
(Bing Image Creator で生成: プロンプト: Close up photo of white and pink Hoya carnosa flowers, flowering on the higher mountains, background is blue sky and white clouds, photo)
の続きです。前回までデータの前処理は終わりました。今回からはいくつかの予測モデルを作って調べたいと思います。
前回の最後のサマリー関数の結果で、pdays と previous の平均値がともに 0.1826 でした。もしかした、両者は全く同じかもしれません。確認してみます。
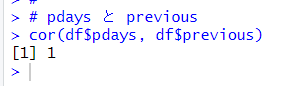
相関係数が 1 ですので previous を削除します。

df をトレーニング用とテスト用に分けます。トレーニング用のデータは 5000個にしました。

こうして作成した df_train と df_test が大きく違っていないかを確認するために、t検定の p値を算出する関数を作成します。

各変数の p値を格納する箱を作ります。
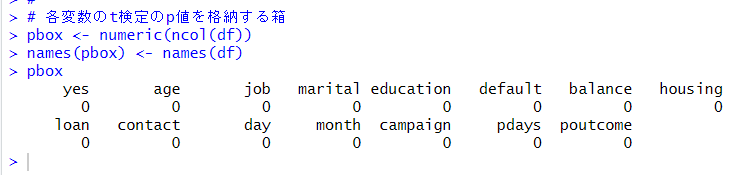
作成した ttest()関数を for loop を使って各変数について動かします。

結果をみてみます。

どの変数の p値も 0.05 以上なので、df_train と df_test は同じデータセットからのサンプルとみなしていいですね。念のため TRUE or FALSE でも確認します。

全部 TRUE, > 0.05 です。
それでは、第1のモデル、Linear Probability Model で予測してみます。単純な線形回帰モデルです。
はじめから数値型データなのは、age, balance, campaign です。この 3つは 2乗項もくわえみましょう。job, marital, education はカテゴリカル変数だったので、これらの交差項も加えましょう。
モデル式を定義します。

lm() 関数でモデルを推計します。

summary()関数で推定結果をみてみます。
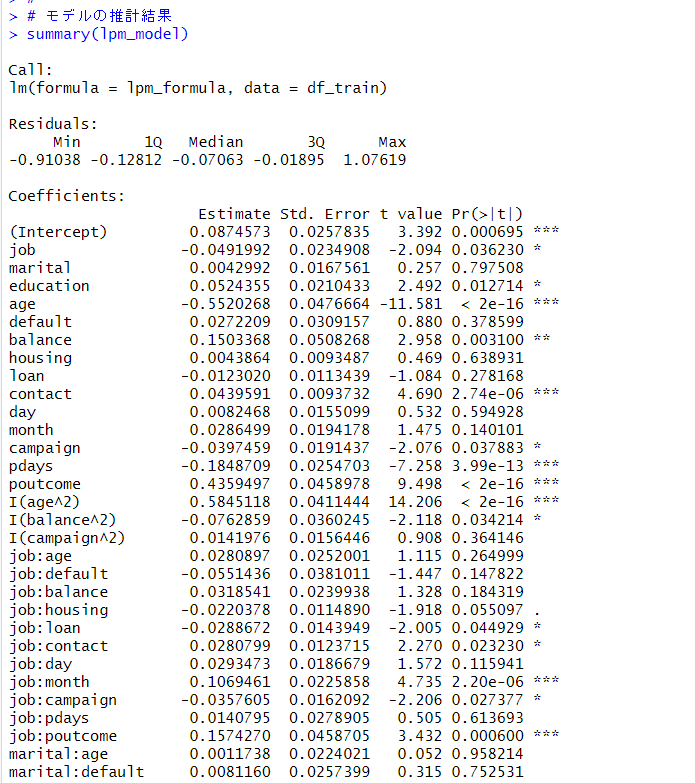
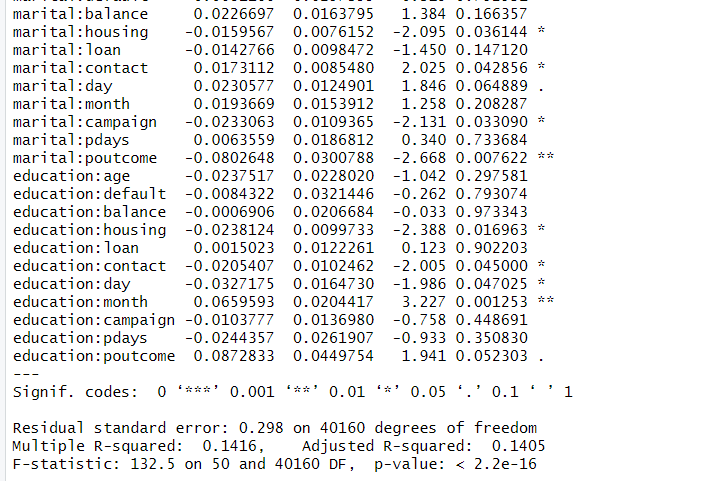
2乗項や交差項にも有意な係数がありますね。step()関数で不要な変数を削除します。
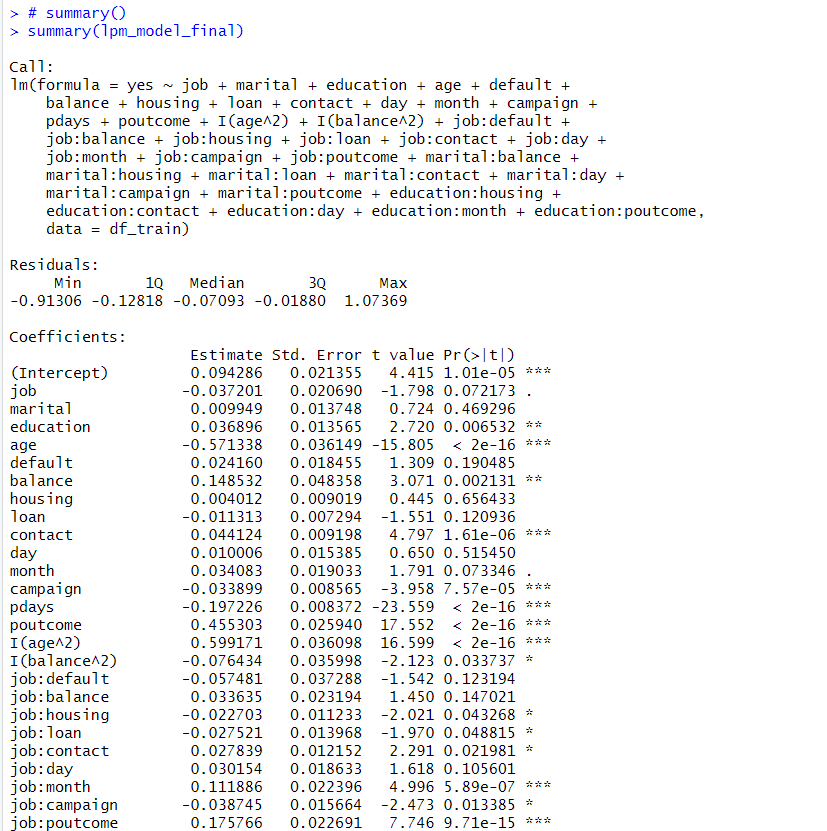
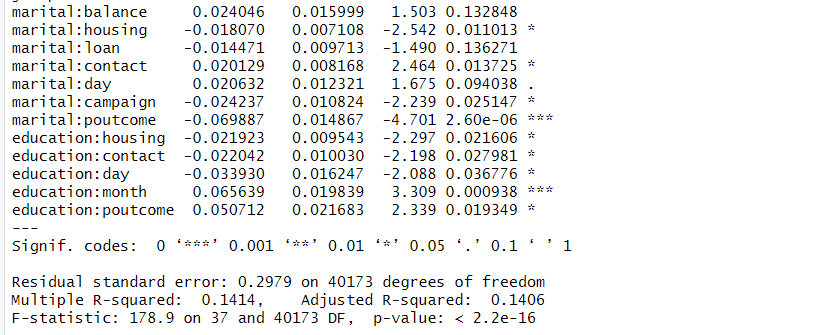
summary()関数で推定結果をみてみます。
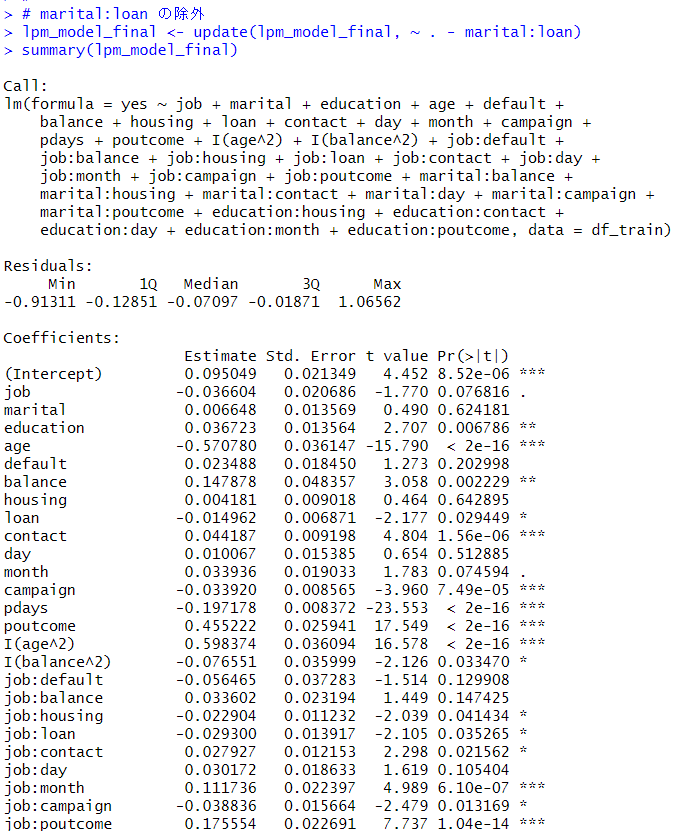
marital : loan は p値が 0.136 と 0.05 より大きいのでこれも削除します。
job : balance が p値が 0.147 と 0.05 よりも大きいので同じように削除します。このように一つ一つ p値が 0.05 より大きいのを削除していきます。
そして最終的に不要な変数を削除したモデルがこれです。
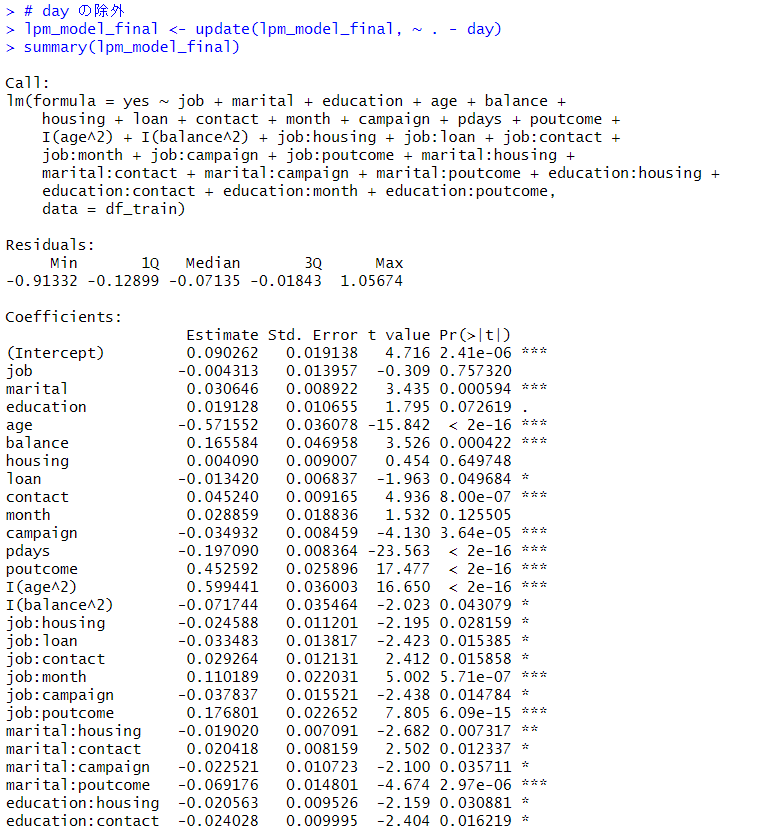

このモデルで予測します。

さあ、予測はどれくらい本当のデータを一致しているでしょうか?
caret パッケージの読み込んで、confusionMatrix()関数で評価します。


予測の一致率は、89.36% でした。Balance Accuraty 57.72% でした。次回以降の予測方法では、この 89.36%, 57.72% を超えることを目標にします。
今回は以上です。
次回は
です。
初めから読むには、
です。
今回のコードは以下になります。
#
# pdays と previous
cor(df$pdays, df$previous)
#
# previous を削除
df <- df |>
select(-previous)
#
# df をトレーニング用とテスト用に分ける
set.seed(12345)
index <- sample(1:nrow(df), 40211, replace = FALSE)
df_train <- df[index, ]
df_test <- df[-index, ]
#
# t検定のp値を返す関数を作成する
ttest <- function(x, y) {
test_result <- t.test(x, y)
pvalue <- test_result$p.value
return(pvalue)
}
#
# 各変数のt検定のp値を格納する箱
pbox <- numeric(ncol(df))
names(pbox) <- names(df)
pbox
#
# for loop で df_train と df_test の各変数のt検定のp値を計算
for (i in 1:ncol(df)) {
pbox[i] <- ttest(df_traini, df_testi)
}
# p値の値
pbox
#
# 5%水準
pbox > 0.05
#
# 第1の予測方法 Linear Probability モデル
# モデル式を定義
lpm_formula <- yes ~ (job + marital + education) * (age + default + balance +
housing + loan +
contact + day + month +
campaign + pdays +
poutcome) +
I(age^2) + I(balance^2) + I(campaign^2)
lpm_formula
#
# モデルを推計
lpm_model <- lm(lpm_formula, data = df_train)
#
# モデルの推計結果
summary(lpm_model)
#
# 不要な変数を除外
lpm_model_final <- step(lpm_model, trace = FALSE)
#
# summary()
summary(lpm_model_final)
#
# marital:loan の除外
lpm_model_final <- update(lpm_model_final, ~ . - marital:loan)
summary(lpm_model_final)
#
# job:balance の除外
lpm_model_final <- update(lpm_model_final, ~ . - job:balance)
summary(lpm_model_final)
#
# marital:day の除外
lpm_model_final <- update(lpm_model_final, ~ . - marital:day)
summary(lpm_model_final)
#
# job:default の除外
lpm_model_final <- update(lpm_model_final, ~ . - job:default)
summary(lpm_model_final)
#
# job:day の除外
lpm_model_final <- update(lpm_model_final, ~ . - job:day)
summary(lpm_model_final)
#
# education:day の除外
lpm_model_final <- update(lpm_model_final, ~ . - education:day)
summary(lpm_model_final)
#
# marital:balance の除外
lpm_model_final <- update(lpm_model_final, ~ . - marital:balance)
summary(lpm_model_final)
#
# default の除外
lpm_model_final <- update(lpm_model_final, ~ . - default)
summary(lpm_model_final)
#
# day の除外
lpm_model_final <- update(lpm_model_final, ~ . - day)
summary(lpm_model_final)
#
# lpm_model_final で予測
lpm_pred <- predict(lpm_model_final, df_test)
lpm_pred <- if_else(lpm_pred > 0.5, 1, 0)
#
# caret パッケージの読み込み
library(caret)
#
# lpm_pred の成績
confusionMatrix(factor(lpm_pred),
factor(df_test$yes))
#