
Photo by HalGatewood.com on Unsplash
今回は都道府県別の献血者数のデータを分析しようと思います。
まず、政府統計の総合窓口(www.e-stat.go.jp)からデータをダウンロードします。
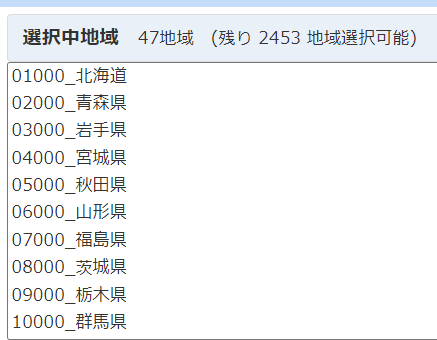
47の都道府県を選択し、

総人口、県内総生産額、献血者数、ボランティア活動行動者率の4つのデータを選択しました。
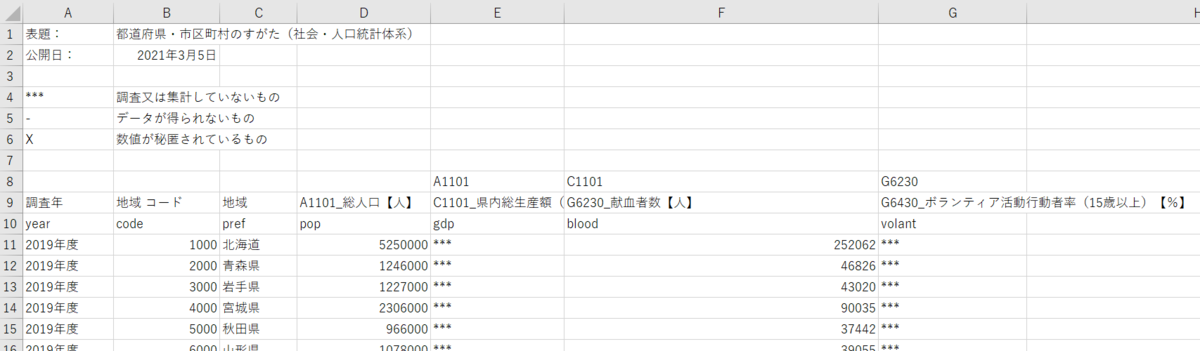
こんな感じのCSVファイルです。
早速これをR言語に読み込みましょう。
まず、tidyverseパッケージを読み込みます。
read_csv()関数でCSVファイルを読み込みます。

str関数でうまく読み込まれているかどうかを確認します。
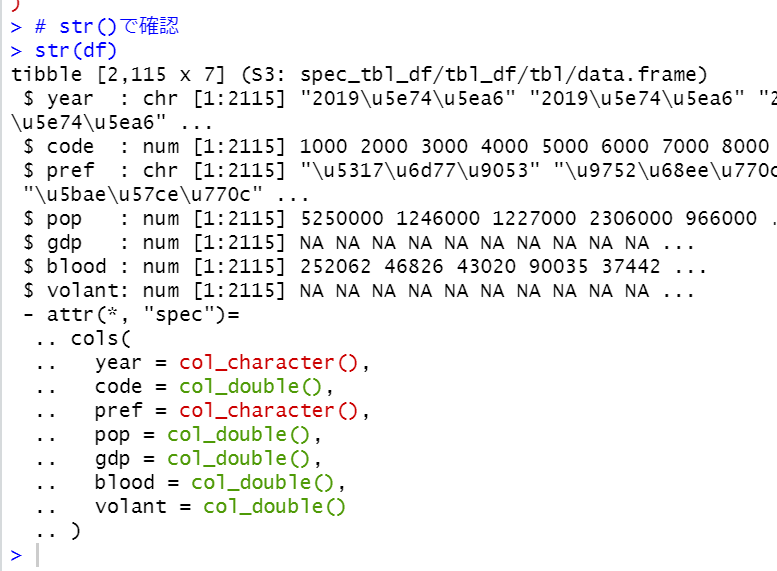
yearとprefが文字化けしています。
yearのほうは「年度」の部分が文字化けしています。これは始めの4文字だけを取り出せばいいですね。
str_sub()関数を使いましょう。

うまく始めの4文字だけを取り出せました。
prefの文字化けはどうにもならないので、別に用意してあるファイルを読み込みます。
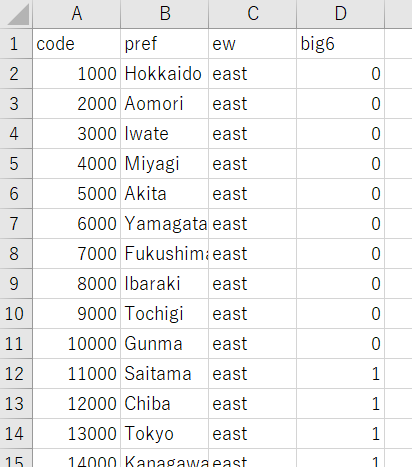
こういうCSVファイルです。このファイルのcodeとデータフレーム:dfのcodeを一致させて英語のprefをdfに加えます。ewは東日本か西日本か、big6は東京都、埼玉県、千葉県、神奈川県、愛知県、大阪府だと1を取るダミー変数です。
まず、read_csv()関数でファイルを読み込みます。

str()関数でうまく読み込まれているかどうか確認します。

うまくいきました。
inner_join関数でdfとpref_codeを結合します。

dfのほうのprefは文字化けしているから削除します。両方のデータフレームにcodeという変数があるので、codeを基準にしてpref_codeのデータをdfに結合しています。
na.omit()関数でNAのある行を削除してから、summary()関数でdfをみてみます。
year, pref, ewをファクター型に変換してからstr()関数でみてみます。

yearは2006年と2011年の2つの年があります。
prefはAichi, Akitaと英語になっています。
ewはeastとwestの2つの水準です。
これで分析の準備ができました。
今回は以上です。
次回は
です。