
Generated by Bing Image Creator: Photo of many iris flowers in water world in the dinosaur age
の続きです。
今回は、RのrpartパッケージでClassification TreeをつかってDERMASONとSIRAを区別してみます。
How to Fit Classification and Regression Trees in R (statology.org)
を参考にしました。
まずは、rpartパッケージとrpart.plotパッケージを読み込みます。

次に、トレーニング用のデータとテスト用のデータにわけます。

それでは、rpartパッケージを使っていきます。はじめは、cp=0.0001でclassification treeを作ります。

printcp()関数で結果をみてみます。
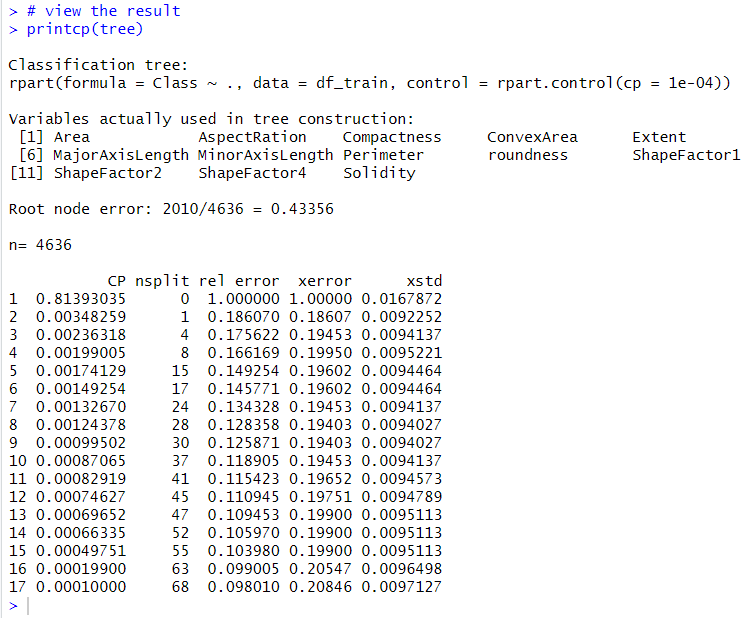
CPというのは、Complexity Parameterという意味です。xerrorの値が一番小さいCPを使って最終crassification treeを作ります。

cp = 0.003482587が一番xerrorが小さいcpです。
prune()関数を使います。pruneというのは、木を剪定する、という意味です。

prp()関数で結果をグラフにしてみましょう。


なんとびっくり!このclassification treeは、Perimeterが745.34よりも小さければDERMASON、そうでなければSIRAというとっても単純なモデルでした。
このモデルでテスト用のデータを予測してみます。

本当のデータとどれだけ予測データが合致しているかみてみます。

DERMASONを正しく正解したのが869個、SIRAを正しく正解したのが549個です。
正解率は、

91.7%でした。
でたらめに予測したらどのくらいの正解率でしょうか?


51.7%でした。
それにしても、Perimeter < 745.34 という単純なルールで91.7%の正解率とはびっくりでした。DERMASONとSIRAはそれだけはっきりとした違いがあるのでしょう。
今回は以上です。
次回は、
です。
はじめから読むには、
です。