
Photo by Boris Smokrovic on Unsplash
今回は都道府県別のバスのデータを分析してみます。
政府統計の総合窓口(www.e-stat.go.jp)からデータを取得します。
まず、47都道府県を選択します。

選択したデータは、総人口(人)、県内総生産額(平成17年基準・百万円)、事業者(バス・
社)、旅客輸送人員(営業用・バス・千人)、就業者(運輸業・人)です。


サイトからダウンロードしたCSVファイルはこのようなものでした。10行目に変数名を追加しています。
year_code: 調査年コード
year: 調査年
pref_code: 地域コード
pref: 地域(都道府県名)
pop: 総人口(人)
gdp: 県内総生産(平成17年基準・百万円)
firm: 事業者(バス・社)
passenger: 旅客輸送人員(営業用・バス・人)
worker: 就業者数(運輸業・人)です。
これをR言語で分析します。
まずは、tidyverseパッケージを読み込んでおきます。

read_csv関数でCSVファイルのデータを読み込みます。

str()関数でデータが読み込まれたか見てみます。
yearとprefが文字化けしています。これは、どちらも日本語が入っているからだと思われます。yearは削除して、year_codeを10万を引いてから100万で割り算して西暦に直します。prefも削除して、pref_codeを基準にして英語の都道府県名のCSVファイルと合体させます。

昔作った、下のようなCSVファイルを読み込みます。

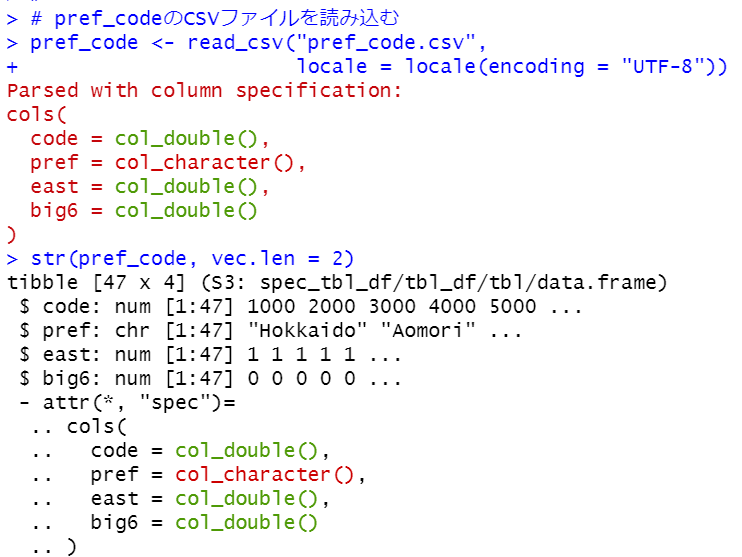
このpref_codeのデータフレームを、dfとinner_join()関数で合体させます。

eastは東日本なら1、そうでないなら0というダミー変数です。
big6は東京都、神奈川県、千葉県、埼玉県、愛知県、大阪府なら1、そうでないなら0というダミー変数です。
pref_codeはもう必要ないので削除して、変数の順番を整えましょう。

summary()関数でdfの概要を確認します。

gdp, firm, passenger, workerの4つの変数はNAがあります。これをどうにかしないといけないですね。
これは次回の課題としましょう。
今回は以上です。
次回は
です。