")
日本の国会議員の様子を各種サーベイや公表資料からまとめたもの。
国会議員が戦後から全体としてどのように変化してきているのかを、人材、選挙、政策形成、価値観、政治資金の面からとらえようとしている。
日本の国会議員の様子を各種サーベイや公表資料からまとめたもの。
国会議員が戦後から全体としてどのように変化してきているのかを、人材、選挙、政策形成、価値観、政治資金の面からとらえようとしている。

Photo by Dan Freeman on Unsplash
の続きです。
前回の分析で月別や年別に物価に違いがあることがわかりました。
今回は統計的にその違いが有意なのかどうかを確認します。

lm()関数で回帰分析のモデルを作りました。

carパッケージの読み込みをしました。
carパッケージは、Companion to Applied Regression の略で回帰分析で便利な関数がいろいろあります。

lmtestパッケージの読み込みをしました。
lmtestパッケージは、Testing Linear Regression Modelsの略というかそういうパッケージで回帰分析に使う検定がいろいろできるものです。
まずは、coeftest()関数を使って、lm()関数で作成した回帰分析モデルをみてみます。

2000年がベースになっています。
Interceptが2000年のl_priceの平均値です。
これを見ると、どの年も有意ではないようです。
year全部を考えると有意なのかどうかを検定してみます。

carパッケージのmatchCoefs()関数で帰無仮説 myH0を作成して、
linearHypothesis()関数でこの帰無仮説をF検定しています。
p値は1ですので、帰無仮説は棄却できません。
つまり、yearは統計的に有意な違いが無い、ということです。
同じように、monthでもやってみます。

monthも統計的には有意な変数ではなさそうです。
F検定でmonth全体の有意かどうかを検定します。

こちらのp値は1なので帰無仮説を棄却できません。
monthも統計的に有意な変数ではありませんでした。
今回は、
「Using R for Introductory Econometrics」の第4章、Multiple Regression Analysis: Inference を参考にしました。
今回は以上です。
次回は、
です。
初めから読むには、
です。

Photo by Simon Maage on Unsplash
の続きです。

このように、name_codeに対応して、sinryou_kenpoのようにそれを表す名前を付与したCSVファイルを作成しました。
これをRに読み込みます。

このデータフレームを前回作成してあるdata_fullsと結合させます。
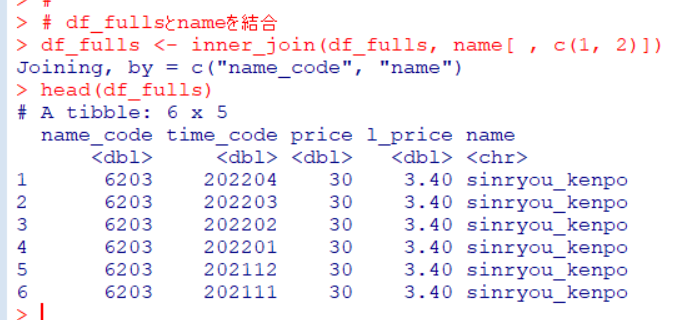
inner_join()関数で結合しました。
arrange()関数を使って価格の高い順に表示してみます。

一番高いのは、car_gaisha, つまり輸入自動車でした。600万円越えの価格のものは外車だったのですね。
一番安いのは何でしょうか?

一番安いのは電話の通話料でした。8.93円とあります。
品目別の平均価格を見てみます。


tapply()関数で品目別の平均価格を算出して、sort()関数で並び替えてから、barplot()関数でグラフにしました。
自動車の次に高いのはピアノですね。
どれが価格の変動が激しいのか、変動係数(CV)を品目別の算出してみます。


変動係数は、標準偏差 / 平均値なので、まず、function()関数で変動係数を計算するカスタム関数を作ってから、tapply(), sort(), barplot()関数で同じように棒グラフにしています。
par(mai = c(0.5, 1.8, 0.5, 0.5))はグラフの余白を調整するものです。
国語の参考書が変動が激しく、封書や電話配線が安定していることがわかります。
時間軸別の平均価格をグラフにしてみます。


average <- の行で時間軸別の平均価格(対数変換)を算出しています。
yyyymmdd <- の行で時間軸のラベルを作成しています。
そして、plot()関数でグラフにしました。
2010年頃が価格が落ち込んでいるのと、突出して価格が高くなっている月があることが伺えます。
年別、月別の平均価格も見てみます。


1行目はstr_sub()関数でtime_codeのはじめの4文字だけを抜き出しています。
2行目は、tapply()関数でyearごとの平均値を算出しています。
3行目は、table()関数とname()関数でyearを各年一つだけにしています。
そしてplot()関数でグラフにしました。2010年が落ち込んで、そこから回復しています。
同じように月別の平均価格を見てみます。


5,6,7月が価格が低い時期ですね。11月、12月は高いです。
平均価格で安いときは41万4500円ぐらい、高いときは41万7500円ぐらいと3000円ぐらいの違いです。
今回は以上です。
次回は
です。
初めから読むには、
です。

Photo by Leo Mendes on Unsplash
の続きです。
前回はCSVファイルのデータをRに読み込ませました。
今回はデータを分析しやすいように整えます。
やるべきことは3つありました。
1。NAの行を削除する
2。title_code, title, name, time, data_typeを削除する
3。time_codeをYYYYMM形式に直す。
それではまず、NAの行を削除しましょう。

新しく分析用にdfというデータフレームを作成して、filter()関数の中で、is.na()関数を使ってname_codeがNAの行とpriceがNAの行を削除しました。
次は、不要な変数を除外します。

select()関数で不要な変数を除外しました。
最後は、time_codeをYYYYMM形式に直します。

はじめにYYYYMM形式にするカスタム関数を作成しました。str_sub()関数ではじめの4桁と最後の2桁を抽出して、paste0()関数でその二つを結合し、as.numeric()関数で数値型に変換しています。
このカスタム関数とmutate()関数でtime_codeをYYYYMM形式に変換しています。
summary()関数でサマリーを表示しています。name_codeは銘柄コードなので見てもあまり意味はないです。
time_codeを見ると、最小値は200002なので2000年2月からデータがあり、最大値が202204なので、2022年4月までデータがあることがわかります。
priceは最小値が0で最大値が6,002,690です。600万円の物って何でしょうね?
とりあえず、priceのデータがどんなものなのか、ヒストグラムや箱ひげ図などで視覚化してみます。


ほとんどの物は低価格なのですが、ほんの少数が600万円など高い物だとわかります。
そうだ、全部の時間軸(月)でデータがあるものだけに絞り込みます。

時間軸は267あることがわかりましたので、267個データの無い銘柄は欠損していることがわかります。

28個の銘柄が267の時間軸(月)全てそろっていることがわかります。

filter()関数と %in% でname_codeがfullsの中に含まれているものだけに絞り込みました。267*28=時間軸(月)の数*銘柄の数=7476なので、うまくできていることがわかります。
このdf_fullsのサマリーを見てみます。

最高価格6,002,690円の商品はこのデータフレームに残りました。最小価格は9円です。
それでは、このpriceを視覚化しましょう。こんどは対数に変換してから視覚化します。


対数変換したほうが分布がわかりやすいですね。いちいちlog()関数で対数にするのは面倒なので、対数変換した価格を変数に加えましょう。

今回は以上です。
次回は、
です。
はじめから読むには、
です。

Photo by Jeremy Thomas on Unsplash
政府統計の総合窓口、e-statのサイトを見ると、小売物価統計のデータベースが更新されたようです。

今回はこのデータをダウンロードして分析してみます。

小売物価統計調査(動向編)というのが更新されたようです。

月次[2件]が更新されたようです。

全国統一価格の月別価格のほうをダウンロードしてみます。

こんな感じのファイルです。15行目に変数名を挿入しました。
このCSVファイルをR言語で読み込んで、分析します。
まずはじめに、tidyverseパッケージを読み込んでおきます。

read_csv()関数でファイルを読み込みます。

なんとか読み込んだようです。
str()関数でデータ構造を確認します。

日本語は文字化けしてしまうのですが、38,736行、8列のデータフレームです。
一つ一つの変数を見ていきます。
まずは、title_code: 表章題目コードです。

最小値から最大値まですべて10ですね。つまり、この変数は全部10という値ということです。なので、この変数は削除してもかまわないですね。後で除外します。
次は、title: 表章題目です。

これは文字化けしていますが、価格という一つの言葉しかないようです。これもあとで除外します。
次は、name_code: 銘柄コードです。

銘柄コードがNAの行が386あるのと、銘柄コードの種類は300あることがわかりました。後でNAの386行は削除しましょう。
次は、name: 銘柄です。
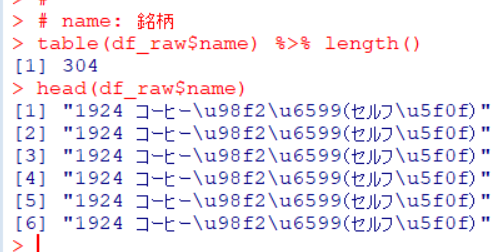
nameは304種類あるようです。でも文字化けしているので、これも後で除外します。
次は、time_code: 時間軸(月)コードです。

267種類あるということは、267/12=22.25ですから、22年と3か月分のデータがあるのですね。2000年2月から2022年4月までのようです。time_codeは後で200002, 202204のように直しましょう。
次は、time: 時間軸(月)です。

267種類あるのはtime_codeと一致しています。文字化けしていますので、これも後で除外しましょう。
次は、data_type: データの種類です。

これは全部NAだったんですね。これも後で削除します。
最後は、price: 価格です。

NAの行が838行あります。最小値が0円で最大値が6,002,690円です。NAの行は削除しましょう。
これで全部の変数のチェックは終わりました。
これからやるべきことは、
1. NAの行を削除
2. title_code, title, name, time, data_typeの除外
3. time_codeをYYYYMMに直す。
の3点です。
これは次回やりましょう。
今回は以上です。
次回は、
です。

Photo by Gaetano Cessati on Unsplash
HistDataパッケージのLangrenは17世紀の数学者・天文学者のMichael Florent van Langrenのデータです。この当時、天文学上の大きな問題の一つであった経度の正確な測定について仕事をした人です。
データを呼び込みます。

データは2つあって、Langren1644とLangren.allです。
Langren1644は12行9列のデータフレーム、Langren.allは61行4列のデータフレームです。
この後、ヘルプのコードを実行してみたのですが、何故か動かなかったので、今回はしょうがないですが、Langren1644のデータを使って、各都市をプロットしてみました。


なんか、各都市の位置関係が微妙におかしい感じがします。
今回は以上です。
以下が今回のコードです。
# 2022-05-05
# HistData_Langren
#
library(HistData)
data(Langren1644)
str(Langren1644)
data(Langren.all)
str(Langren.all)
#
with(Langren1644, plot(Longitude, Latitude, type = "n",
ylim = c(30, 57), xlim = c(15, 34)))
with(Langren1644, text(Longitude, Latitude, City))

Photo by Marek Piwnicki on Unsplash
This post is following of above post.
In this post, I will do some classification methods.
Firstly, I make binary variable.

I made a binary variable named high, that shows 1 when lpc_gdp is hgher than the mdeian and 0 when lower than median.
Before making models, I load caret package/
Then, I make LPM: Linear Probability Model, which is liear regression model with OLS estimate.
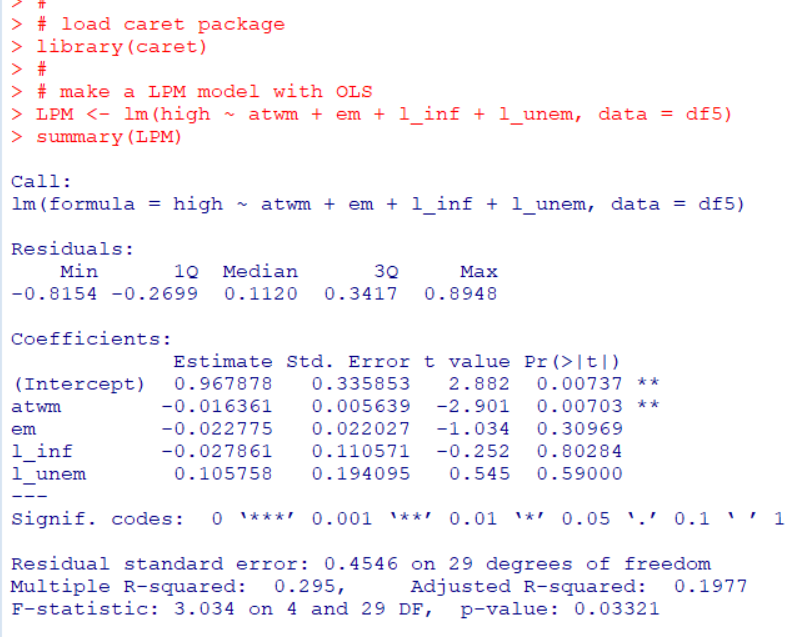
"atwm": Attitides Towards Working Mother is only significant variable.
Then, make a prediction and calculating how much prediction is correct.
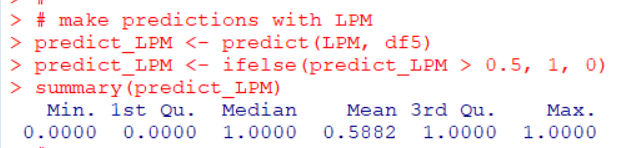
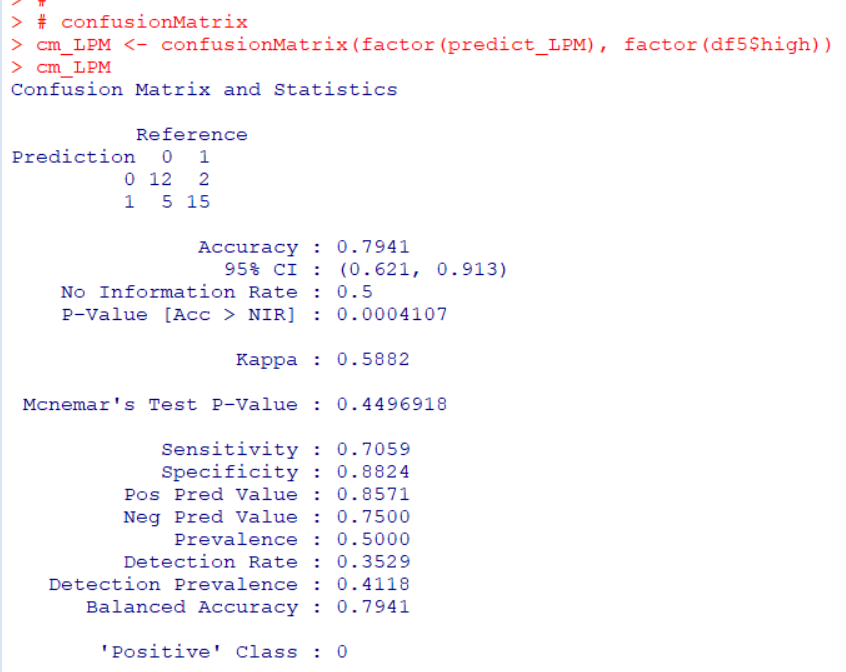
Accuracy is 0.7941. This means 79.4% is correctly predicted.
Next, I use SVM: Support Vector Machine. I use e1071 package svm() function.

with SVM model, what is accuracy?

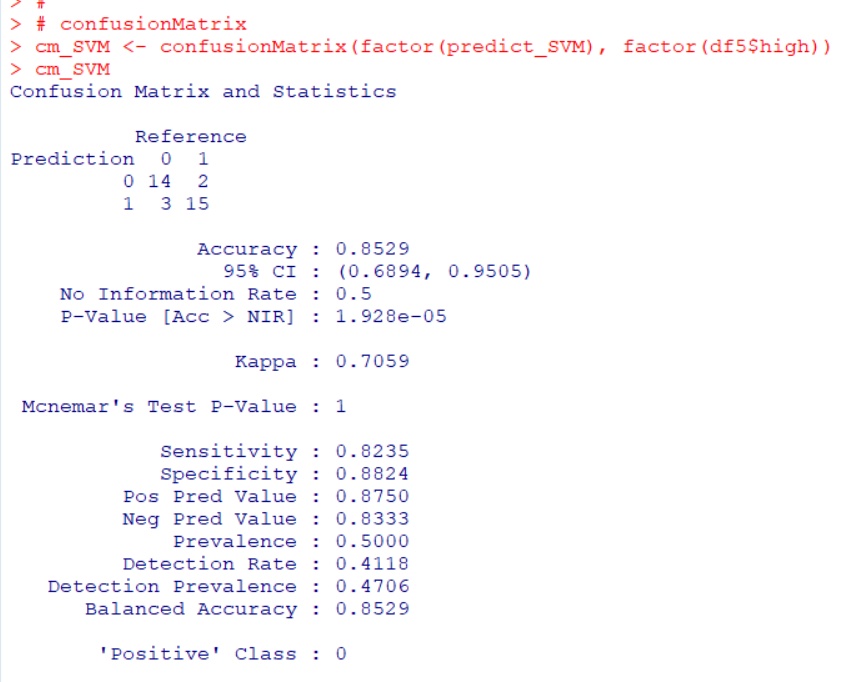
Accuracy is 0.8529. So SVM is betther than LPM.
Next, I use GAM: Generalized Additive Model. I use gam() function in mgcv package.

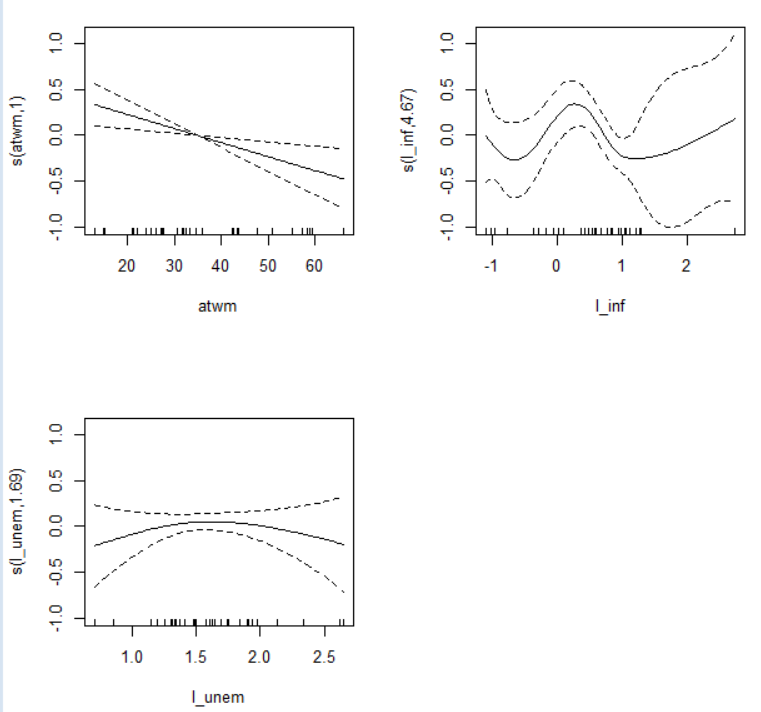
In GAM, s(atwm) and s(l_inf) are significant variables.
Let's plot GAM model.

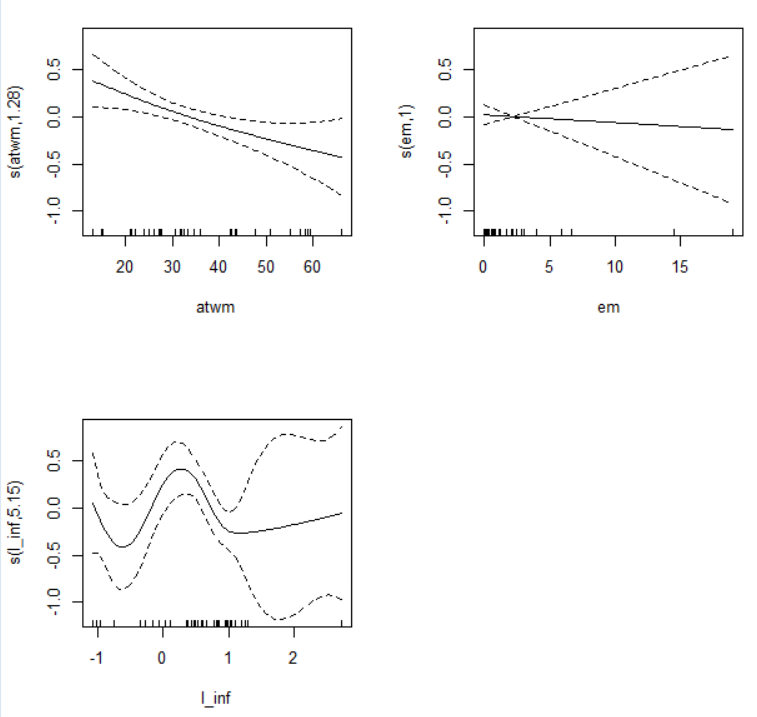
The plot shows s(em) is not needed s().
So, let' make another GAM model, this time s(l_unem).
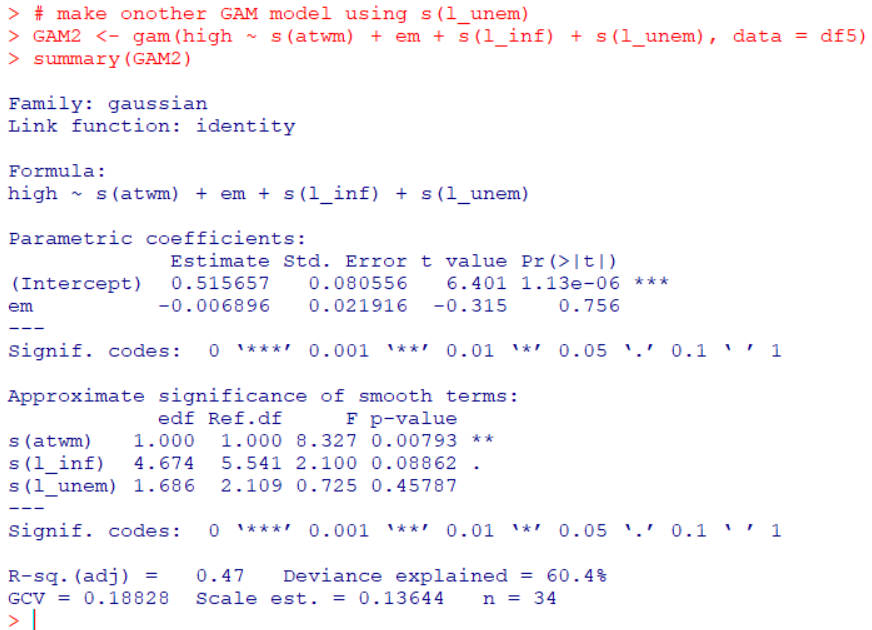
plot GAM2

Let's make predictions with GAM model

Let's get accuracy og GAM.
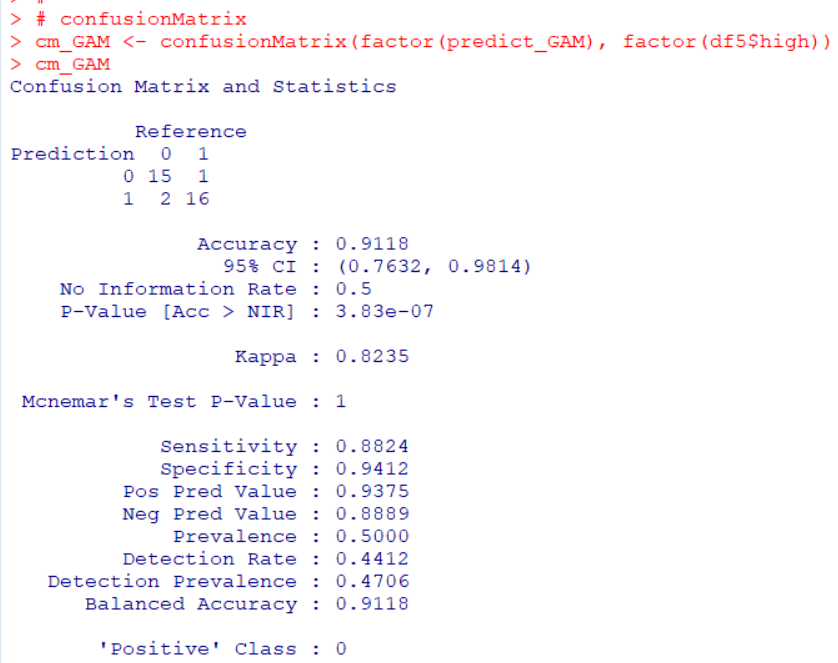
Accuracy us 0.9118.
How about GAM2 model?
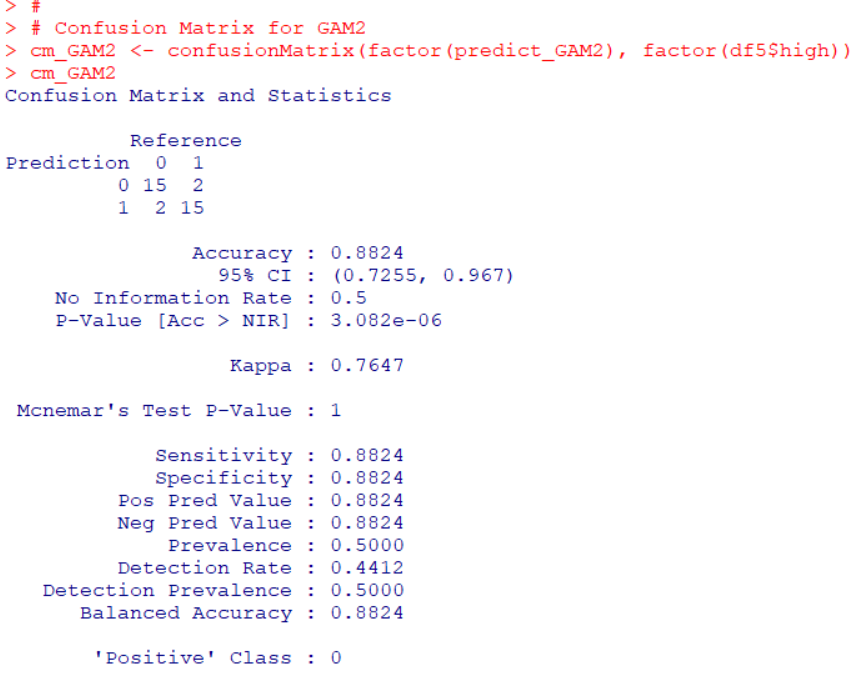
Accuracy is 0.8824. So, the fist GAM model is better.
Next, I use tree model.

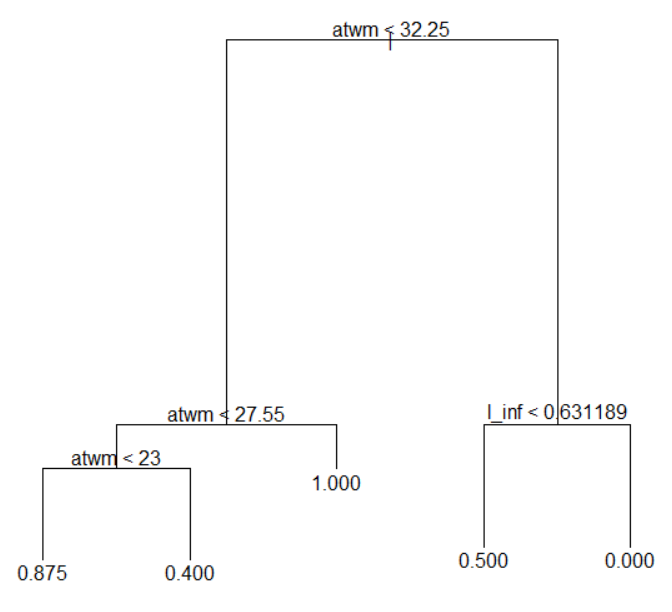
I use tree() function in tree package. In this model, "atwm" is the most important variable and l_inf is next. Others are not important.
Let's get accuracy of tree model.

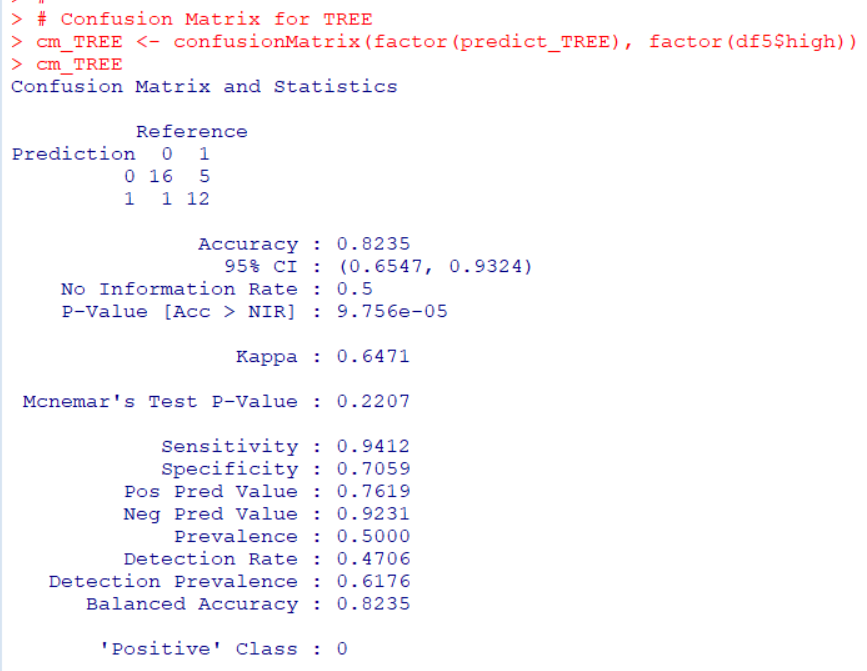
Accuracy is 0.8235.
Next, I use k-NN model.
I use knn3() function in caret package.
Let's get accuracy of knn.
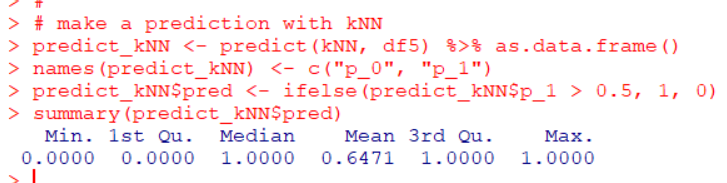
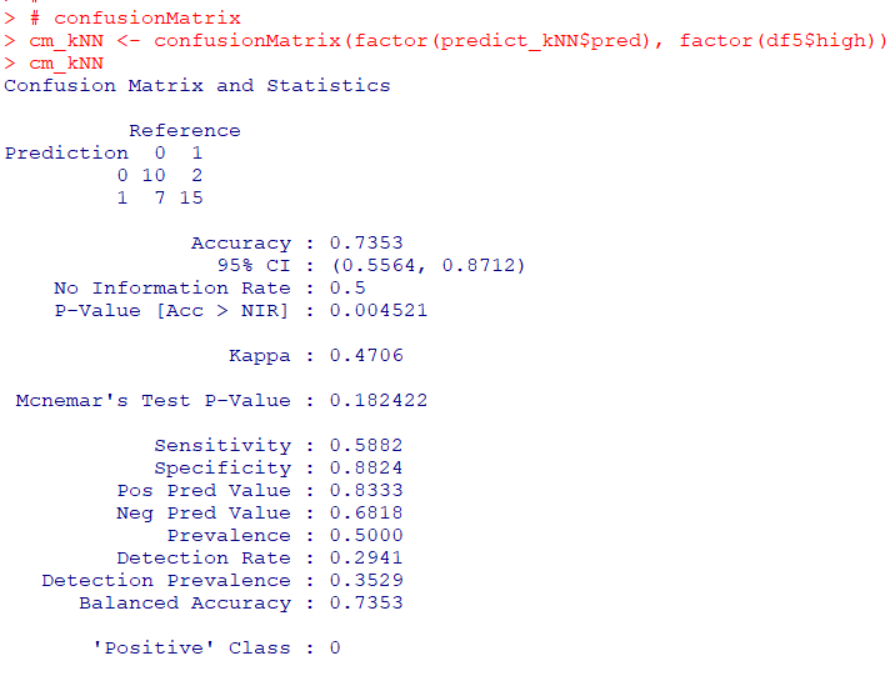
Accuracy is 0.7353.
Then, let's compare those methods accuracy.

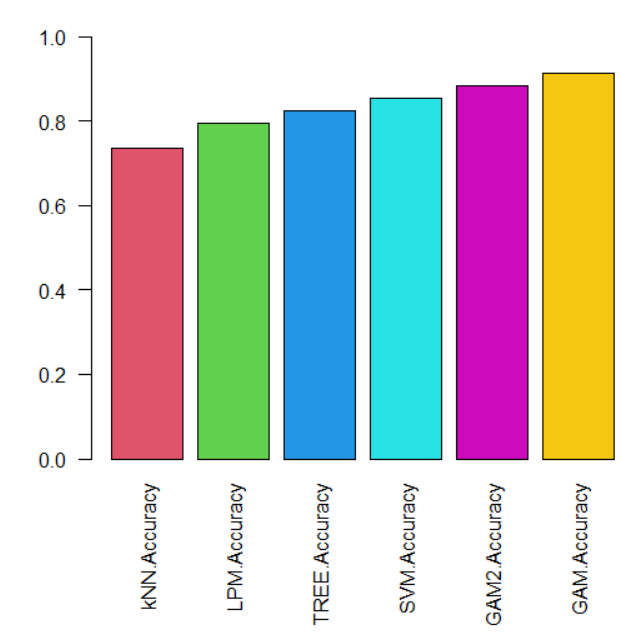
GAM model has the highest accuracy.
That's it. Thank you!
To read the 1st post
