
Generated by Bing Image Creator: rice field, blue sky, little flower
今回は、都道府県別の長屋建住宅数のデータを分析してみようと思います。
政府統計の総合窓口、e-statのウェブサイトからデータを取得します。

地域のところをクリックします。

データ表示をクリックします。

47都道府県を選択します。

長屋建住宅数を選択します。コントロール変数として、総人口と県内総生産額も選択しました。

このようなCSVファイルをダウンロードできました。
これをRに読み込ませて分析します。
はじめに、tidyverseパッケージの読み込みをしておきます。

read_csv()関数でCSVファイルを読み込みます。
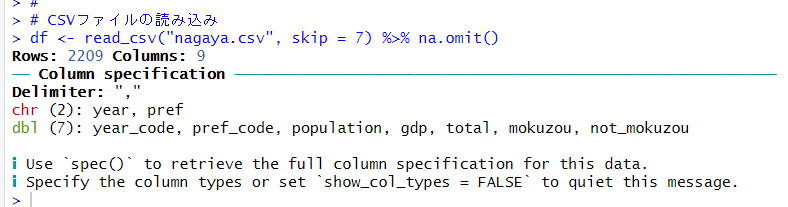
na.omit()関数を使って、NAの行を削除しました。
glimpse()関数を使って、読み込んだファイルのデータを確認します。

文字化けせずに読み込まれました。
year_codeはyearと同じなので必要なし、pref_codeはprefと同じなので必要なし、yearとprefは文字列ですので、この2つはファクター型に変更します。

skimrパッケージのskim()関数でそれぞれの変数の様子を確認します。
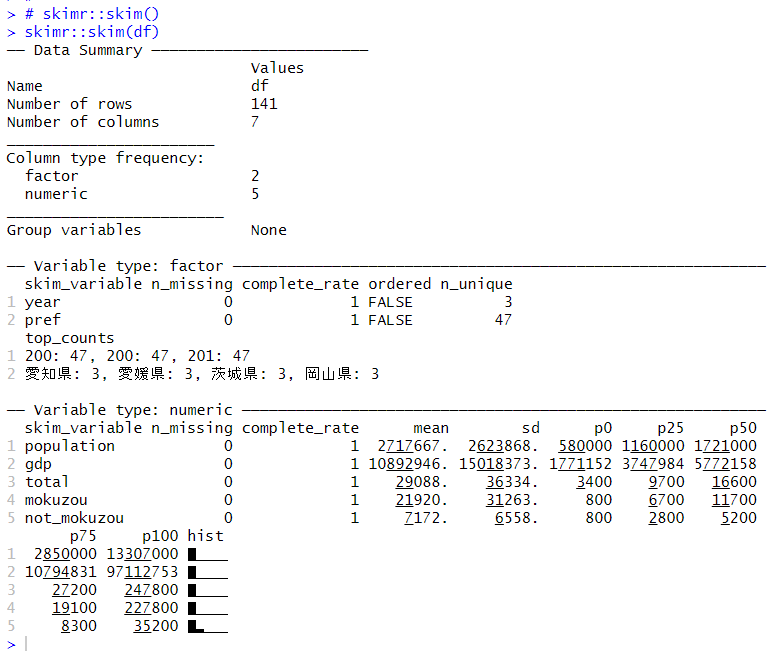
出力された結果を上から順にみてみます。
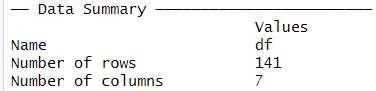
Data Summaryのパートで、データフレームの名前はdf、行数は141行、列数は7列あることがわかります。

Column type frequencyのところで、ファクター型の変数が2つ、数値型の変数が5つとわかります。
Group variablesはNoneなので、グループ化されている変数は無いとわかります。

variable type: factor のところで、year と pref がファクター型の変数で、2つともNAはなし、オーダーファクター型の変数ではないことがわかります。yearは3つの値、prefは47の値とわかります。yearが3つということは、3年分のデータがあるということです。

variable type: numericのところで数値型の変数の様子がわかります。population, gdp, total, mokuzou, not_mokuzouの5つともNAはありません。p0が最小値のところです。5つとも正の値なので、対数変換したほうがいいかもしれないです。
histの列がヒストグラムの外観になっていますが、どれも左端に分布が集中しています。やはり、対数変換したほうがいいようです。
今回は以上です。
次回は、
です。