
の続きです。前回は線形モデルをlmエンジンで推計しました。今回はglmnetエンジンでやってみます。
copilot先生に「tidymodels で linear_reg()でset_engine("glmnet")で最適なパラメータを見つける方法」と質問した回答を基にしてやってみましょう。
まず、モデルを定義します。
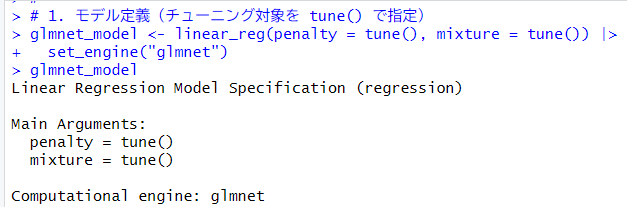
glmnetエンジンのパラメータは、penaltyとmixtureです。
次に、レシピを定義します。数値型の変数を標準化しましょう。
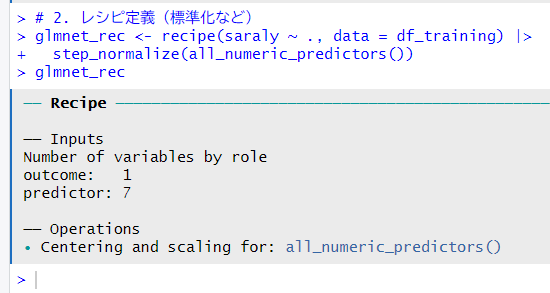
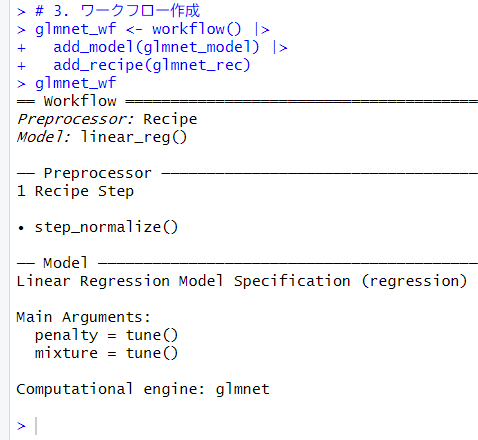
モデルとレシピを合わせてワークフローを定義します。
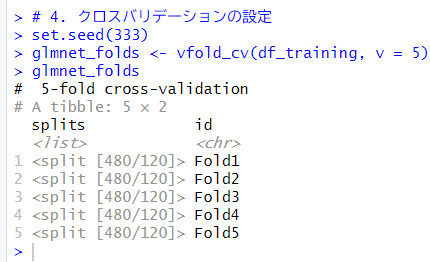
クロスバリデーションをの設定をします。vfold_cv()関数を使います。今回は5つのfoldsにしました。
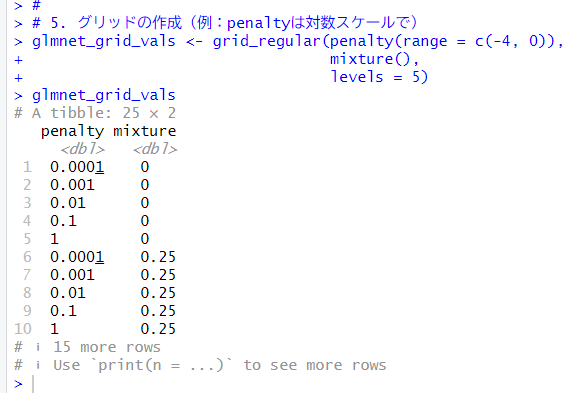
ハイパーパラメータのグリッドを設定します。
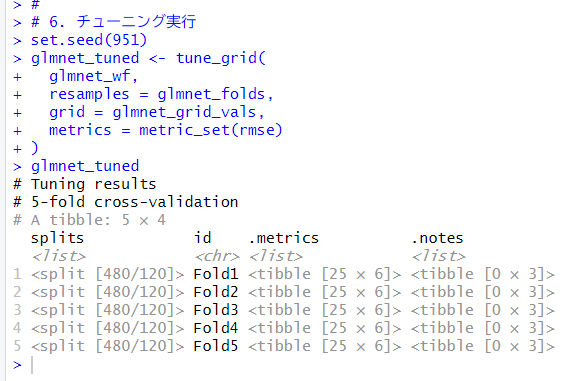
チューニングを実行します。tune_grid()関数を使います。
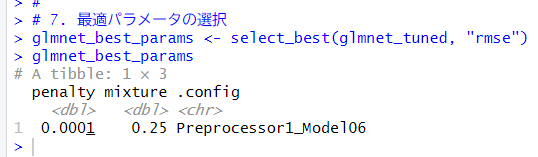
最適なパラメータを確認します。select_best()関数を使います。
最終モデルを推計します。finalize_workflow()関数で最適なパラメータを使ったワークフローを定義して、fit()関数でモデルを推計します。
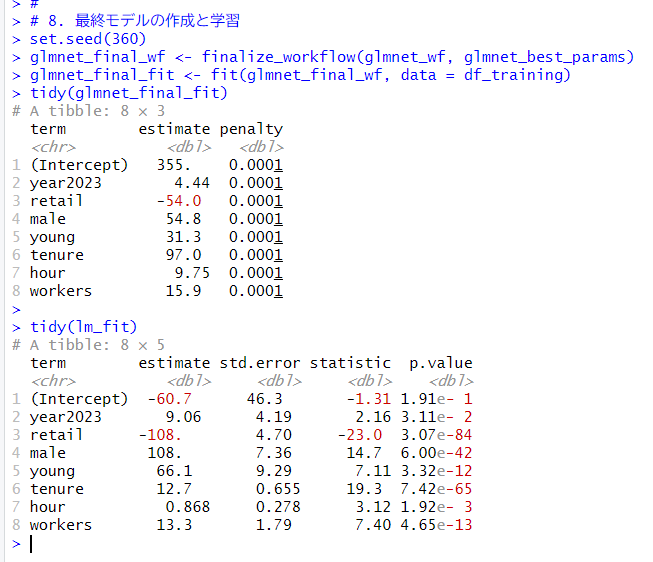
前回のlm_fitの結果と比べると、係数の正負は同じですが、値はけっこう違いますね。
predict()関数で、df_testのデータでsaralyを予測します。
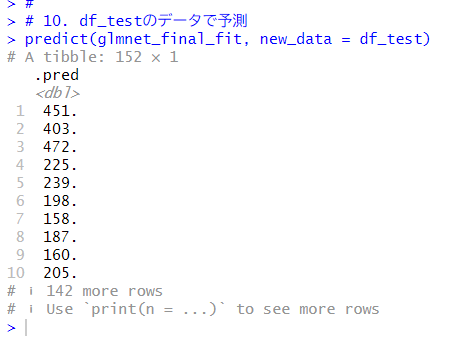
実際のsaralyと並べて表示してみます。
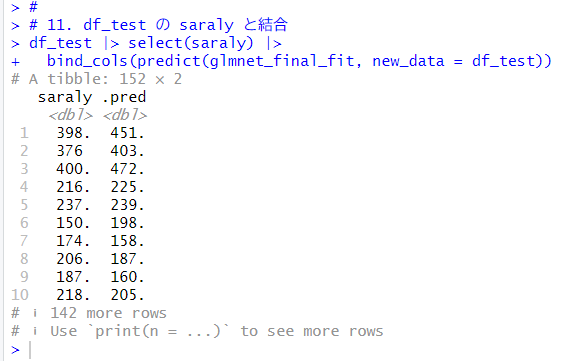
実際のsaralyと予測のsaralyの散布図グラフを描いてみます。

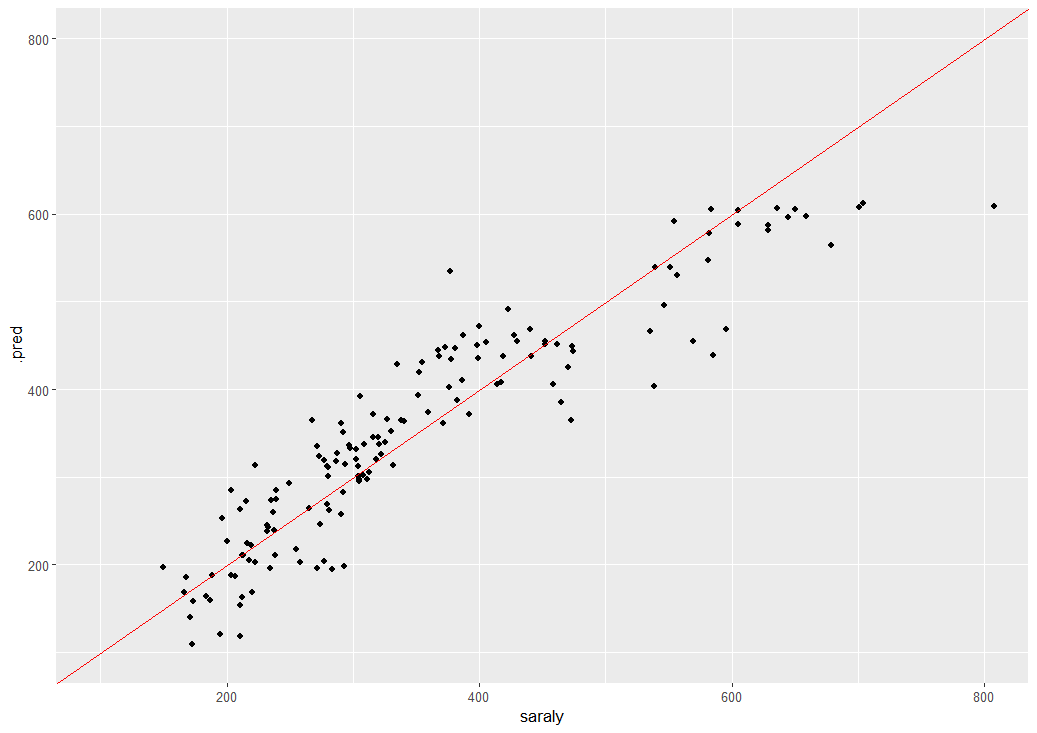
前回と同じで、saralyの値が大きいところは予測精度が高くないですね。これが線形モデルの限界なのかもしれません。
最後にRMSEを計算してみましょう。果たして、前回のlmエンジンのRMSEよりも小さい値になるでしょうか?
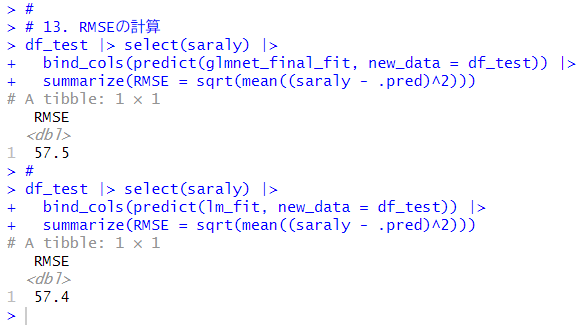
RMSEは57.5ですので、前回のlmエンジンでの57.4よりも悪い結果ですね。
今回は残念な結果になってしまいましたが、copilot先生に聞いて簡単に実行できました。
今回は以上です。
次回は、
です。
はじめから読むには、
です。
今回のコードは以下になります。
# 1. モデル定義(チューニング対象を tune() で指定)
glmnet_model <- linear_reg(penalty = tune(), mixture = tune()) |>
set_engine("glmnet")
glmnet_model
# 2. レシピ定義(標準化など)
glmnet_rec <- recipe(saraly ~ ., data = df_training) |>
step_normalize(all_numeric_predictors())
glmnet_rec
# 3. ワークフロー作成
glmnet_wf <- workflow() |>
add_model(glmnet_model) |>
add_recipe(glmnet_rec)
glmnet_wf
# 4. クロスバリデーションの設定
set.seed(333)
glmnet_folds <- vfold_cv(df_training, v = 5)
glmnet_folds
#
# 5. グリッドの作成(例:penaltyは対数スケールで)
glmnet_grid_vals <- grid_regular(penalty(range = c(-4, 0)),
mixture(),
levels = 5)
glmnet_grid_vals
#
# 6. チューニング実行
set.seed(951)
glmnet_tuned <- tune_grid(
glmnet_wf,
resamples = glmnet_folds,
grid = glmnet_grid_vals,
metrics = metric_set(rmse)
)
glmnet_tuned
#
# 7. 最適パラメータの選択
glmnet_best_params <- select_best(glmnet_tuned, "rmse")
glmnet_best_params
#
# 8. 最終モデルの作成と学習
set.seed(360)
glmnet_final_wf <- finalize_workflow(glmnet_wf, glmnet_best_params)
glmnet_final_fit <- fit(glmnet_final_wf, data = df_training)
tidy(glmnet_final_fit)
#
# 10. df_testのデータで予測
predict(glmnet_final_fit, new_data = df_test)
#
# 11. df_test の saraly と結合
df_test |> select(saraly) |>
bind_cols(predict(glmnet_final_fit, new_data = df_test))
#
# 12. グラフ
df_test |> select(saraly) |>
bind_cols(predict(glmnet_final_fit, new_data = df_test)) |>
ggplot(aes(x = saraly, y = .pred)) +
geom_point() +
geom_abline(intercept = 0, slope = 1, color = "red") +
coord_cartesian(xlim = c(100, 800), ylim = c(100, 800))
#
#
# 13. RMSEの計算
df_test |> select(saraly) |>
bind_cols(predict(glmnet_final_fit, new_data = df_test)) |>
summarize(RMSE = sqrt(mean*1 |>
summarize(RMSE = sqrt(mean((saraly - .pred)^2)))
#
(冒頭の画像は、Bing Image Creator で生成しました。プロンプトは、Photograph of landscape, great grass fields, 100% pure nature, clear blue sky です。
*1:saraly - .pred)^2)))
#
df_test |> select(saraly) |>
bind_cols(predict(lm_fit, new_data = df_test