
Photo by Ricky Kharawala on Unsplash
今回は、Cabinを調べます。客室ということでしょうかね?
まず、NAがあるかどうかを調べます。
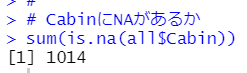
1014もNAがありますね。
他のデータはどんな形態でしょうか?はじめの50個ぐらいを表示してみます。

NAが多いのですね。その他はC85やE46など始めの一文字がアルファベットで残りが数字のパターンでしょうか?
分析しやすいように、始めの一文字だけの変数をまず作り、NAはn_aとでもします。
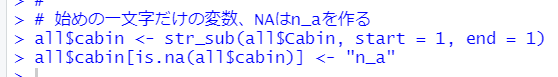
この小文字のcabinでtrainとtestで度数を比較します。

n_aが圧倒的に多いのですね。prop.table()関数で比率でやってみます。

おんなじような比率に見えます。chisq.test()関数でtrainとtestの度数に違いがあるのかどうかを検定します。

p-valueは0.7438と0.05よりもうんと大きな値です。trainとtestでcabinの分布に大きな違いは無いようです。
Survivedとcabinの関係をみてみます。それぞれの生存率をみてみます。

n_aは生存率が30%と他のより低いですね。Tは一人しかいませんでしたがこの人は死亡したのですね。
n_aとTをベースにしてダミー変数を作成します。cabin_aからcabin_gまでですね。

こうして作成したダミー変数を説明変数、Survivedを被説明変数にしてlm()関数で回帰分析をします。

(Intercept)の0.29942はCabinがNAかTで始める客室の人の生存率です。約30%です。
cabin_dの係数が一番大きくて0.45816です。
つまり、0.29942 + 0.45816 = 0.75758, 75.8%の生存率ということですね。
今回は以上です。
次回は
です。
はじめから読むには、
です。