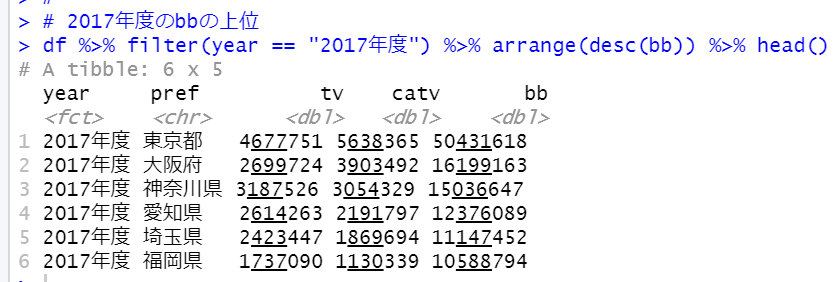
の続きです。
今回はR言語で階層的クラスタリングをしてみます。
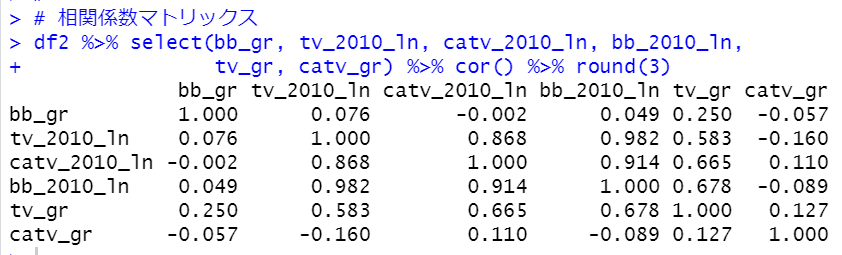
まず、select関数でtv_gr: テレビ放送受信契約数の伸び, catv_gr: ケーブルテレビ加入世帯数の伸び, bb_gr: ブロードバンドサービス契約数の伸びだけを選択して、as.matrix関数でマトリックスを作ります。

次にdist関数で各都道府県間の距離を計算します。

hclust関数で階層的クラスタリングを作成します。

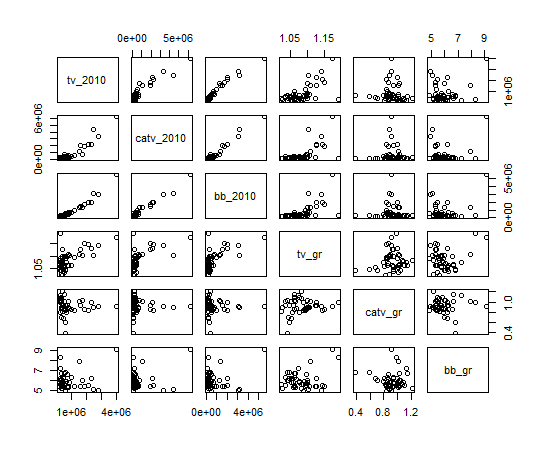
plot関数で視覚化します。


一番左に東京都があります。東京都は他の都道府県と大きく違うことがわかります。
ここからは、
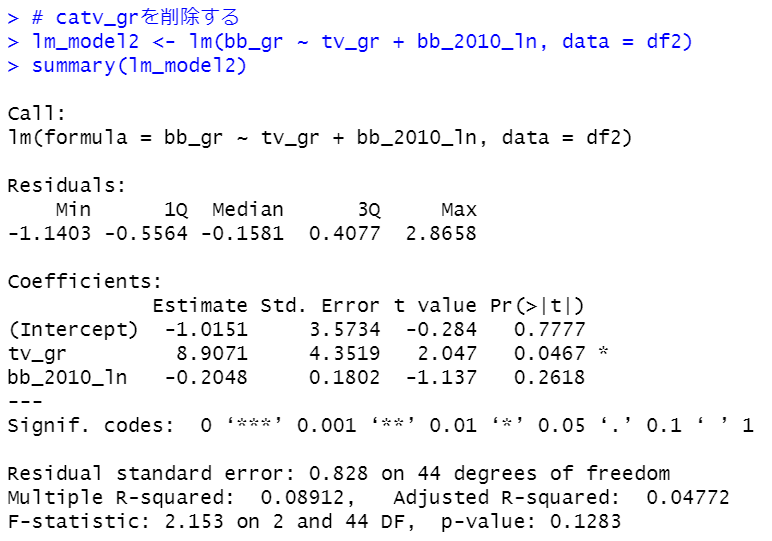
を参考にして、クラスタを4つに区切ってみます。cutree関数を使います。

作成したオブジェクトをデータフレームにします。

df2と作成したデータフレームをinner_join関数を使って結合します。

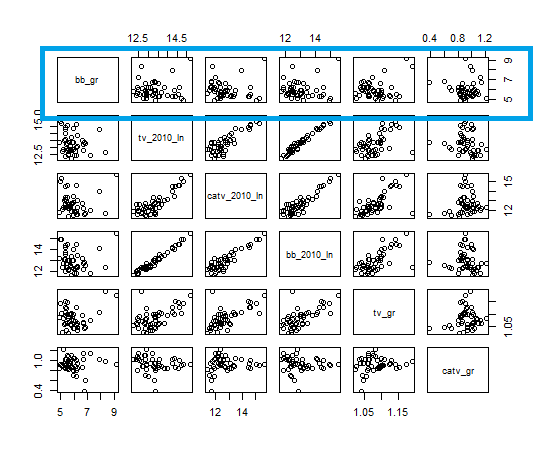
クラスタごとに色分けした散布図を描いてみます。
tv_grとcatv_grの散布図です。


tv_grとcatv_grではクラスタごとに散布していない感じですね。
tv_grとbb_grの散布図はどうでしょうか?


きれいにクラスタごとに分かれていますね。bb_grの数値で分けられている感じですね。
bb_grとcatv_grの散布図も見てみます。


cex = 8というのを加えて文字を大きくしてみました。縦軸がbb_grです。やはりbb_grの数値でクラスタリングされているようですね。
今回は以上です。
はじめから読むには、
です。



































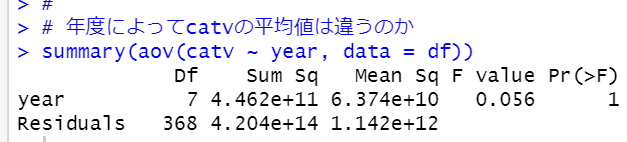


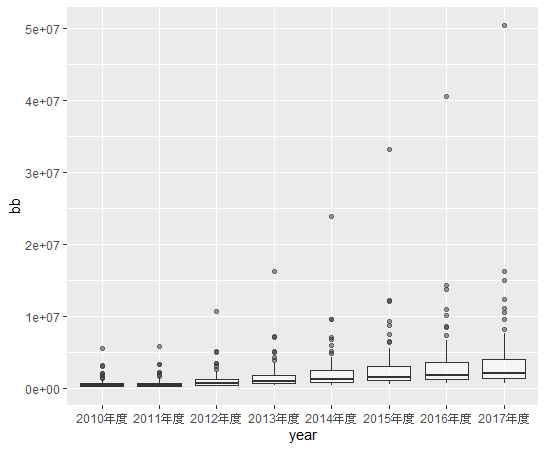
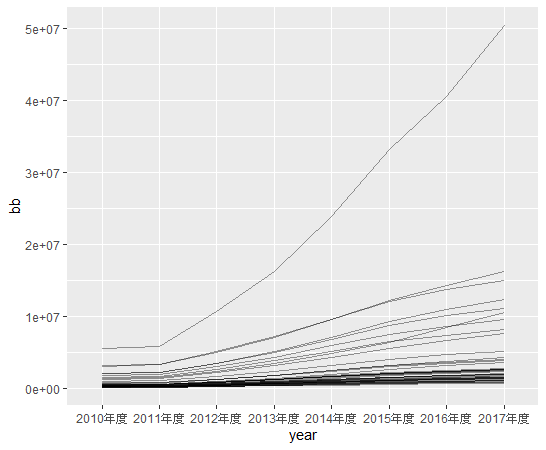
")






