
Bing Image Creator で生成: Closeup Asian Dayflower, flowering by small river which runs high mountains
の続きです。
前回は階層的クラスタリングを実行して、都道府県の3つのクラスターに分けました。
今回は、rpart パッケージを使って決定木モデルでこのクラスタリングを判別してみます。
まず、df_47のデータフレームにクラスター情報を追加して、都道府県の変数を削除して、yearをファクターにした新しいデータフレームを作成します。
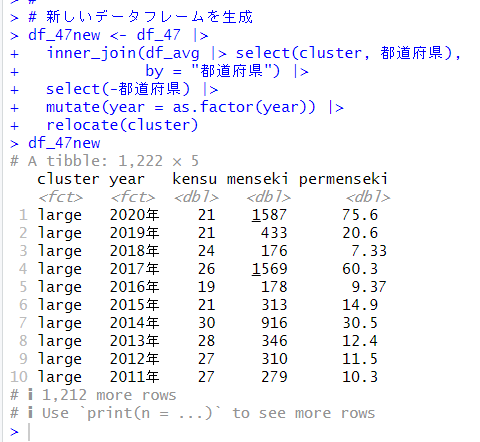
clusterを被説明変数にして、year, kensu, menseki, permenseki を説明変数にして決定木モデルを作成します。
rpartパッケージとrpart.plotパッケージを読み込みます。

はじめに剪定をしてない初期ツリーを生成します。

$cptable でクロスバリデーションの結果をみてみます。
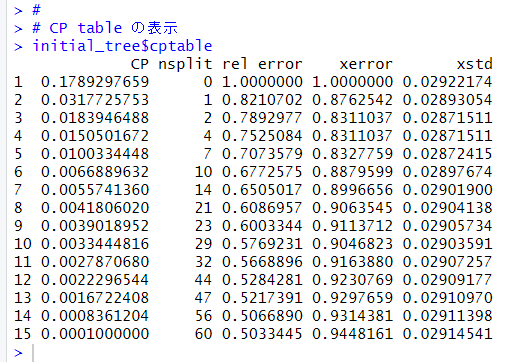
この表のxerrorの値が一番小さいCPが最適なCPです。

0.01839465が最適なCPでした。このCPでモデルを剪定します。

結果をグラフにしてみます。

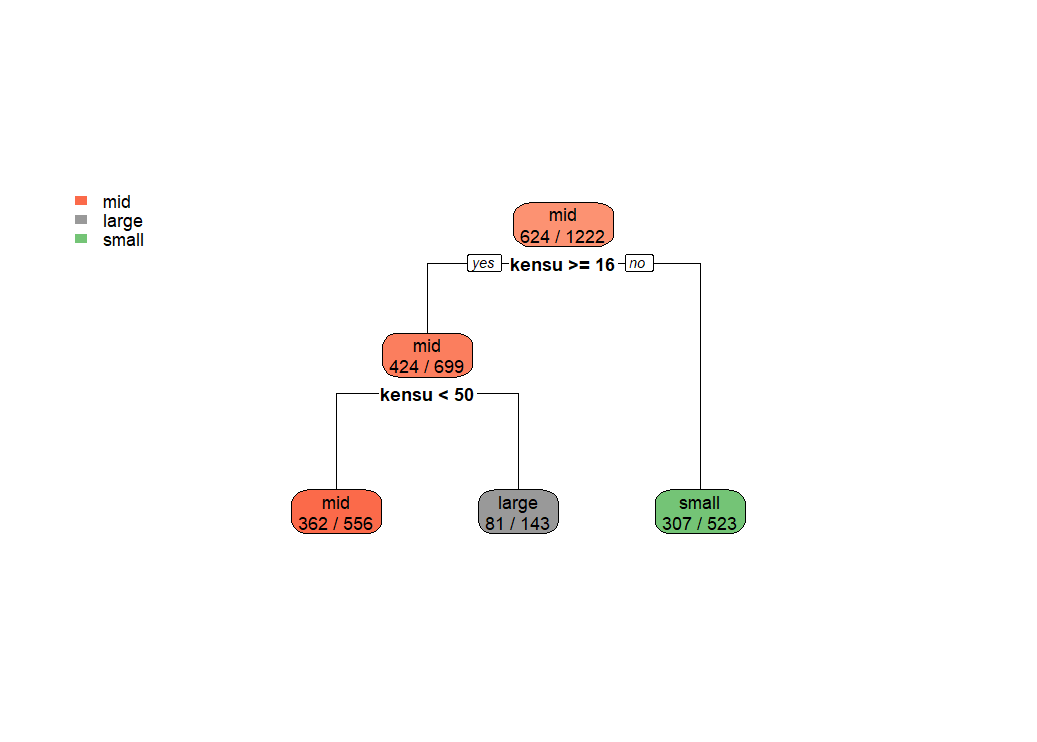
ずいぶんと単純な決定木ですね。
まず、kensu が16以下だとsmallになります。そして、kensuが50未満だとmid, それよりも多いとlargeです。
predict関数で予測します。

実際のclusterとの正解率をみてみましょう。

およそ7割の正解率でした。
これって、デタラメに予測したときと比べると、どのくらい良いのでしょうか?
ちょっと調べてみます。
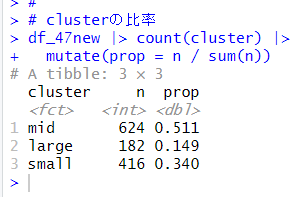
midが51.1%, largeが14.9%, smallが34%ですね。この割合でデタラメに予測してみます。
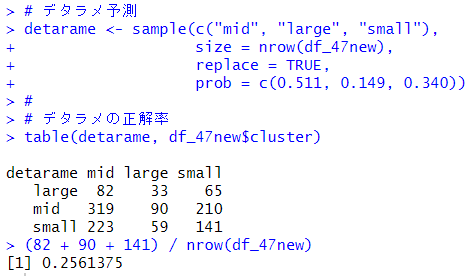
デタラメな予測だと、25.7%でした。
もう一回やってみましょう。

2回目は26.5%でした。
こんな感じでfor loopで1000回くらい繰り返してみましょう。

ヒストグラムにしてみます。

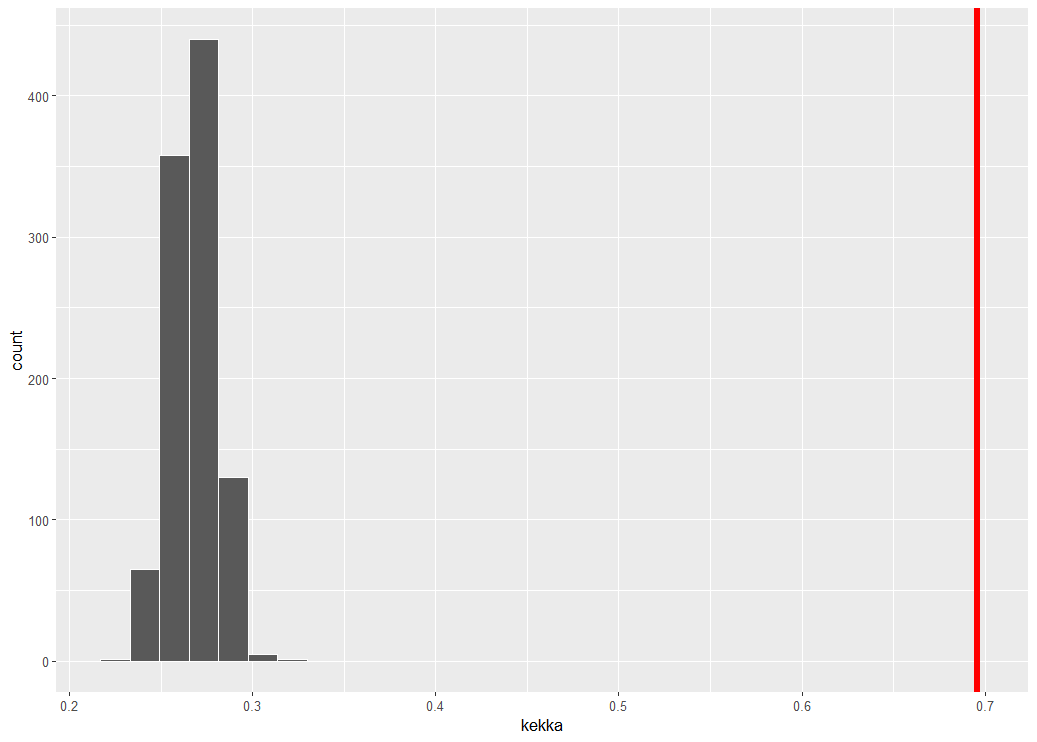
赤い垂線は、決定木モデルによる正解率です。デタラメ予測の正解率は、25%前後ですから、明らかに決定木モデルの予測のほうが優れていますね。
一応、デタラメ予測の平均値などを確認しておきます。
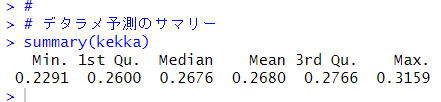
平均は26.8%でした。一番良くて31.59%でしたから、決定木モデルはデタラメ予測よりも2倍以上の精度で予測していることがわかります。
こんな感じは以上です。
次回は、
です。
初めから読むには、
です。