
Photo by Jeremy Thomas on Unsplash
政府統計の総合窓口、e-statのサイトを見ると、小売物価統計のデータベースが更新されたようです。

今回はこのデータをダウンロードして分析してみます。

小売物価統計調査(動向編)というのが更新されたようです。

月次[2件]が更新されたようです。

全国統一価格の月別価格のほうをダウンロードしてみます。

こんな感じのファイルです。15行目に変数名を挿入しました。
このCSVファイルをR言語で読み込んで、分析します。
まずはじめに、tidyverseパッケージを読み込んでおきます。

read_csv()関数でファイルを読み込みます。

なんとか読み込んだようです。
str()関数でデータ構造を確認します。

日本語は文字化けしてしまうのですが、38,736行、8列のデータフレームです。
一つ一つの変数を見ていきます。
まずは、title_code: 表章題目コードです。

最小値から最大値まですべて10ですね。つまり、この変数は全部10という値ということです。なので、この変数は削除してもかまわないですね。後で除外します。
次は、title: 表章題目です。

これは文字化けしていますが、価格という一つの言葉しかないようです。これもあとで除外します。
次は、name_code: 銘柄コードです。

銘柄コードがNAの行が386あるのと、銘柄コードの種類は300あることがわかりました。後でNAの386行は削除しましょう。
次は、name: 銘柄です。
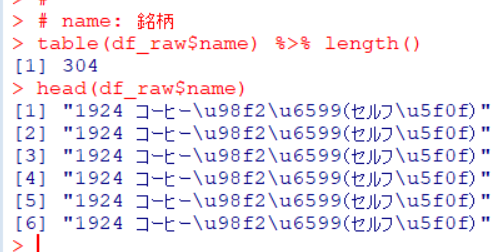
nameは304種類あるようです。でも文字化けしているので、これも後で除外します。
次は、time_code: 時間軸(月)コードです。

267種類あるということは、267/12=22.25ですから、22年と3か月分のデータがあるのですね。2000年2月から2022年4月までのようです。time_codeは後で200002, 202204のように直しましょう。
次は、time: 時間軸(月)です。

267種類あるのはtime_codeと一致しています。文字化けしていますので、これも後で除外しましょう。
次は、data_type: データの種類です。

これは全部NAだったんですね。これも後で削除します。
最後は、price: 価格です。

NAの行が838行あります。最小値が0円で最大値が6,002,690円です。NAの行は削除しましょう。
これで全部の変数のチェックは終わりました。
これからやるべきことは、
1. NAの行を削除
2. title_code, title, name, time, data_typeの除外
3. time_codeをYYYYMMに直す。
の3点です。
これは次回やりましょう。
今回は以上です。
次回は、
です。