
Photo by Alex Williams on Unsplash
HistDataパッケージのEdgeworhDeathsのデータは、1885年、Edgeworthさんという人が発表した論文からのデータです。世界初の二元表のクロス表で、ANOVAの良い例だそうです。
早速、データを呼び出して、str()関数、head()関数でどんなデータかを見てみます。
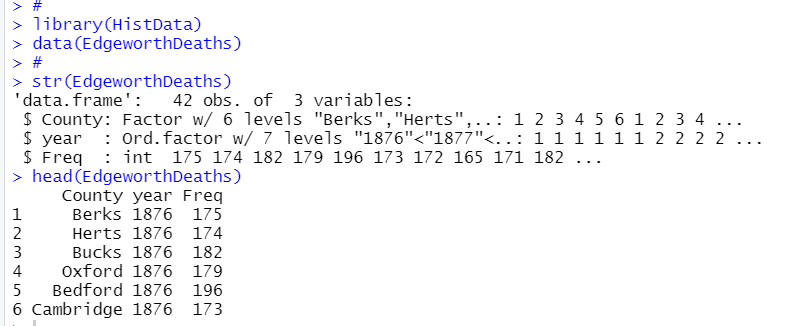
42行、3列のデータフレームです。Countyは6個のファクターです。英国の郡の名前のようです。yearは7個のファクターで、西暦ですね。順番付きのファクターで、1876年から始まっています。Freqは整数のデータで、人口1000人当たりの死亡者数です。
年によって死亡者数に違いがあるか、Countyによって死亡者数に違いがあるか、をANOVAで分析する、という感じでしょうか?
ヘルプのコードを実行してみます。

car, vcd, MASSといパッケージを呼び出してから、structable()関数を使っています。
この関数で、郡 x 西暦 のクロス表を作成しています。
structable()はvcdパッケージの関数です。
次は、

loglm()関数を使って、County, yearで死亡者数に違いがあるかどうかを検定しています。p値は1ですので、死亡者数に違いがるとは言えないです。
loglm()関数はMASSパッケージの関数です。
次は、
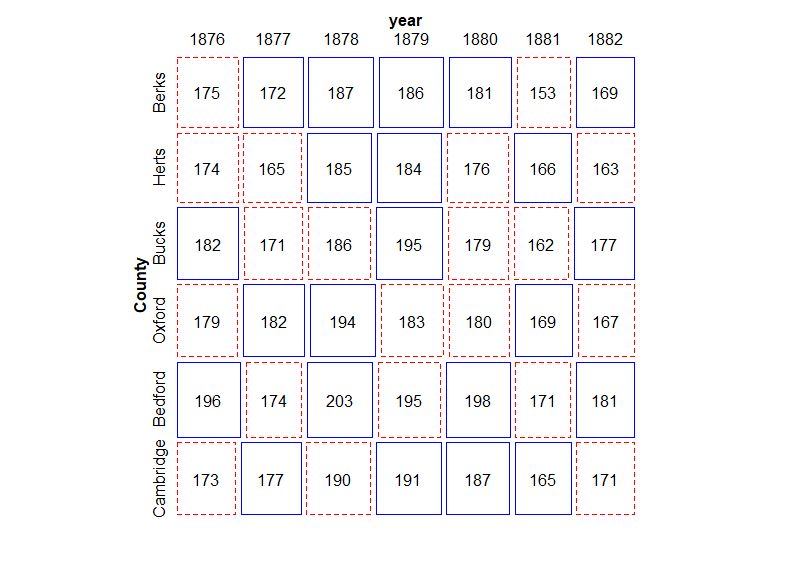
mosaic関数でクロス表をモザイクグラフにしています。どのセルも同じくらいの数値なので、モザイクグラフなのかどうかよくわからないですね。
架空のデータで同じようにやってみます。

こんな感じで架空のデータを作りました。
structable()でクロス表を作成します。
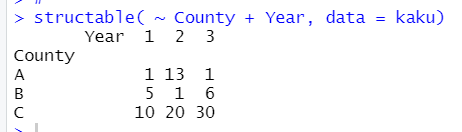
このクロス表を見ると、Countyごと、Yearごとに違いがありそうですよね。
loglm()関数で処理してみます。
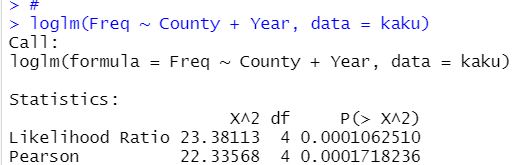
p値が0.0001となっています。やはり違いがありますね。
mosaic()関数でモザイクグラフを描きます。
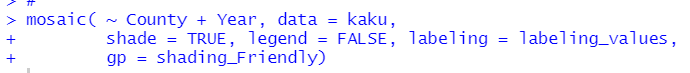

これだとモザイクグラフって感じですね。
今回のコードは以下のとおりです。
#
library(HistData)
data(EdgeworthDeaths)
#
str(EdgeworthDeaths)
head(EdgeworthDeaths)
#
# fit the additive ANOVA model
library(car) # for ANOVA
#
# now consider as a two-way table of frequencies
library(vcd)
library(MASS)
structable( ~ County + year, data = EdgeworthDeaths)
#
loglm(Freq ~ County + year, data = EdgeworthDeaths)
#
mosaic( ~ County + year, data = EdgeworthDeaths,
shade = TRUE, legend = FALSE, labeling = labeling_values,
gp = shading_Friendly)
#
# 架空のデータで
kaku <- data.frame(
County = rep(c("A", "B", "C"), 3),
Year = rep(1:3, each = 3),
Freq = c(1, 5, 10, 13, 1, 20, 1, 6, 30)
)
kaku
#
structable( ~ County + Year, data = kaku)
#
loglm(Freq ~ County + Year, data = kaku)
#
mosaic( ~ County + Year, data = kaku,
shade = TRUE, legend = FALSE, labeling = labeling_values,
gp = shading_Friendly)
#