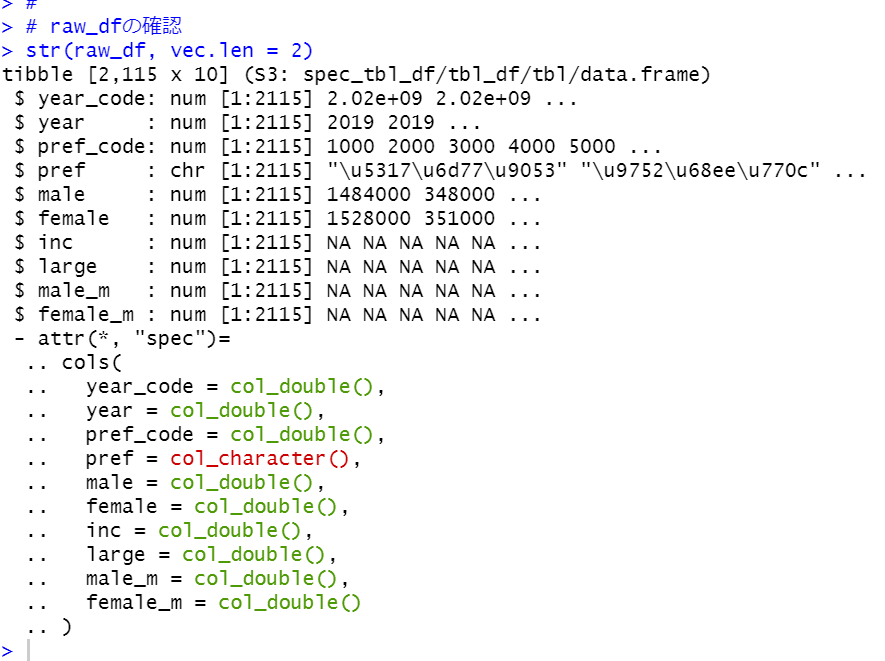
Photo by catrina farrell on Unsplash
の続きです。
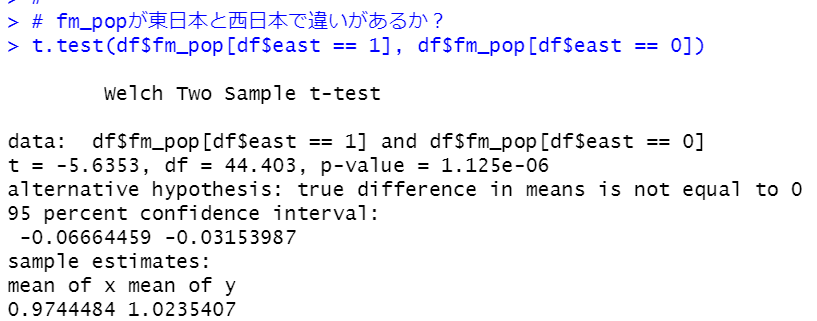
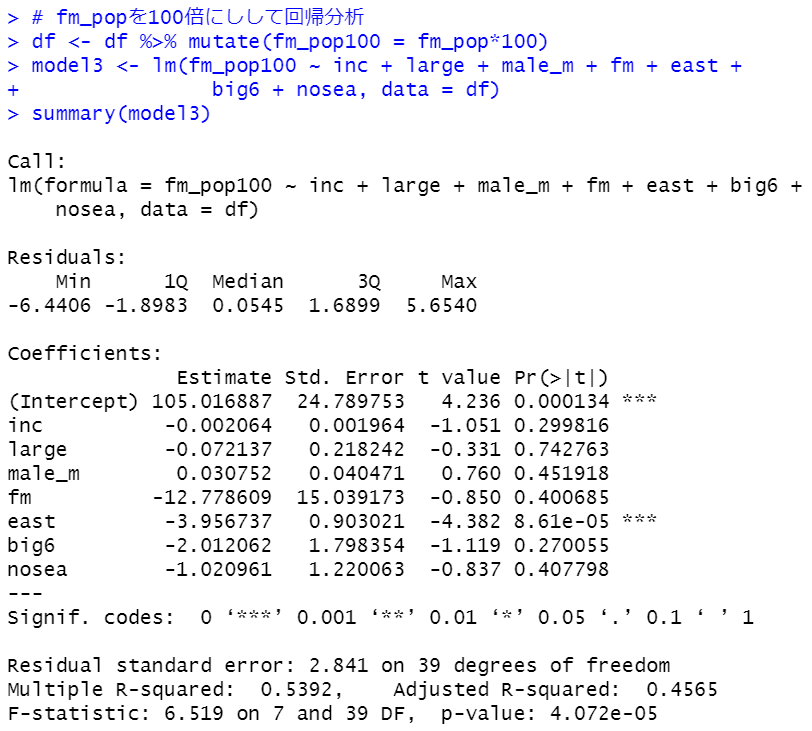
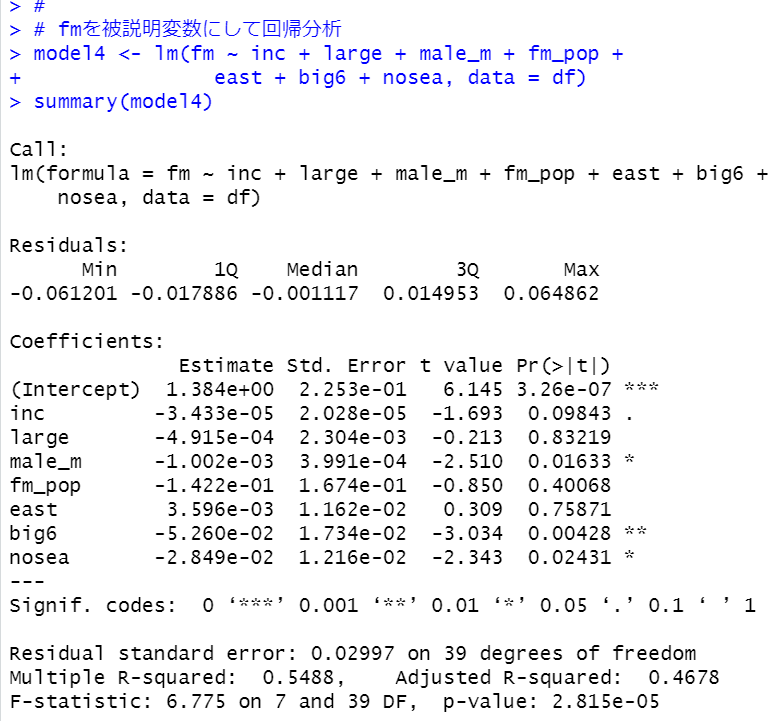
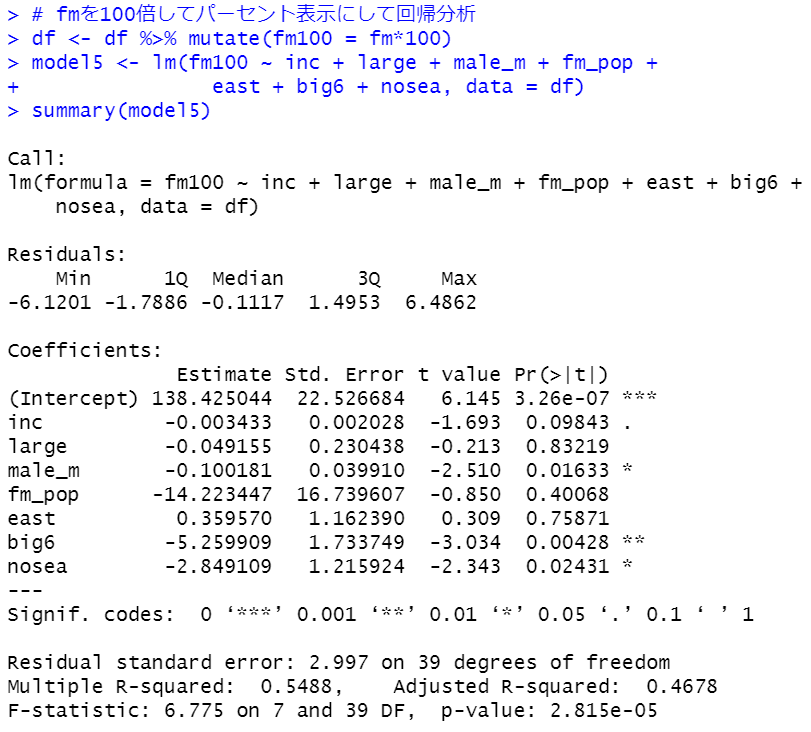
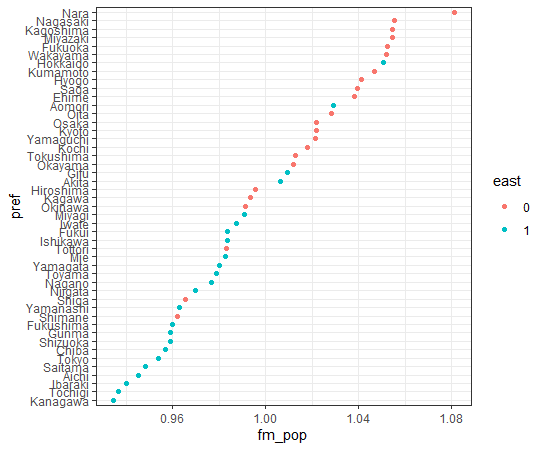
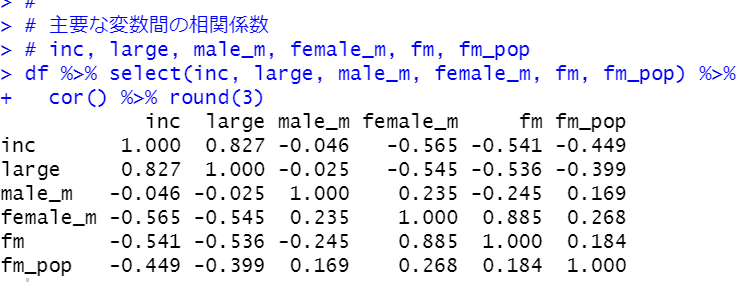
各都道府県の 女性(15~64歳)の人口 / 男性(15~64歳)の人口の比率は西日本のほうが高いとわかりましたが、東日本全体の女性(15~64歳)の人口/東日本全体の男性(15~64歳)の人口と、西日本全体の女性(15~64歳)/西日本全体の男性(15~64歳)の人口 では違いがあるのでしょうか?
まず、それぞれの合計人口数を計算しましょう。
まずは東日本全体の女性の人口です。

filter()関数でデータフレームを東日本だけにして、
summarize()関数でfemaleの合計を計算し、
pull()関数でそれを変数として取りだしています。
東日本全体の女性(15~64歳)の数は、2556万4000人です。
同じように、他の3つの人口も計算します。

東日本全体の男性の人口は、2651万8000人、
西日本全体の女性の人口は、1483万1000人、
日本全体の男性の人口は、1443万3000人です。
比率を計算します。

東日本は0.964で、西日本は1.03です。東日本は男性のほうが人口が多いですが、西日本は女性のほうが人口が多いです。
これは、統計的に有意な差があるのでかどうか、prop.test()関数で検定します。
prop.test(c(東日本の女性, 西日本の女性), c(東日本の人口, 西日本の人口))という構文です。

p-valueは2.2e-16とかぎりなく0に近いです。つまり、全体としても男女比率は東日本と西日本では違いがあることがわかりました。
今回は以上です。
次回は
です。
はじめから読むには
です。