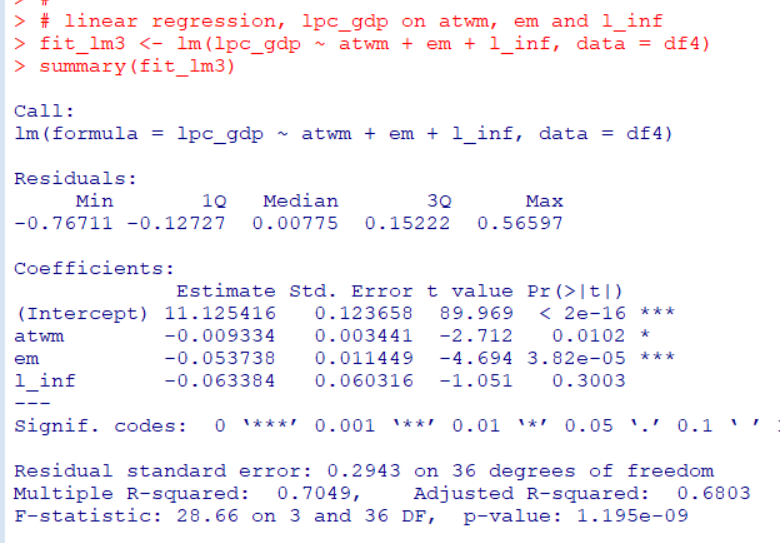
Photo by Setu Chhaya on Unsplash
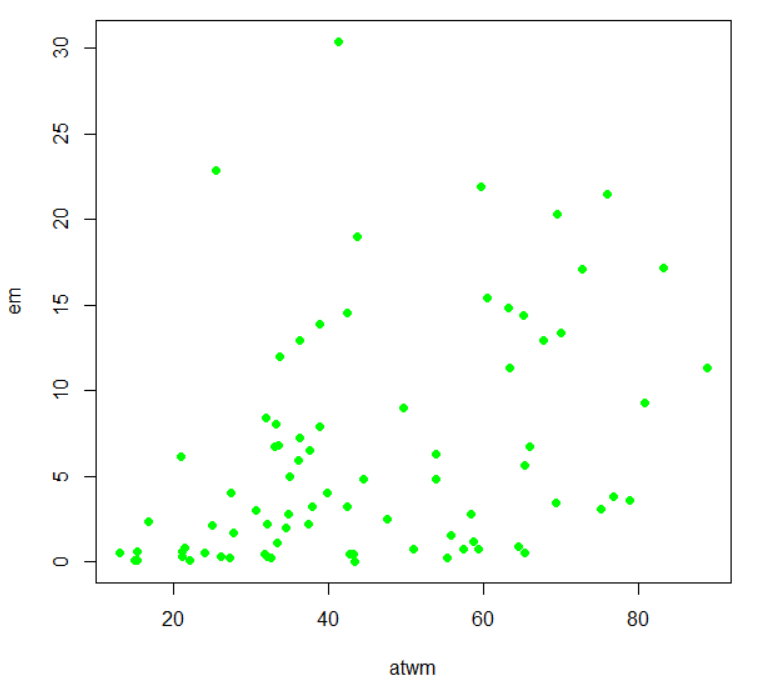
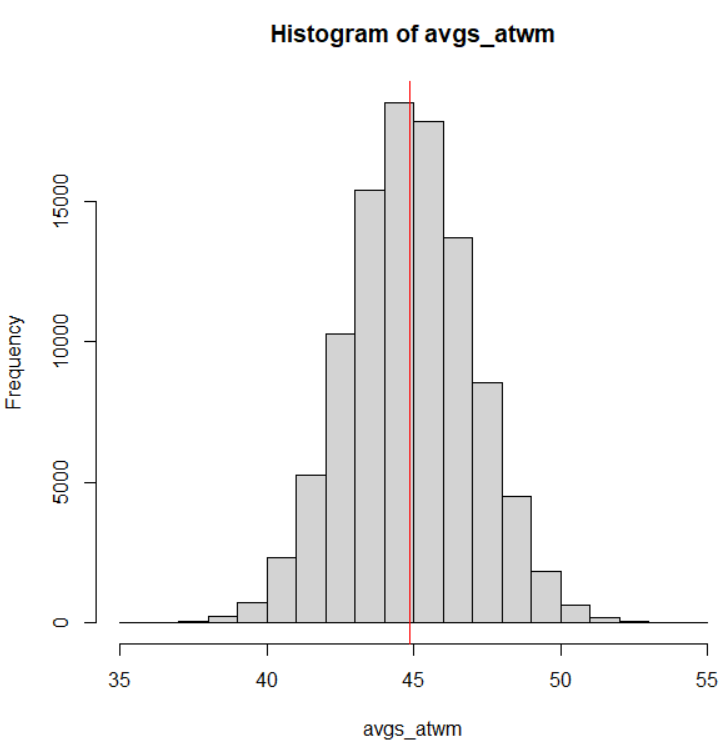
HistDataパッケージのJevonsというデータは、1871年のNatureという雑誌に掲載されたW. Stanley Jevonsの実験のデータです。
黒いビーズを複数個、パッと見せて、何個だったか答えさせるという実験です。人間が一度に認識できる数がどのくらいか、というのを調べる実験です。一般に7個前後、と言われていますね。
早速データを見てみます。

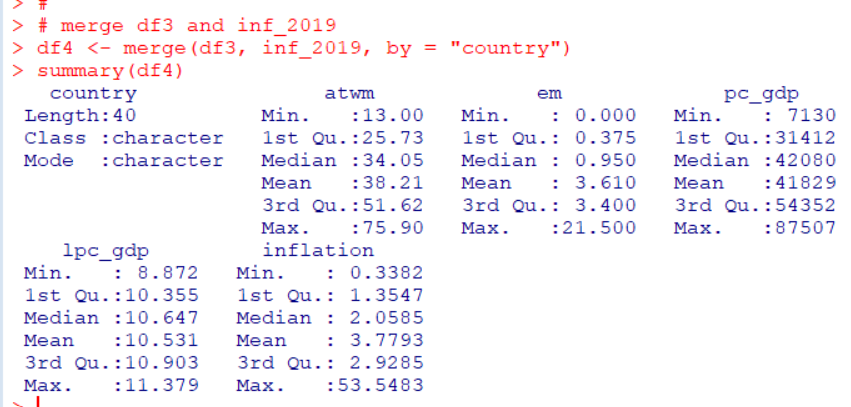
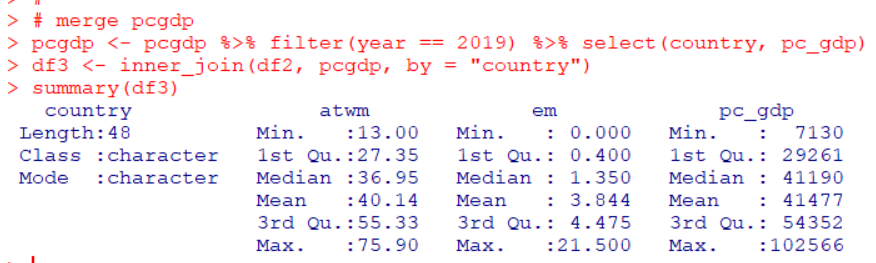
actual が実際のビーズの数、estimatedが答えた数、frequencyは度数、errorは誤差ですね。
一番始めの行は、actual:3, estimated:3, frquency:23, error:0 なので、実際のビーズが3のとき、3と答えたのが23回あって、誤差は0だった、という意味です。
ヘルプのコードを実行していきましょう。
はじめは、xtabs()関数で表を作っています。

ビーズが、3つ、4つのときは全部正解していますが、5つのときは102回正解で、5回間違っていますね。15個のときは正解は2回で9回間違っています。
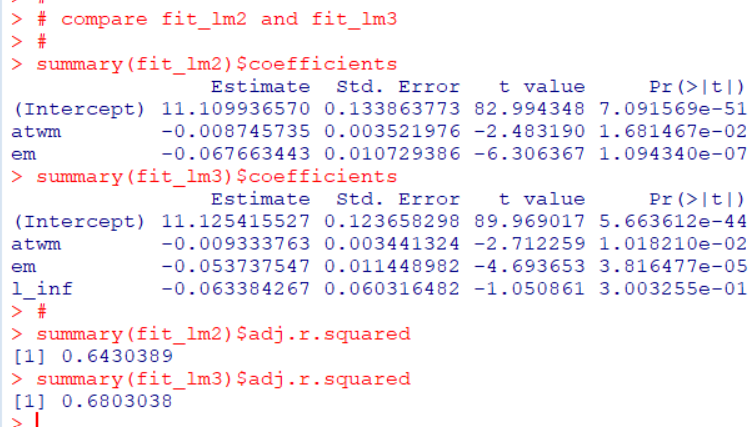
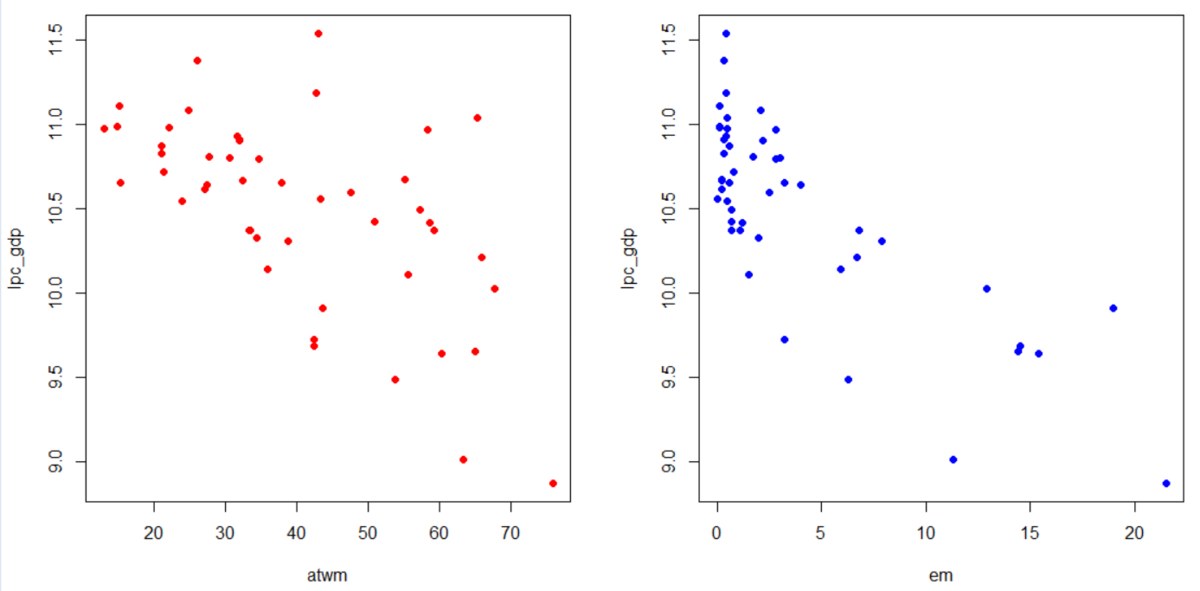
次のヘルプのコードは、サンフラワープロット、sunflowerplot()関数です。


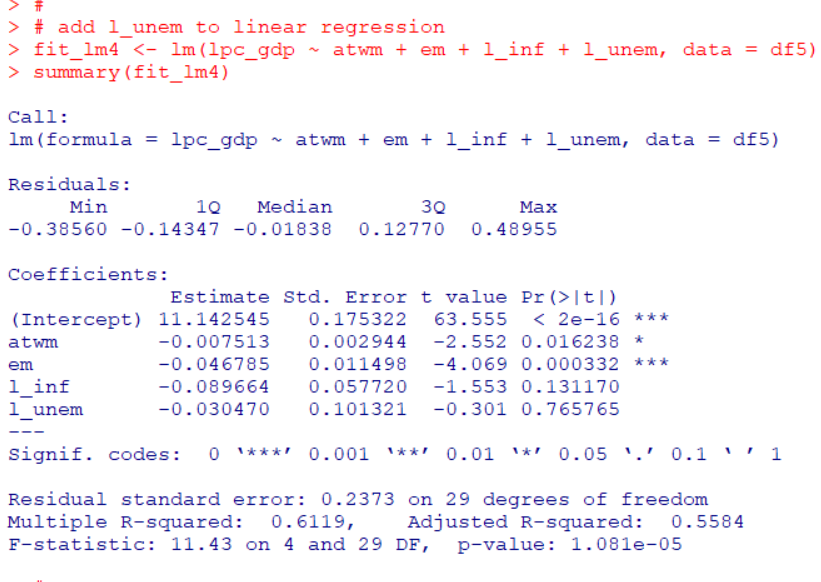
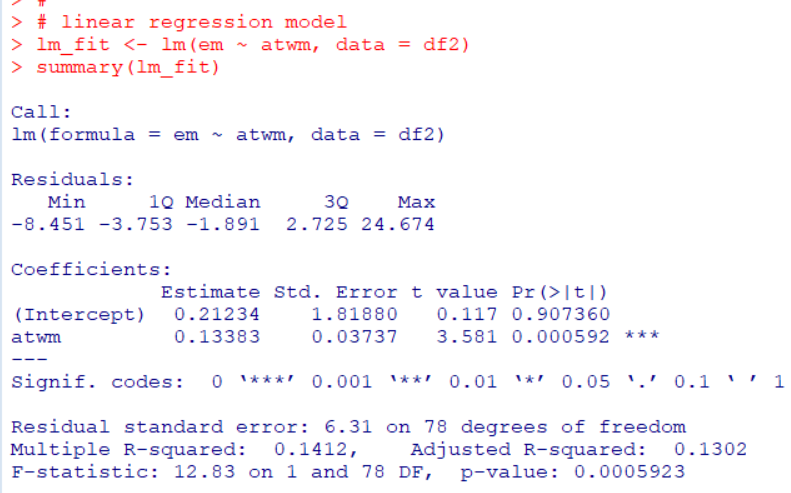
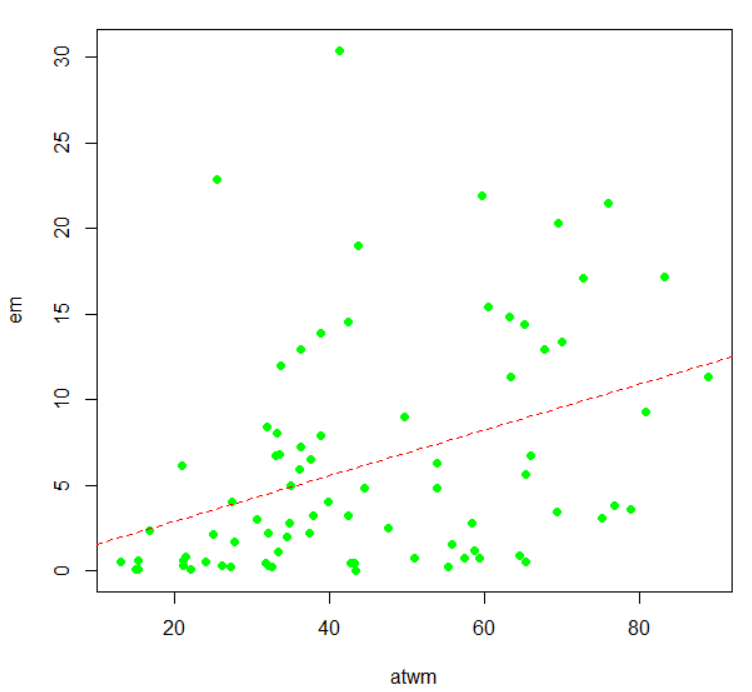
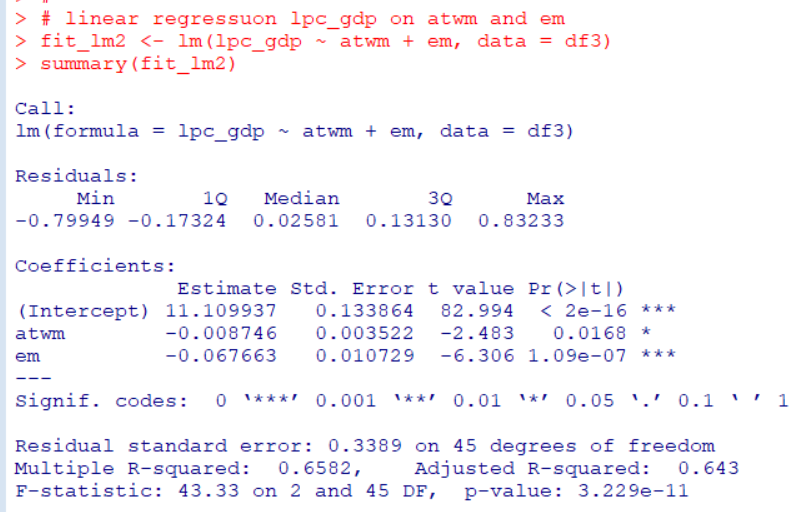
lm()関数で回帰直線モデルを作って、abline()関数でその直線を描いています。
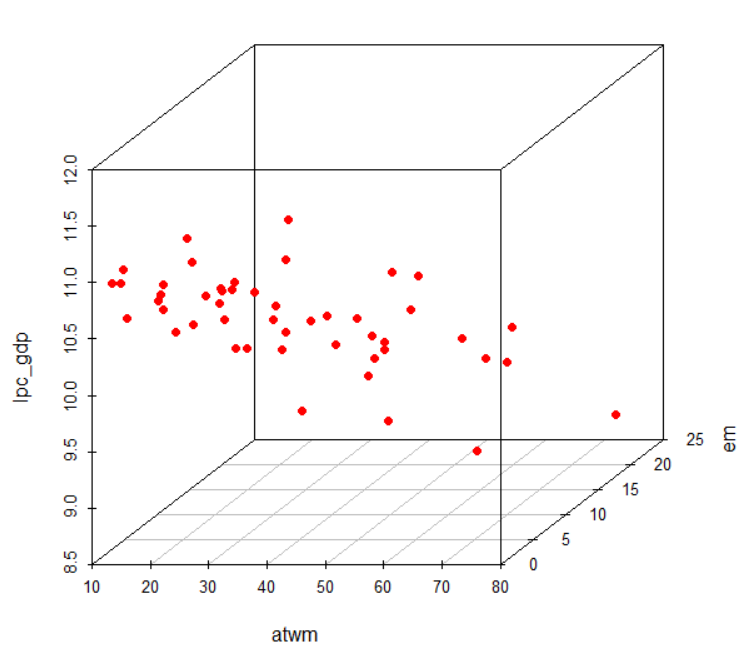
次は、gplotパッケージのbaloonplot()関数を使っています。



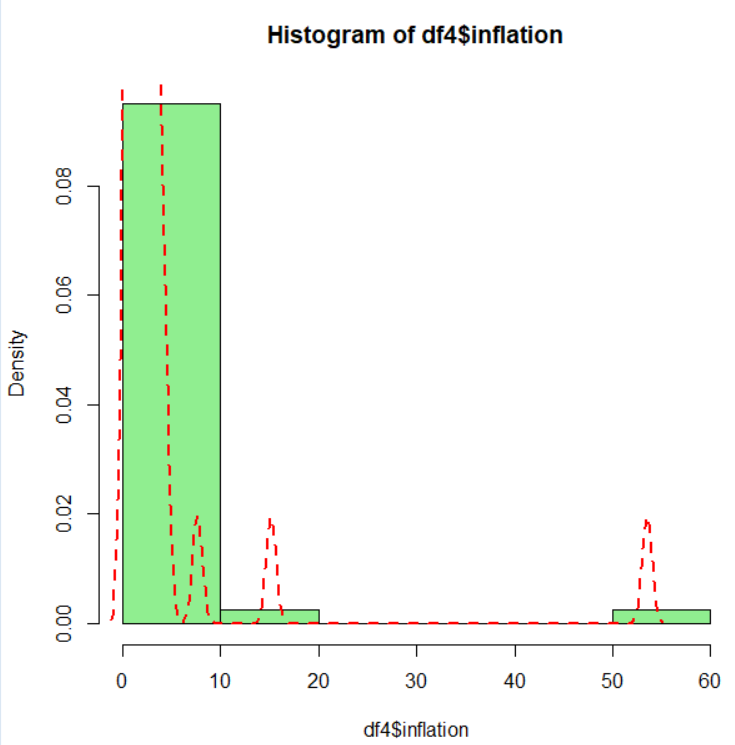
 そして、最後は、平均の誤差をグラフにしています。
そして、最後は、平均の誤差をグラフにしています。

reshapeパッケージのuntable()関数でfrequencyの数だけ実際の観測を作って、テーブルのデータを生データにしています。例えば、actual:3, estimated:3はfrequencyが23でしたので、actual:3, frequency:3の行を23行作っています。
そして、plyrパッケージのddply()関数でactualごとのerrorの平均を計算して、plot()関数でグラフにしたようです。
reshapeパッケージやplyrパッケージを使わなくてもできそうな気がします。
やってみましょう。


rep()関数とデータフレームの行を指定する方法を応用してuntable()と同じことができますし、tapply()関数がddply()関数と同じことができました。
今回はこれでおしまいです。
以下が今回のコードです。
# 2022-05-01
# HIstData_Jevons
#
library(HistData)
data("Jevons")
str(Jevons)
#
# show as tables
xtabs(frequency ~ estimated + actual, data = Jevons, subset = NULL)
xtabs(frequency ~ error + actual, data = Jevons, subset = NULL)
#
# show an sunflowerplot with regression line
with(Jevons,
sunflowerplot(actual, estimated, frequency,
main = "Jevons data on numerical estimation"))
Jmod <- lm(estimated ~ actual, data = Jevons, weights = frequency)
abline(Jmod, col = "green", lwd = 2, lty = 2)
#
# show as balloonplots
library(gplots)
with(Jevons,
balloonplot(actual, estimated, frequency, xlab = "actual",
ylab = "estimated",
main = "Jevons data on numerical estimation: Errros
Bubble are area propotional to frequency",
text.size = 0.8))
with(Jevons,
balloonplot(actual, error, frequency, xlab = "actual",
ylab = "error",
main = "Jevons data on numerical estimation:
Errors Bubble are propotional to frequency",
text.size = 0.8))
#
# plot average error
library(reshape)
unJevons <- untable(Jevons, Jevons$frequency)
str(unJevons)
str(Jevons)
library(plyr)
mean_error <- function(df) mean(df$error, na.rm = TRUE)
Jmean <- ddply(unJevons, .(actual), mean_error)
with(Jmean,
plot(actual, V1, ylab = "Mean error", xlab = "Actual number",
type = "b", main = "Jevons data"))
abline(h = 0, col = "red", lty = 2, lwd = 2)
#
# reshapeパッケージ、plyrパッケージを使わずに再現する
n <- nrow(Jevons) # Jevonsの行数
index <- rep(c(1:n), Jevons$frequency) # Jevonsのx番目の行を何回繰り返すか
Jevons2 <- Jevons[index, ] # untable()と同じことをしている
Jmean2 <- with(Jevons2, tapply(error, actual, mean, na.rm = TRUE)) # actual
# ごとのerrorの平均値を計算
plot(Jmean2, type = "b", pch = 16, col = "blue", cex = 2,
xlab = "Actual number", ylab = "Mean error",
main = "Jevons data") # グラフ作成
abline(h = 0, col = "red", lty = 2, lwd = 2) # 0の水平線を追加