
Bing Image Creator で生成: Landscape photograph of Japanese Plum Flowers, background is blue sky and white clouds, photo
今回からしばらくは、都道府県別の老齢化指数と県内総生産額対前年増加率のデータの分析をしてみます。
政府統計の総合窓口 (www.e-stat.go.jp) のウェブサイトからデータを取得します。

47地域を選択して、

老年化指数と県内総生産額対前年増加率(平成27年基準)を選択します。

こんな感じのデータです。
これを CSV ファイルとしてダウンロードしました。
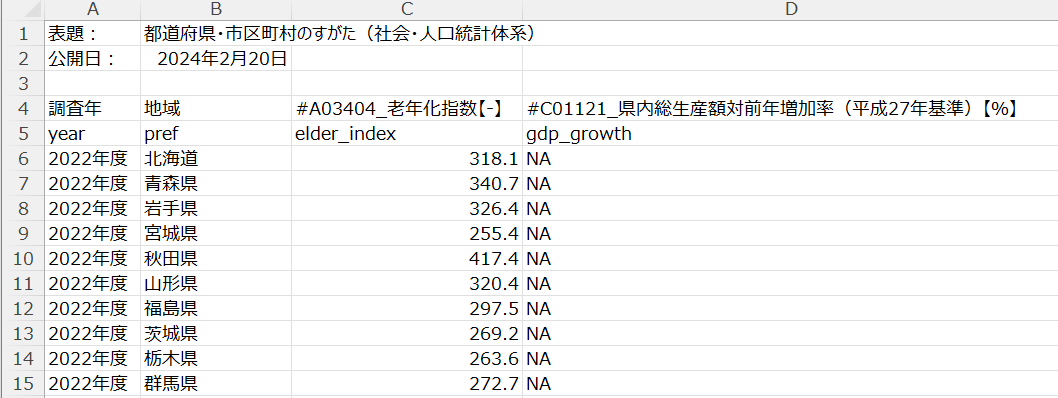
このような CSV ファイルです。
year: 調査年
pref: 地域
elder_index: 老年化指数
gdp_growth: 県内総生産額対前年増加率(平成27年基準)
と変数名を5行目に挿入しました。
このCSV ファイルを R に読み込んで分析します。
はじめに、tidyverse パッケージを読み込みます。
read_csv() 関数でファイルを読み込みます。

na.omit() 関数で NA の行を削除します。

summary() 関数で df のサマリーをみてみましょう。

year と pref をファクター型の変数にしておきましょう。

pref のところを見ると、8となってますから、8年間のデータがあることがわかります。
今回は以上です。
次回は
です。
今回のコードは以下になります。
#
# tidyverse パッケージを読み込む
library(tidyverse)
#
# CSV ファイルを読み込む
df_raw <- read_csv("elder_gdp_growth.csv",
skip = 4)
#
# NA 行を削除
df <- na.omit(df_raw)
#
# サマリー
summary(df)
#
# year, pref をファクター型の変数にする
df <- df |>
mutate(year = factor(year),
pref = factor(pref))
summary(df)
#