今回は都道府県別のデジタル教科書の整備率のデータの分析をしてみようと思います。
データは、政府統計の総合窓口(www.e-stat.go.jp)から取得しました。

47都道府県を選択し、

デジタル教科書の整備率と関連のありそうな教育用コンピュータ1台当たりの児童数のデータも選択しました。
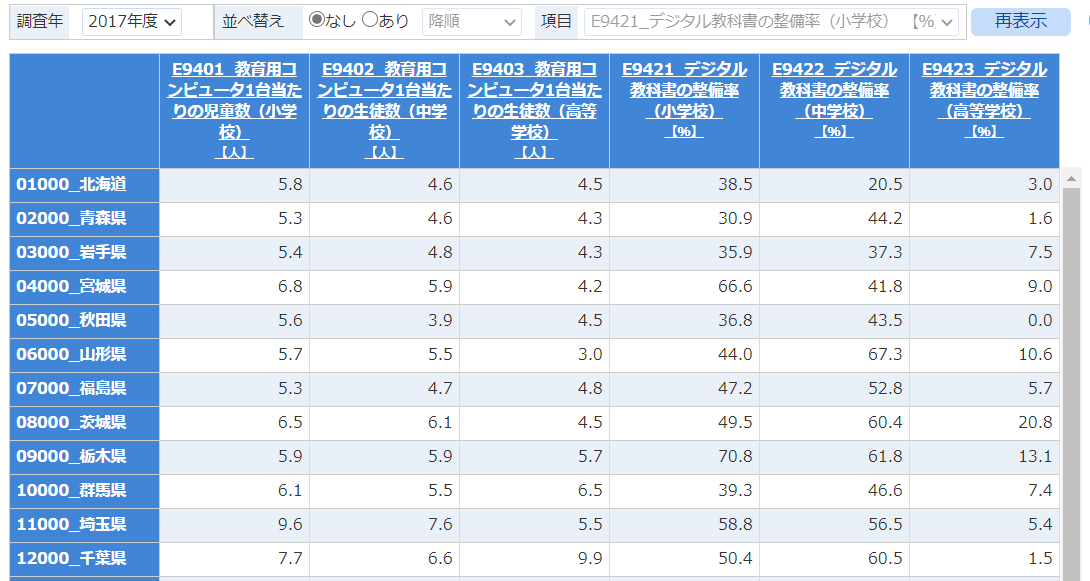
このようなデータです。
これをCSVファイルに出力しました。

9行目に変数名を挿入しています。
これをR言語のread_csv関数で読み込みます。

read_csv関数でCSVファイルを読み込みます。

skip = 8 で9行目から読み込むように、
na = c("***", "X", "-") で***, X, - はNAとするように、
locale = locale(encodding = "UTF-8")でUTF-8がエンコードだと指定しています。
year: 調査年度
pref: 都道府県名
pc_s: 教育用コンピュータ1台当たりの児童数(小学校)(人)
pc_c: 教育用コンピュータ1台当たりの児童数(中学校)(人)
pc_h: 教育用コンピュータ1台当たりの児童数(高等学校)(人)
dg_s: デジタル教科書の整備率(小学校)(%)
dg_c: デジタル教科書の整備率(中学校)(%)
dg_h: デジタル教科書の整備率(高等学校)(%)
です。
raw_dfは原データなので、とっておいて分析用のデータフレームを作ります。
とりあえず、NAの行をna.omit関数で削除して、yearとprefをファクター型に変換します。

summary関数で基本統計量をみてみます。

デジタル教科書の整備率は小学校、中学校、高等学校で最大値が100ですから100%整備した都道府県があるということですね。
平均値は小学校が49.4%, 中学校が53.5%, 高等学校が11.78%となっています。高等学校は整備が遅れているようです。
コンピュータ1台当たりの児童数は、高等学校が最小で0.7と児童数よりもコンピュータの台数が多いところがあるようです。
平均値は小学校が6.446人, 中学校が5.708人, 高等学校が4.924人と高等学校のほうがコンピュータは普及しているようです。
今回は以上です。
次回は
です。