
(Bing Image Creator で生成: プロンプト: Close up of white Rhododendron flowers and pink Rhododendron flowers, flowering top of green hill, photo )
の続きです。各変数がどんなものかチェックしていきましょう。
はじめに、作業用のデータフレームを作っておきます。

y を予測するというタスクなので、relocate()関数で y を一番左に移動させました。
y について調べてみます。

yes が11.7%ということですね。y だと何が何だかわからないので、変数の名前を変えて、yes という名前にして、yes なら 1 no なら 0 のダミー変数にします。

1 か 0 かという数値型の変数にしておくと、相関係数などが計算できますので、あとあと便利です。
次は、age です。年齢ですね。
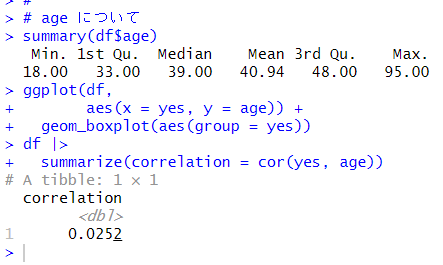
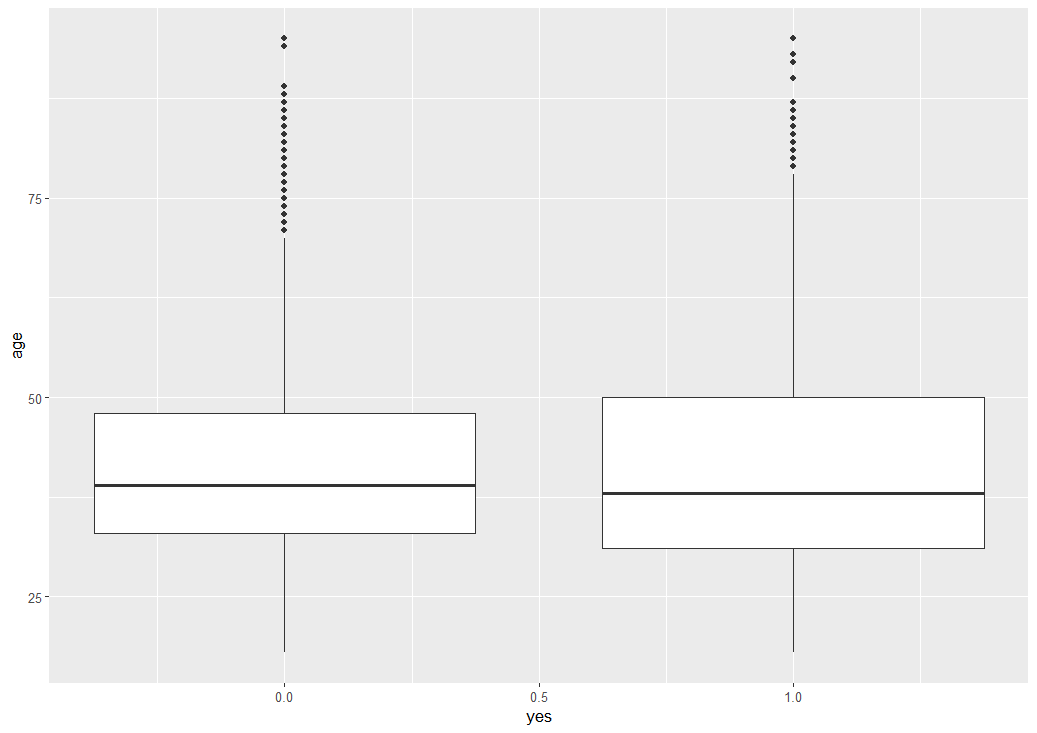
summary()関数で age の統計値を見ると、最少年齢は18歳で、最高年齢は95歳です。平均値は40.94歳で、中央値は39歳でした。yes 別の箱ひげ図を描きましたが、違いはあまりないようです。yes との相関係数は 0.0252 と相関は無い感じですね。年齢によって、yes か no かの違いはないようです。
次は、job です。職業ですね。
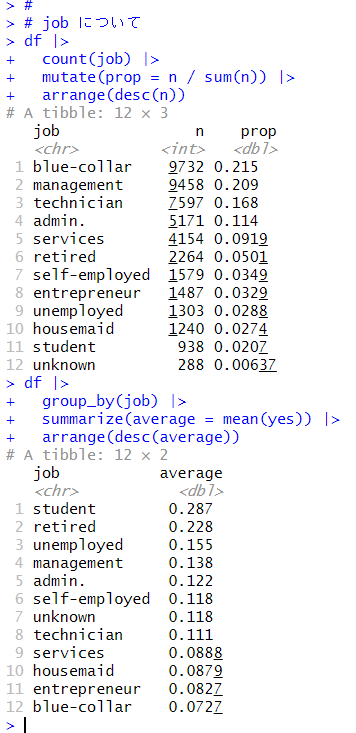
blue-collar が一番数は多いですが、yes の比率は blue-collar が 7% ほどと一番低いです。student が yes の比率は 28.7% と一番多いですね。
この job を student が 12, retired が 11, ... entrepreneur が 2, blue-collar が 1 というように、yes の比率の順番の数値データに変換してしまいます。そうすると、相関係数が計算できますからね。
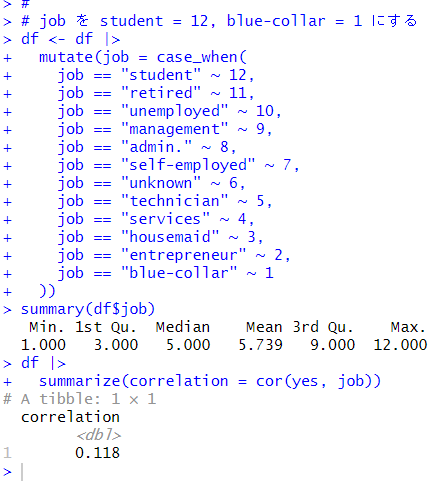
case_when()関数でそれぞれの場合の値を指定して変換しました。yes との相関は 0.118 ですので、age と比べると相関が強いですね。
次は、marital です。婚姻状況です。
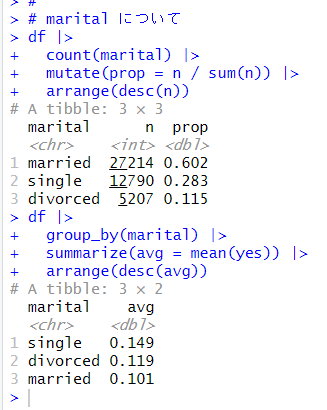
結婚(married), 独身(single), 離婚(divorced)の3つの状態があって、結婚が6割ほどですね。 yes の比率は single が一番高いようです。これも、job と同じように、single = 3, divorced = 2, married = 1 と数値データに変換してしまいます。
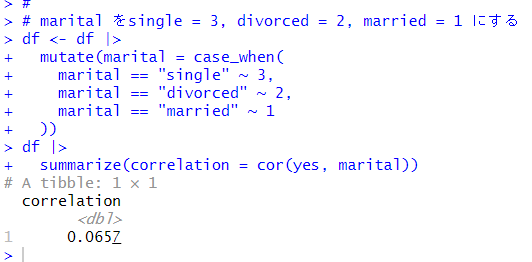
yes との相関係数は 0.0657 とあまり相関は無いようですね。
次は、education 学歴水準です。
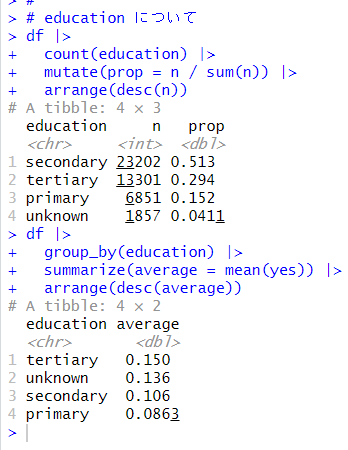
tertiary がyes の比率が一番高く、primary が一番低いです。これも数値データに変換してしまいます。
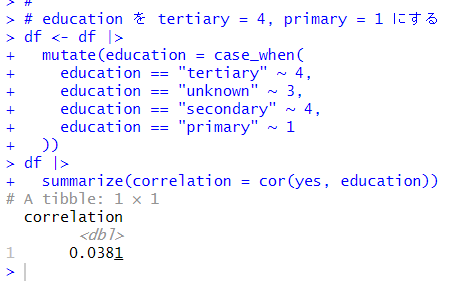
相関係数は 0.0381 なので、あまり相関はないですね。
次は、default です。これは、クレジットがデフォルト状態かどうか?というものです。

98% が no です。default が yes なら 1 のダミー変数にしました。相関係数は -0.0224 と負の値ですが、ほとんど相関はありません。
次は、balance です。average yearly balance と UCI のサイトには説明がありました。年間の平均の銀行口座残高ですね。

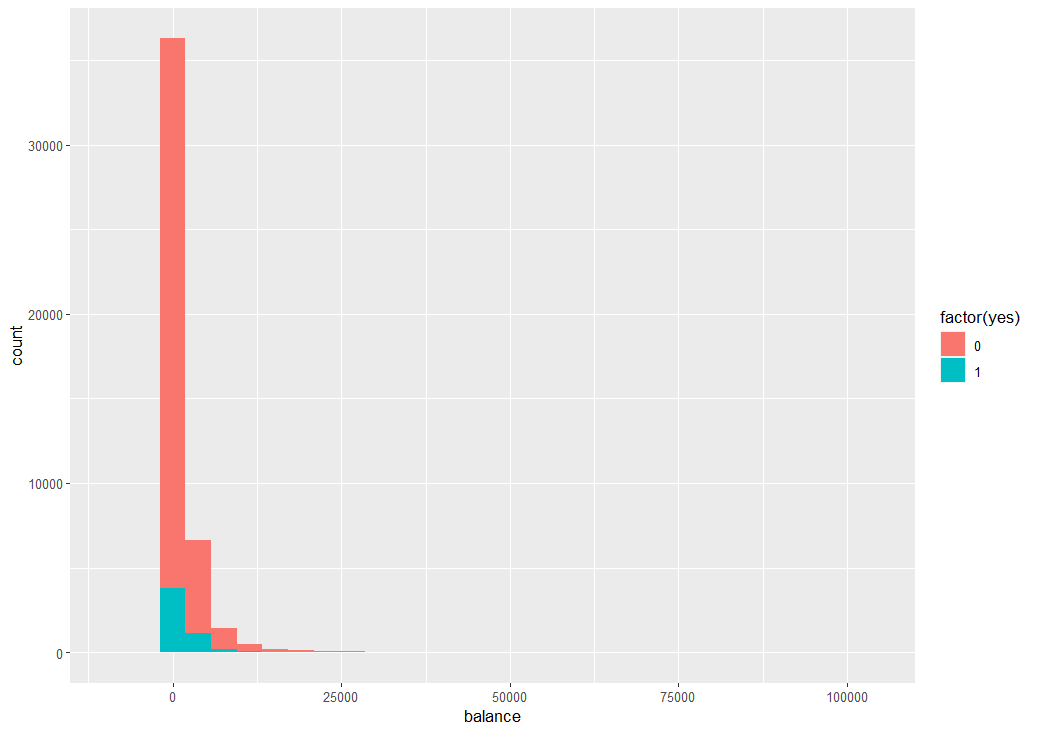
右の裾野が広い偏った分布ですね。yes 別の箱ひげ図をみてみます。
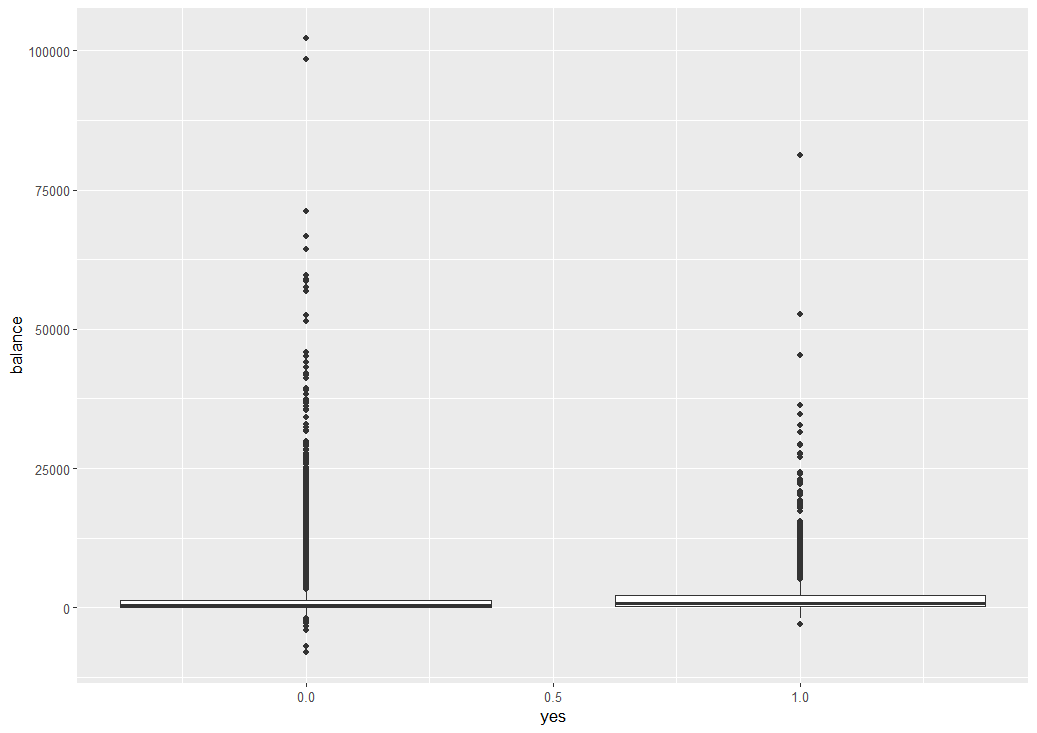
外れ値が外れすぎていて、箱ひげ図の箱がつぶれてしまってますね。
相関係数を計算してみましょう。
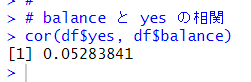
0.05 なので相関はなさそうです。
次は、housing です。住宅ローンがあるか、ないかです。

あるほうが 55% で、ないほうが 44% ですね、yes なら 1 のダミー変数にして相関を計算しました。-0.139 なので、住宅ローンが無い人のほうが yes となりやすいです。
次は loan です。住宅ローンではない、個人のローンがあるかどうかです。

ローンが無い日とが 84% で、ある人が 16% でした。ローンがある人を 1 にしてダミー変数にして、相関係数を計算しました。負の相関ですが、 -0.0682 と小さな値なので、あまり相関はなさそうです。
ここままで、だいたい半分くらいの変数のチェックが終わりました。
今回はここまでにしたいと思います。
次回は、
です。
初めから読むには、
です。
今回のコードは以下になります。
#
# df_raw を作業用のデータフレームにコピー
df <- df_raw |>
relocate(y)
#
# y について
df |>
count(y) |>
mutate(prop = n / sum(n))
#
# y = yes なら 1 のダミー変数に変換, 変数名を yes に
df <- df |>
mutate( y = if_else(y == "yes", 1, 0)) |>
rename(yes = y)
#
# age について
summary(df$age)
ggplot(df,
aes(x = yes, y = age)) +
geom_boxplot(aes(group = yes))
df |>
summarize(correlation = cor(yes, age))
#
# job について
df |>
count(job) |>
mutate(prop = n / sum(n)) |>
arrange(desc(n))
df |>
group_by(job) |>
summarize(average = mean(yes)) |>
arrange(desc(average))
#
# job を student = 12, blue-collar = 1 にする
df <- df |>
mutate(job = case_when(
job == "student" ~ 12,
job == "retired" ~ 11,
job == "unemployed" ~ 10,
job == "management" ~ 9,
job == "admin." ~ 8,
job == "self-employed" ~ 7,
job == "unknown" ~ 6,
job == "technician" ~ 5,
job == "services" ~ 4,
job == "housemaid" ~ 3,
job == "entrepreneur" ~ 2,
job == "blue-collar" ~ 1
))
summary(df$job)
df |>
summarize(correlation = cor(yes, job))
#
# marital について
df |>
count(marital) |>
mutate(prop = n / sum(n)) |>
arrange(desc(n))
df |>
group_by(marital) |>
summarize(avg = mean(yes)) |>
arrange(desc(avg))
#
# marital をsingle = 3, divorced = 2, married = 1 にする
df <- df |>
mutate(marital = case_when(
marital == "single" ~ 3,
marital == "divorced" ~ 2,
marital == "married" ~ 1
))
df |>
summarize(correlation = cor(yes, marital))
#
# education について
df |>
count(education) |>
mutate(prop = n / sum(n)) |>
arrange(desc(n))
df |>
group_by(education) |>
summarize(average = mean(yes)) |>
arrange(desc(average))
#
# education を tertiary = 4, primary = 1 にする
df <- df |>
mutate(education = case_when(
education == "tertiary" ~ 4,
education == "unknown" ~ 3,
education == "secondary" ~ 4,
education == "primary" ~ 1
))
df |>
summarize(correlation = cor(yes, education))
#
# default について
df |>
count(default) |>
mutate(prop = n / sum(n)) |>
arrange(n)
#
# default を yes なら 1 のダミー変数にする
df <- df |>
mutate(default = if_else(default == "yes", 1, 0))
df |>
summarize(correlation = cor(yes, default))
#
# balance について
summary(df$balance)
df |>
ggplot(aes(x = balance, fill = factor(yes))) +
geom_histogram()
#
# balance の箱ひげ図
ggplot(df, aes(x = yes, y = balance)) +
geom_boxplot(aes(group = yes))
#
# balance と yes の相関
cor(df$yes, df$balance)
#
# housing について
df |>
count(housing) |>
mutate(prop = n / sum(n)) |>
arrange(desc(n))
#
# housing を yes なら 1 のダミー変数にする
df <- df |>
mutate(housing = if_else(housing == "yes", 1, 0))
df |>
summarize(correlation = cor(yes, housing))
#
# loan について
df |>
count(loan) |>
mutate(prop = n / sum(n)) |>
arrange(desc(n))
#
# loan を yes なら 1 のダミー変数にする
df <- df |>
mutate(loan = if_else(loan == "yes", 1, 0))
df |>
summarize(correlation = cor(yes, loan))
#