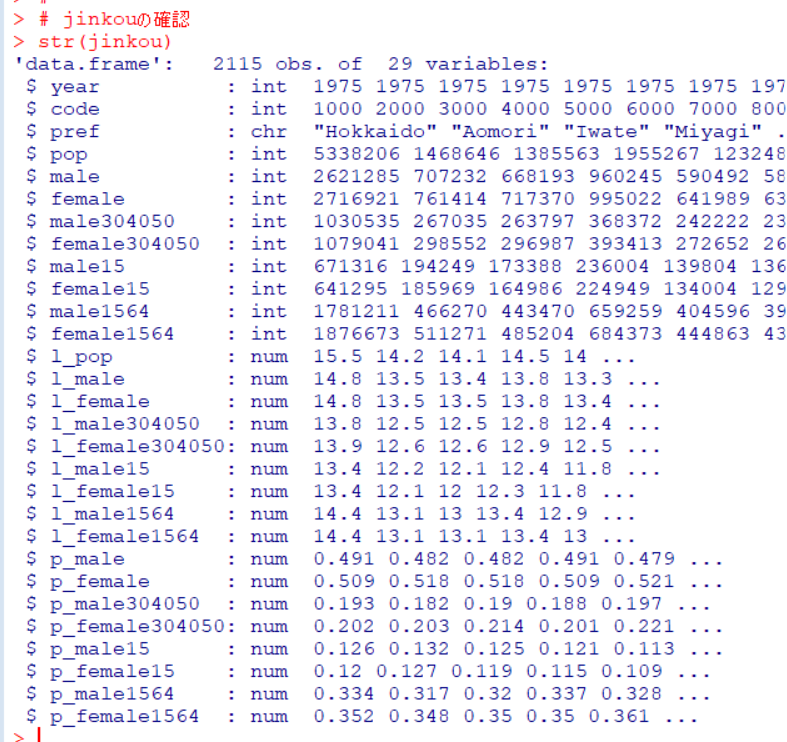
まず、dfがどんなものだったか、str()関数で確認します。

これにクラスタリングの結果をくっつけたいので、まず、tidyverseパッケージを読み込みます。

inner_join()関数をつかってくっつけます。

str()関数で確認します。

一番下にgroupが追加されていることがわかります。
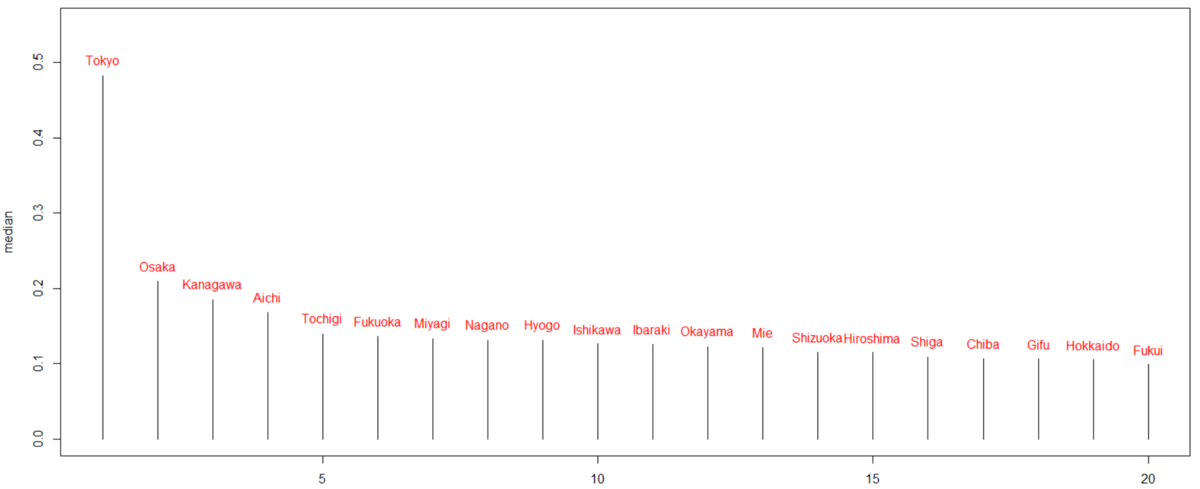
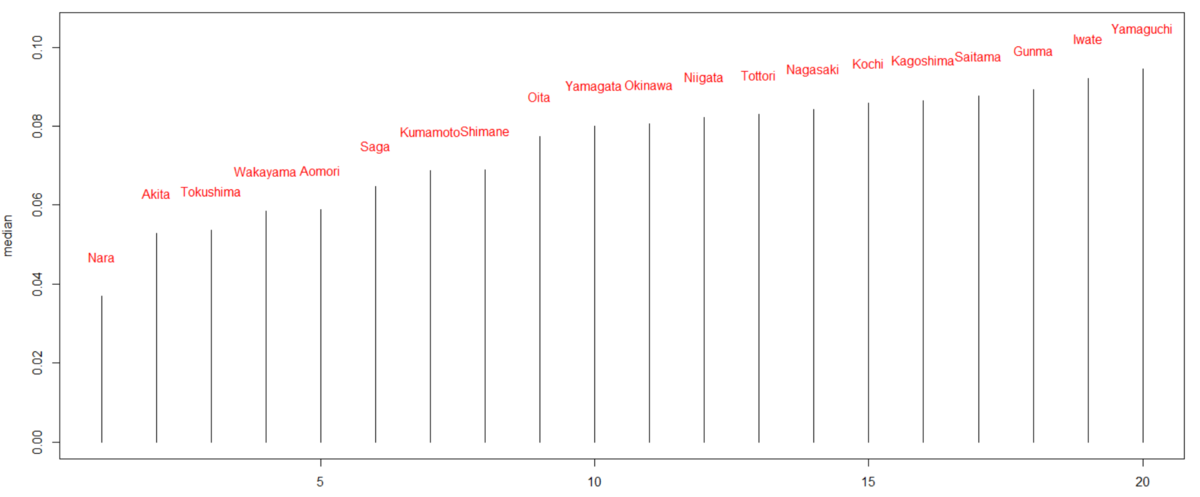
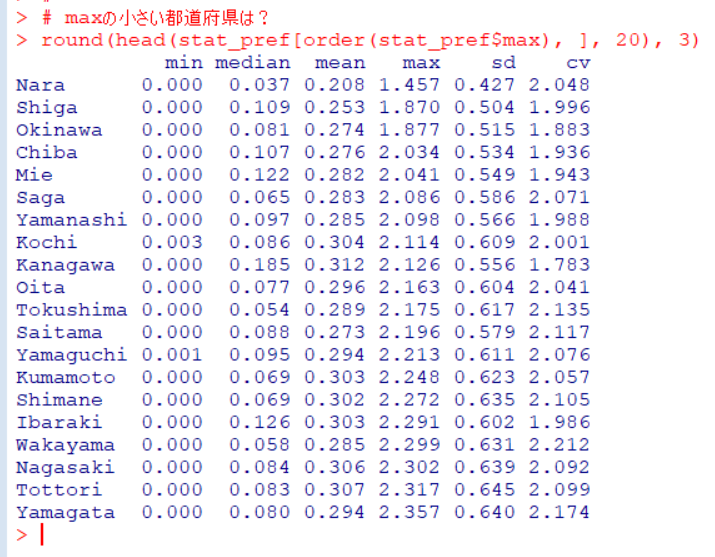
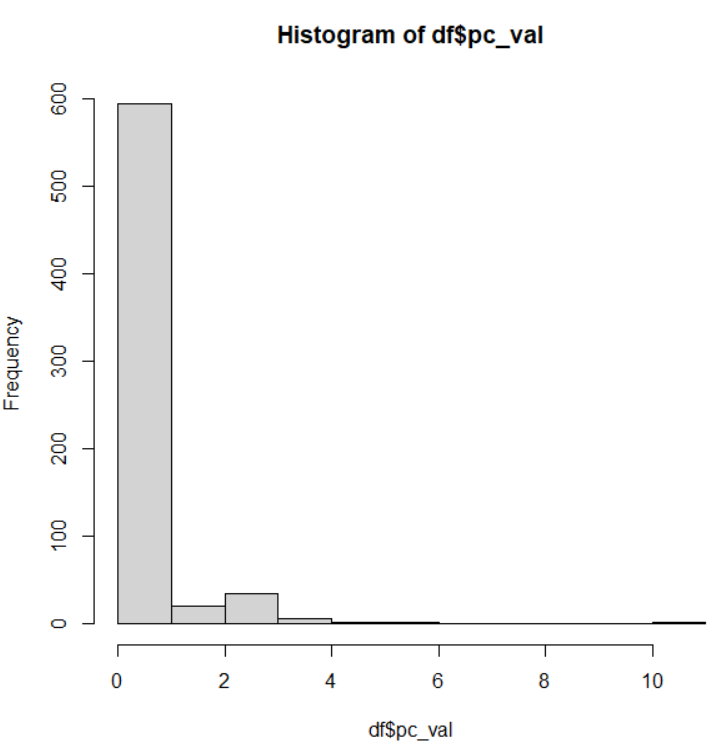
dfが変数が多くて大変なので、少し変数を絞ります。pref: 都道府県名、group: クラスタリングの結果、industry: 産業分類、value: 売上高(百万円単位), pc_val: 一人当たりの売上高(百万円単位), p_male304050: 30代、40代、50代の男性の比率 だけのデータフレームを作成します。

groupは整数型になったいますが、これはファクター型に変換します。
tidyverseパッケージを読み込んでいますので、mutate()関数を使ってみましょう。

summary()関数でdf_smallを表示しました。groupがファクター型に変換されていることがわかります。
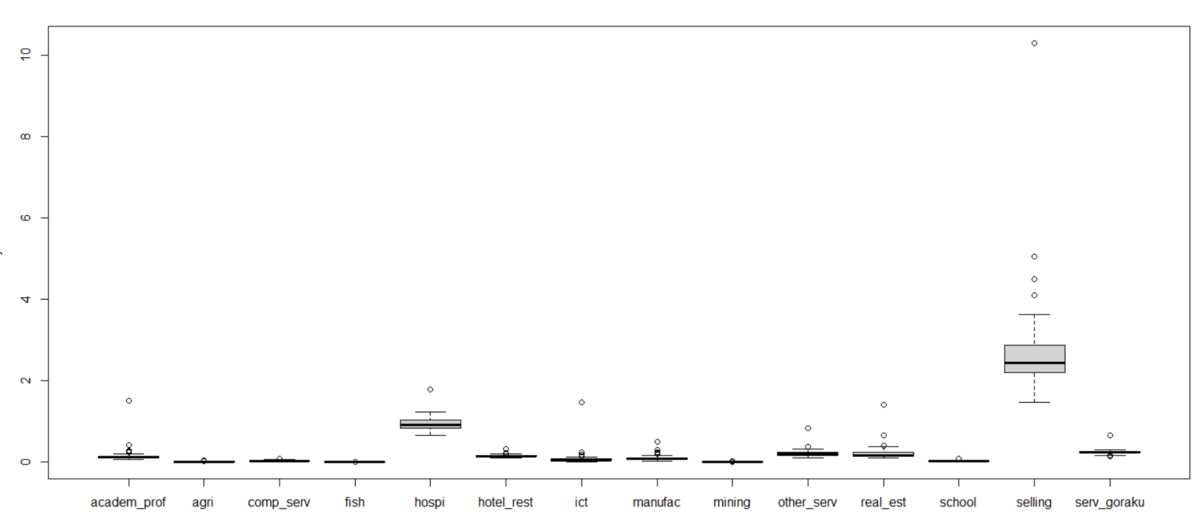
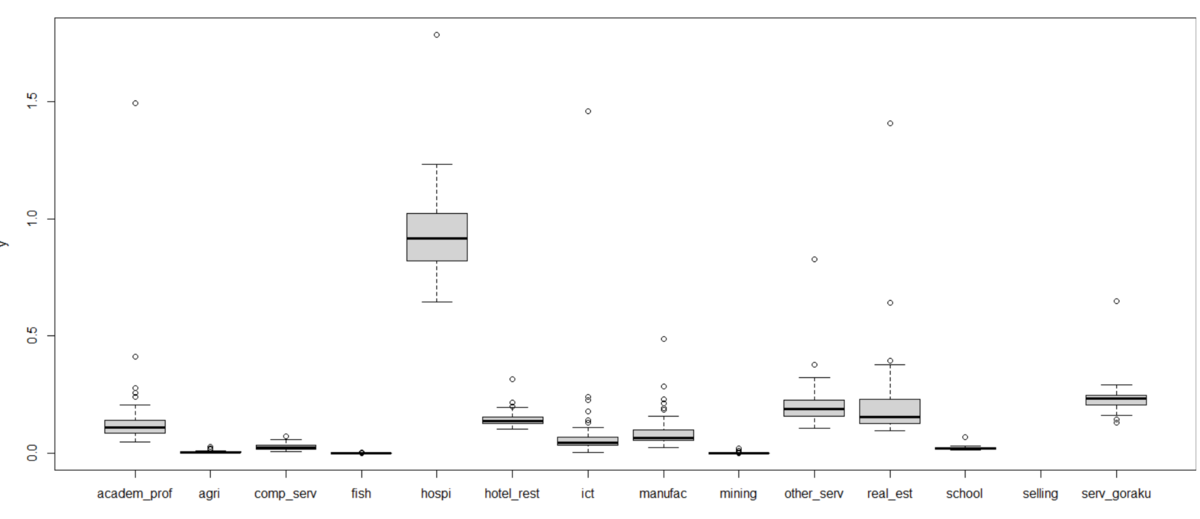
group_by()関数とsummarise()関数でgroupごとのvalue, pc_val, p_male304050の平均値を見てみます。

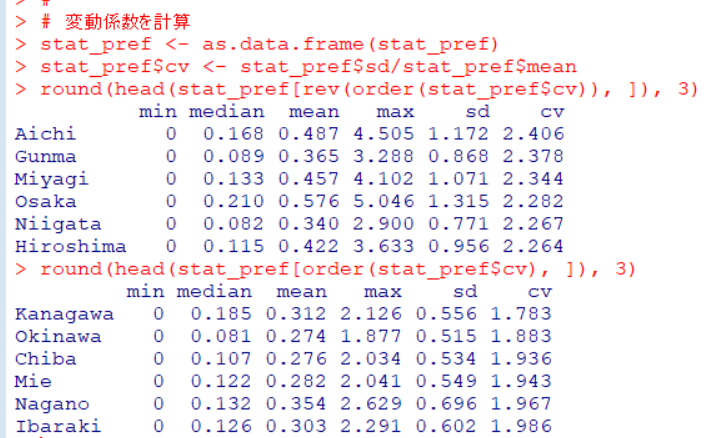
group4がどの値も一番大きいです。そして、1, 2, 3の順番ですね。
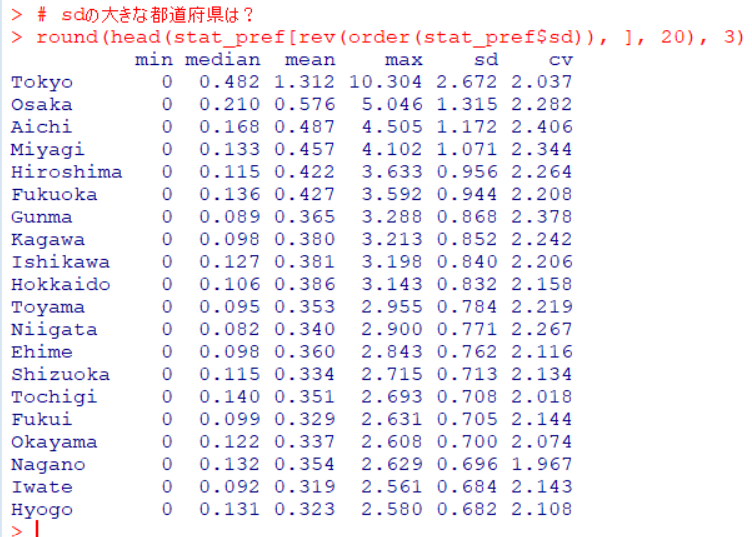
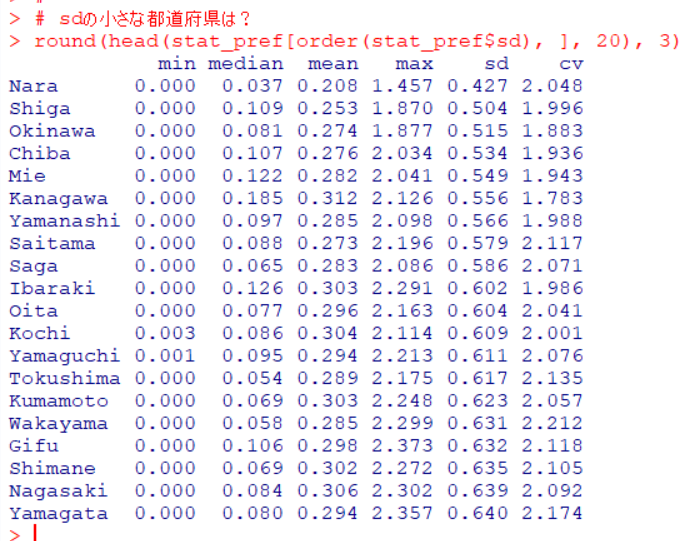
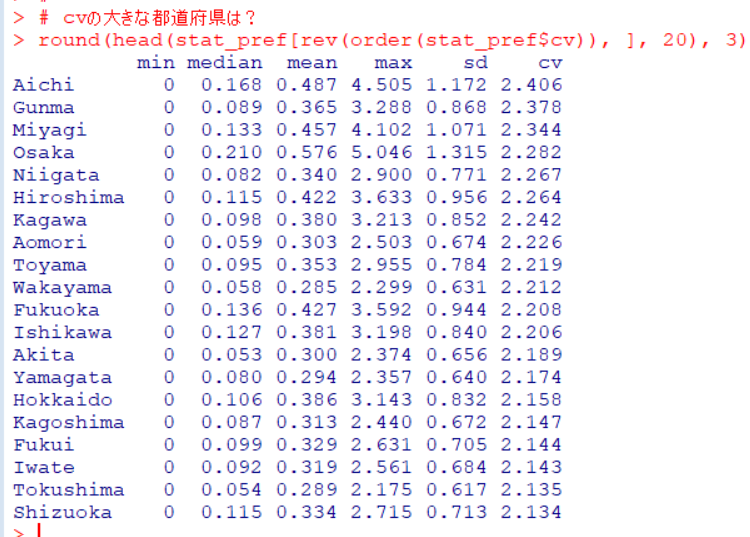
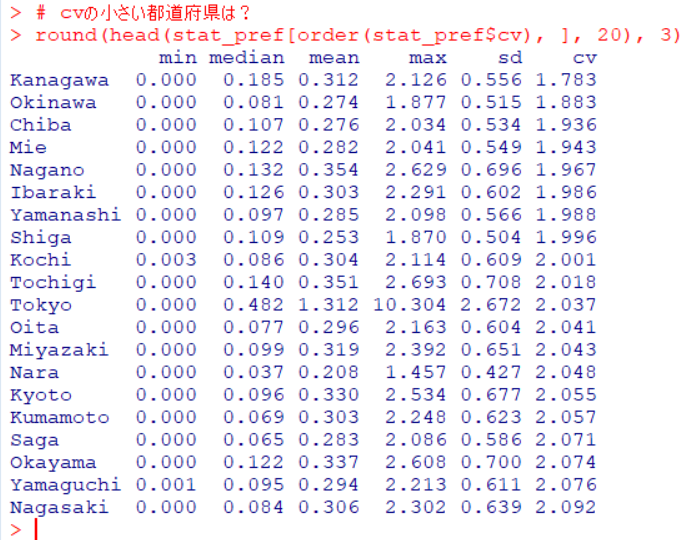
どのgroupがどの都道府県だったか、おさらいしておきましょう。

group1は愛知県、宮城県、大阪府でした。
groupごとの平均値が統計的に有意に異なるか、ANOVA分析をしてみます。
aov()関数とsummary()で実行できます。

p値が2e-16よりも小さいの、valueはgroupごとに有意な差があります。
pc_valはどうでしょうか?

p値が2.49e-05となっていますので、pc_valもgroupごとに有意な差があります。
p_male304050はどうでしょうか?

p値が2e-16よりも小さいので、p_male304050もgroupごとに有意な差があります。
今回は以上です。
次回は、
です。
はじめから読むには、
です。
")












































")