
Bing Image Creator から作成
今回は、都道府県別の雇用動向調査のデータを分析します。

政府統計の総合窓口(e-stat)のホームページからデータをダウンロードします。
入職者のところをクリックしてみます。

性、都道府県、職歴、年齢別入職者数のDBのところをクリックしてみます。
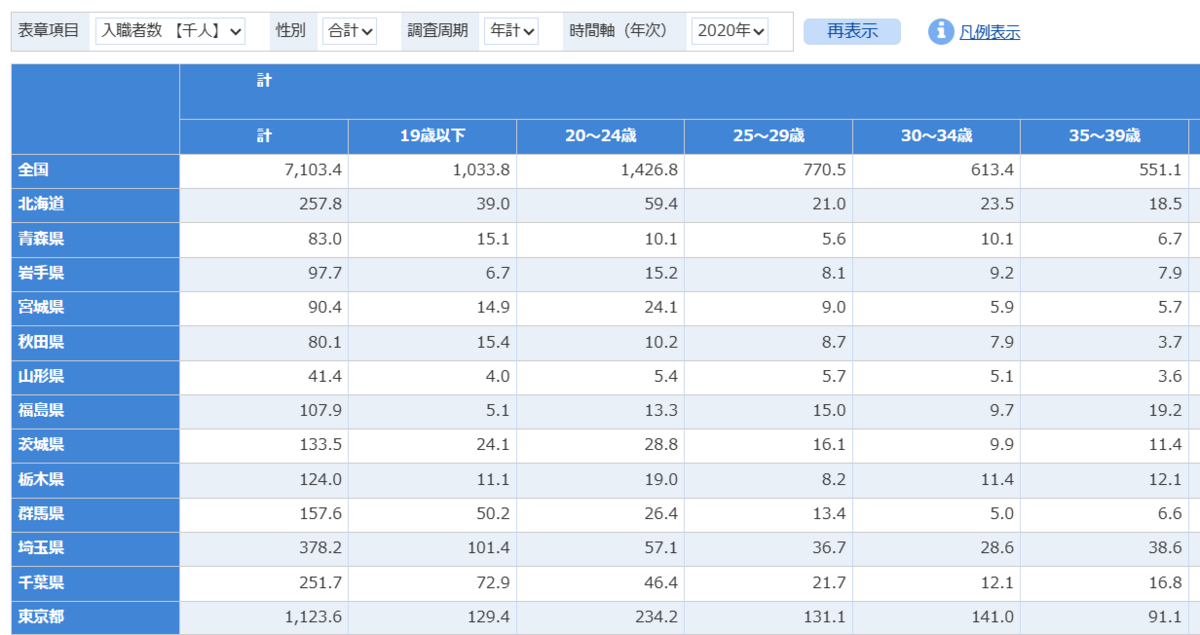
こんな感じのデータです。CSVファイルをダウンロードします。
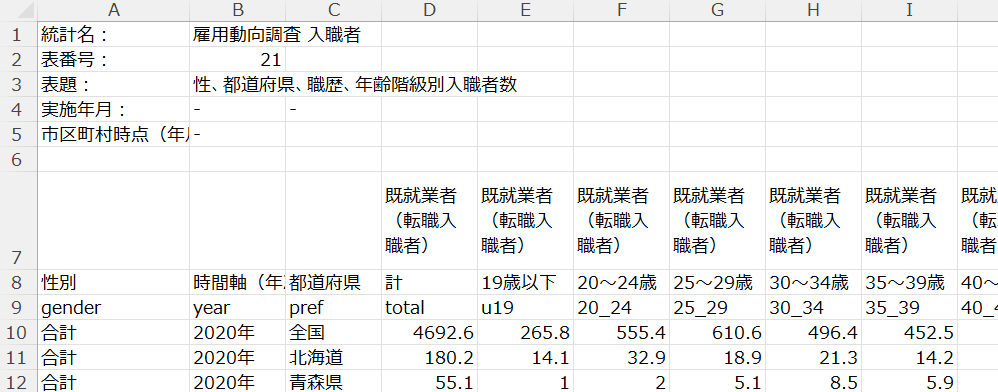
このようなCSVファイルがダウンロードできました。未就業者のデータもありましたが、今回は既就業者(転職入植者)に絞りました。9行目は変数名を私が入れました。
このCSVファイルをRに読み込ませます。
はじめに、tidyverseパッケージを読み込んでおきます。

そうしたら、read_csv()関数でCSVファイルを読み込みます。
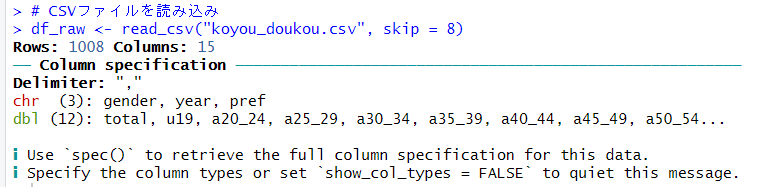
gender, year, prefの3つの変数が文字列型のデータ、その他のデータが数値型です。
gender, year, prefの頻度をtable関数でみてみます。

select()関数でgender, year, prefの3つだけを選択して、lapply()関数の中でtable()関数を使いました。
genderは合計、女、男でそれぞれ336の観測数
yearは2014年から2020年でそれぞれ144の観測数
prefは47都道府県でそれぞれ21の観測数です。
欠けている観測は無いようです。
次は、数値データの基本統計値を見てみます。
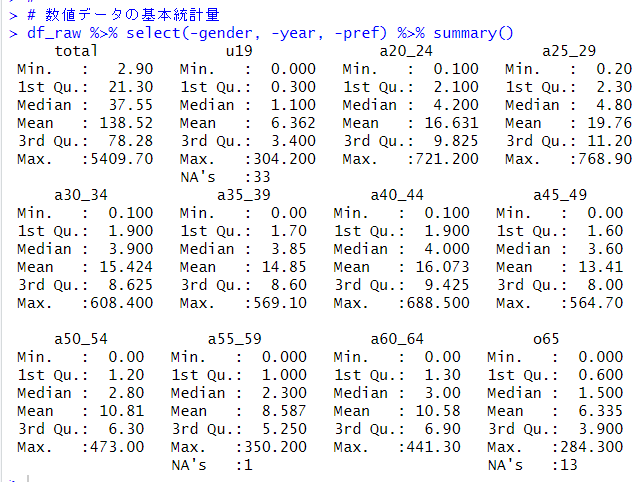
これらの数値は既就業者(転入職者数)で、千人単位です。NAの観測がu19, a55_59, o65の変数でいくつかあります。これは0に置換しましょう。
元のNAの情報はとっておきたいので、新しくdfという名前のデータフレームを作り、そのデータフレームのNAを0に置換しました。
確認します。
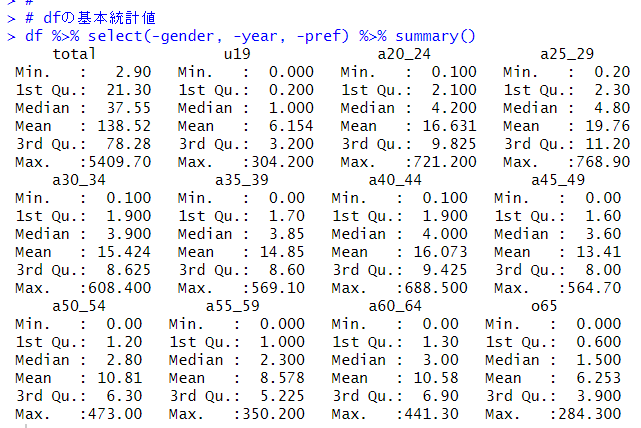
NAがなくなっています。
そういえば、prefの中に「全国」がありました。これは分析には必要ないので、削除しておきます。

これで、分析するためのデータフレームが整いました。skimrパッケージのskim()関数を使ってデータフレームの様子を確認します。
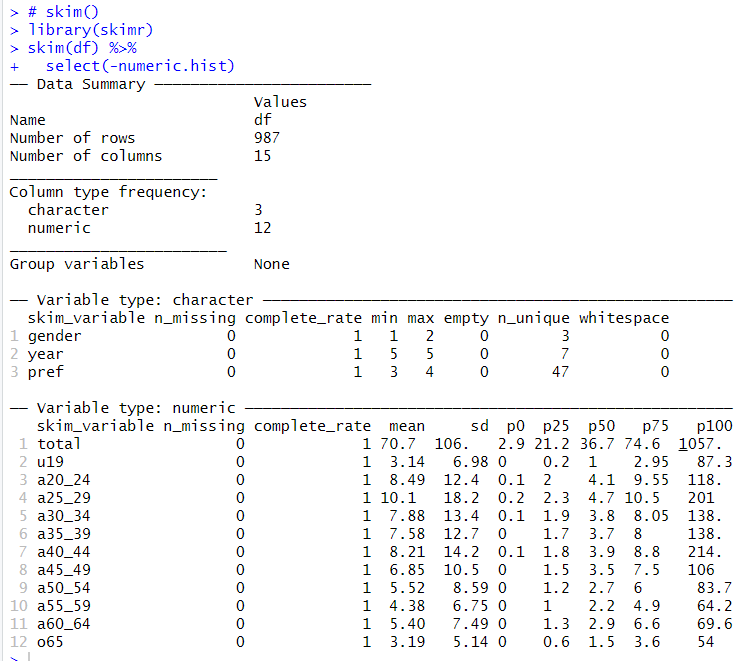
skim()関数はそのままだと数値データのヒストグラムを表示します。
select(-numeric.hist)を加えてヒストグラムを非表示にしました。
n_missingがすべて0なのでNAが無いことがわかります。平均値はa25_29が10.1で一番多いです。最大値はa40_44で214です。
今回は以上です。
次回は、
です。