
Bing Image Creatorで生成: Photo, Spring Landscape, quiet flower garden
今回は、都道府県別の水質汚濁物質排出量総合調査のデータを分析してみようと思います。政府統計の総合窓口(www.e-stat.go.jp)からデータを取得します。
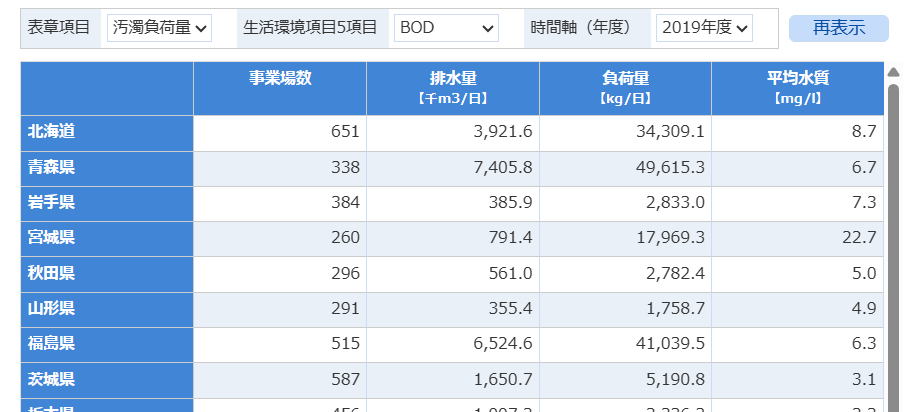
こんな感じのデータです。
これをExcelに出力します。
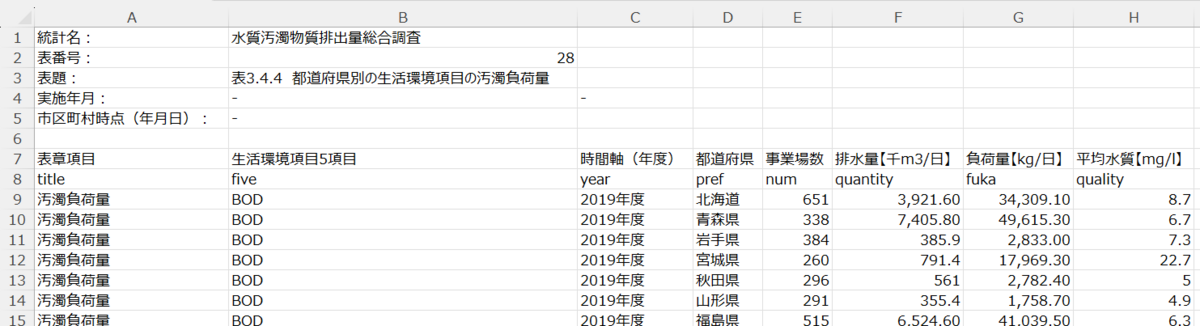
8行目に変数名を挿入しました。
これを、R に読み込んで分析します。
まず、tidyverse パッケージの読み込みをします。
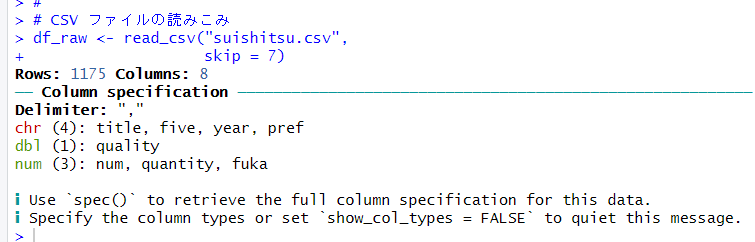
read_csv() 関数でCSVファイルのデータを読み込みます。
glimpse() 関数でデータの様子をみてみます。

各変数の意味は、
title : 表章項目
five : 生活環境項目5項目
year : 時間軸(年度)
pref : 都道府県
num : 事業場数
quantity : 排水量【千m3/日】
fuka : 負荷量【kg/日】
quality : 平均水質【mg/l】
です。
title から pref までが文字列のデータ、num から quality までが数値データです。
文字列データは度数を、数値データは平均値などを調べてみましょう。

title はすべて「汚濁負荷量」でした。なのでこの title は削除してもいいですね。

five は「BOD」「COD」「SS」「窒素含有量」「燐含有量」の5つの種類があって、どれも 235 の観測数があります。five はファクター型にしたほうがいいですね。
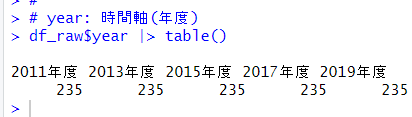
year は「2011年度」「2013年度」「2015年度」「2017年度」「2019年度」の5つの年度で、それぞれ 235 の観測数です。year もファクター型にしたほうがいいですね。
pref は都道府県です。各都道府県 25 の観測数です。これは、five が 5 種類で、year も 5 年なので、5 * 5 = 25 ということですね。
数値の変数は summary() 関数で様子をみましょう。
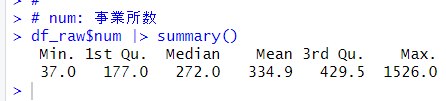
num は最小値は 37.0 で最大値は 1526 です。中央値は 272 で、平均値は 334.9 です。右の裾野が広い分布であることが推測されます。
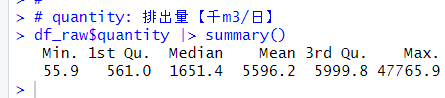
quantity は最小値は 55.9 で最大値は 47765.9 です。中央値は 1651.4 で、平均値は 5596.2 です。num よりもさらに右の裾野が広い分布であることが推測されます。
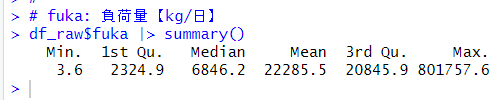
fuka は最小値は 3.6 で最大値は 801757.6 です。中央値は 6846.2 で、平均値は 22285.5 です。これも右の裾野が広い分布であると推測されます。

quality は最小値は 0.000 で最大値は 199.5 です。中央値は 4.2 で平均値は 6.125 です。これも右の裾野が広そうな分布ですね。
数値のデータは、num, quantity, fuka は 0 より大きい値なので、対数変換した変数も分析には有効かもです。quality は 0 の値があるので、平方根をとった値がいいかもです。
これらを踏まえて、分析用のデータフレームを作成します。

それでは、df を summary() 関数で処理してみます。

l_num から r_quality の変数の中央値と平均値を見ると、中央値と平均値の値が同じくらいの水準になっていることが確認できます。
次回は、
です。
今回は以上です。