の続きです。
今回は、2019年から2020年へ売り上げが伸びた都道府県、減少した都道府県という2値をとるダミー変数を作ってR言語のglm関数でロジスティクス回帰分析をしてみようと思います。
まず、2値をとるダミー変数を作ります。

前回と同じように、このchg_net_dummyと相関の強い変数を調べます。
相関係数を格納するデータフレームを作ります。
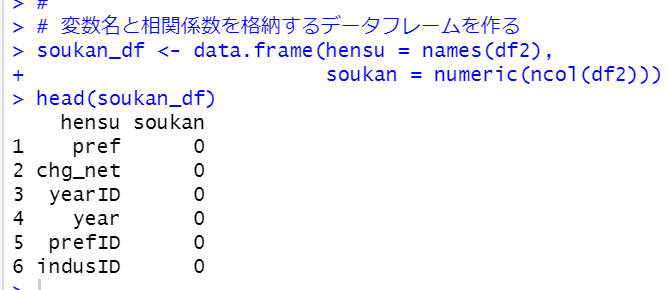
相関係数を計算して、for関数で格納していきます。

相関の強い変数を表示します。

saiyouは今回も相関が強いですね。
glm関数でロジスティクス回帰分析をします。

summary関数でモデルを詳しくみてみます。

step関数で有意でない変数を削除します。

anova関数でglm_1とglm_2を比較します。

p値は0.2544なので、glm_1とglm_2に有意な違いはありません。
glm_2をsummary関数でみてみます。
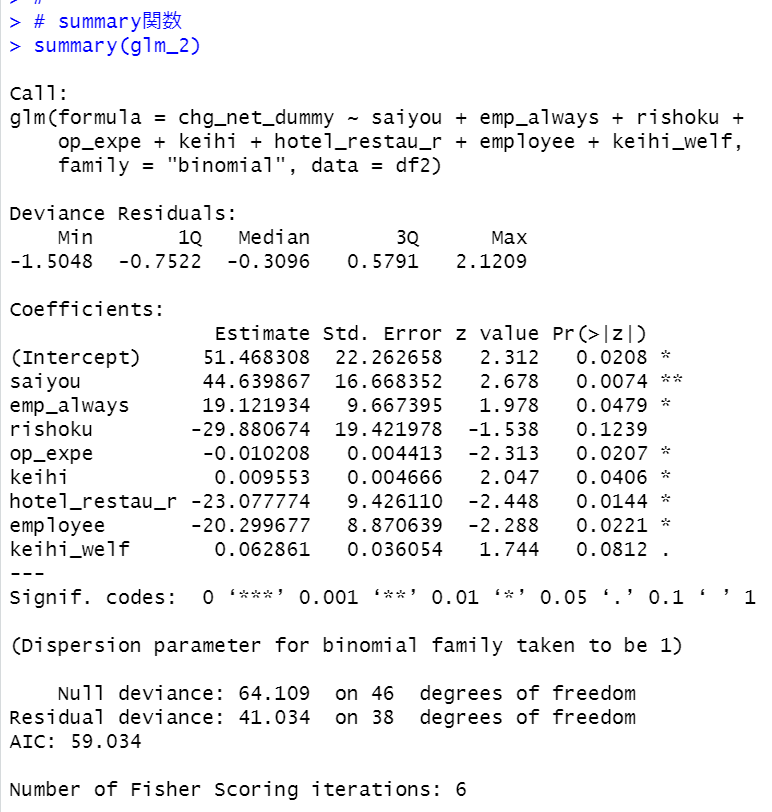
rishokuのp値は0.1239と0.05よりも高いです。update関数で削除します。

anova関数で、glm_2とglm_3を比較します。

p値が0.09941と0.05よりも大きいので、glm_3とglm_2には有意な違いはありません。
モデルは単純なほうがいいので、glm_3をみてみます。
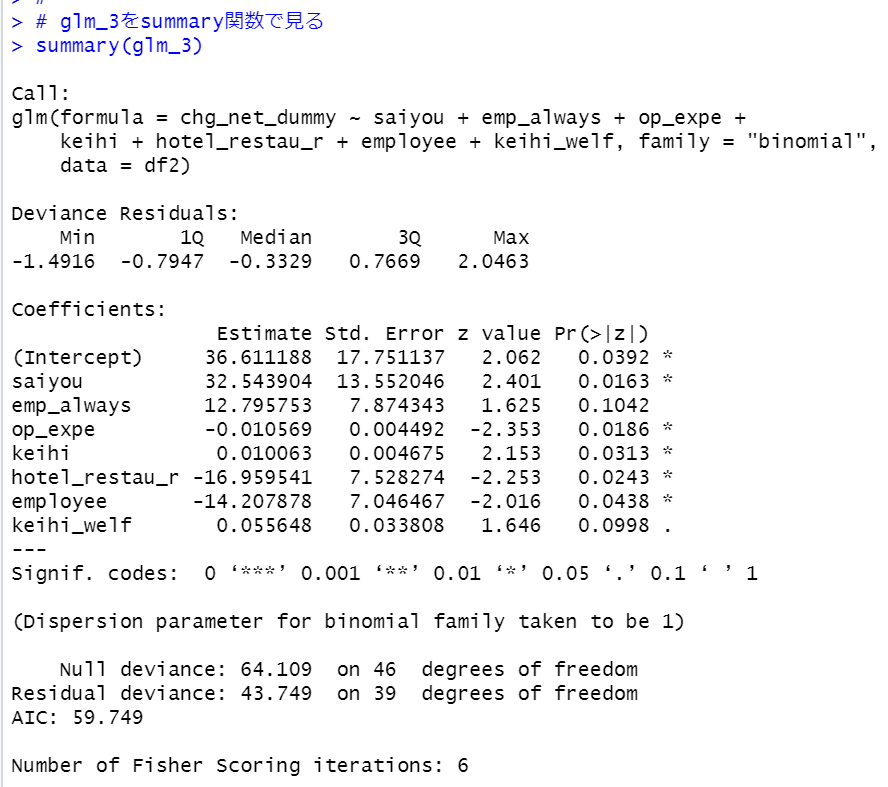
emp_alwaysが有意でないようです。削除します。

anova関数でglm_3とglm_4を比較します。

p値が0.07854と0.05よりも大きいので、glm_3とglm_4では有意な違いはありません。
glm_4をsummary関数でみてみます。

keihi_welfを削除します。
glm_4とglm_5をanova関数で比較します。

p値は0.1853ですね。glm_5を詳しくみてみます。

employeeを削除します。

glm_5とglm_6をanova関数で比較します。

glm_6をみてみます。

keihiを削除します。
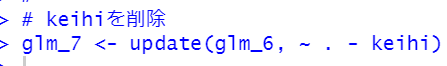
glm_6とglm_7をanova関数で比較します。

glm_7をみてみます。

op_expeを削除します。

glm_7とglm_8をanova関数で比較します。

glm_8をみてみます。

hotel_restau_rを削除します。

glm_8とglm_9をanova関数で比較します。

glm_9をみてみます。

たくさん説明変数がありましたが、最終的に残ったのはsaiyouだけでした。
2019年のsaiyou: 採用人数の多い都道府県ほど、2020年の売上高が増加している確率が高いことがわかります。
今回は以上です。
次回は
です。
はじめから読むには、
です。