
(Bing Image Creator で生成: Close up of yellow rapeseed flowers, background is rapeseed fields, photo)
の続きです。今回は R の rpart パッケージを使い、決定木モデルで分類してみます。
まずは、rpart, rpart.plot パッケージを読み込みます。

前回のロジスティクス回帰モデルでは、Fresh:Grocery, Grocery:Delicassen という2つの交差項が有効でしたので、データフレームにこれら2つの交差項を追加します。

では、rpart() 関数で決定木モデルを作成します。

rpart.plot() 関数でグラフにしてみます。

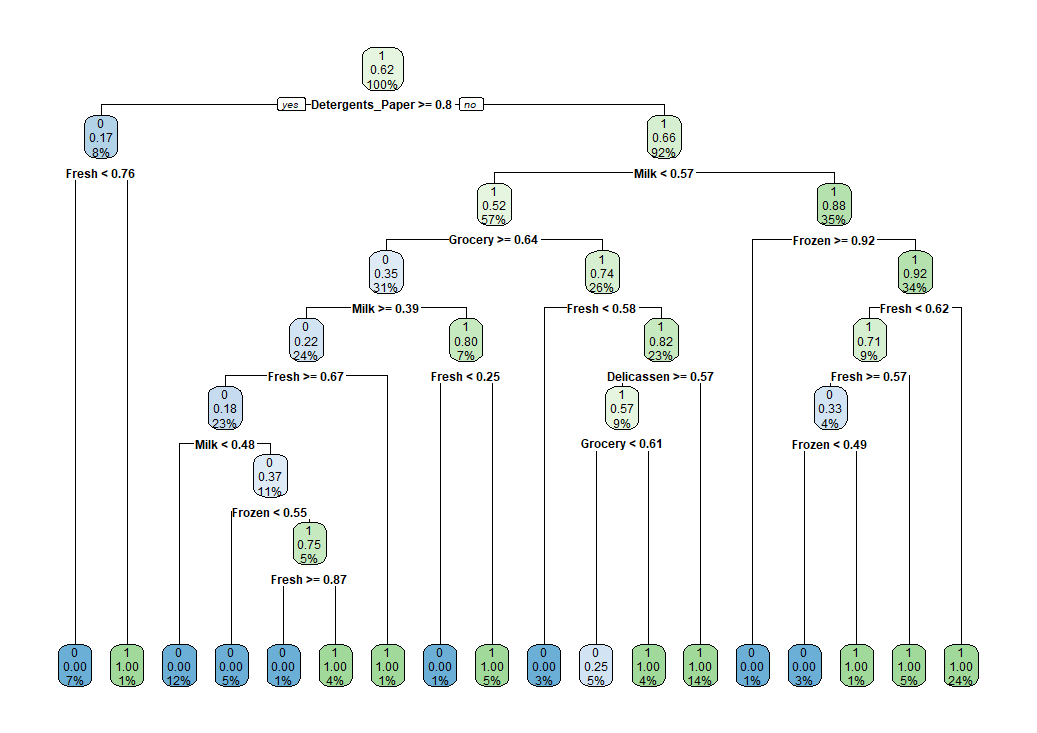
FG や GD は使われていないですね。。わざわざ追加しなくてもよかったですね。
plotcp() 関数でX軸が cp, Y軸が X-Val Relative Error のグラフを描いてみます。

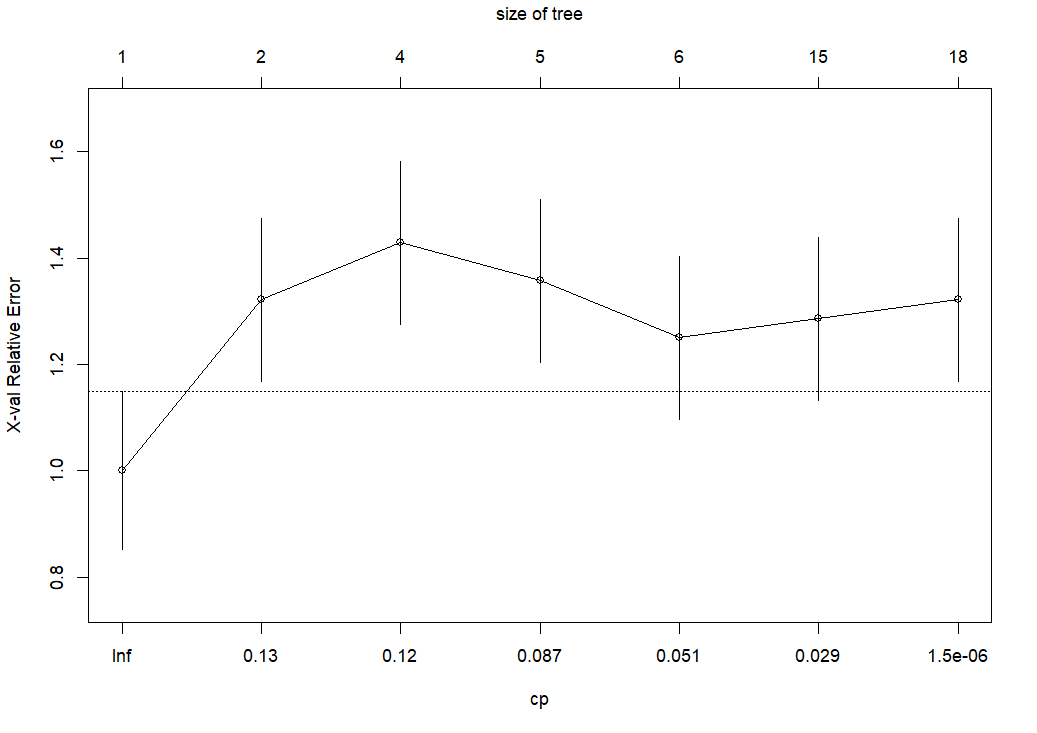
cp = Inf を除くと、cp = 0.051 が一番小さい X-Val Relative Error ですね。cp = 0.051 で決定木モデルを剪定します。

グラフを表示してみましょう。

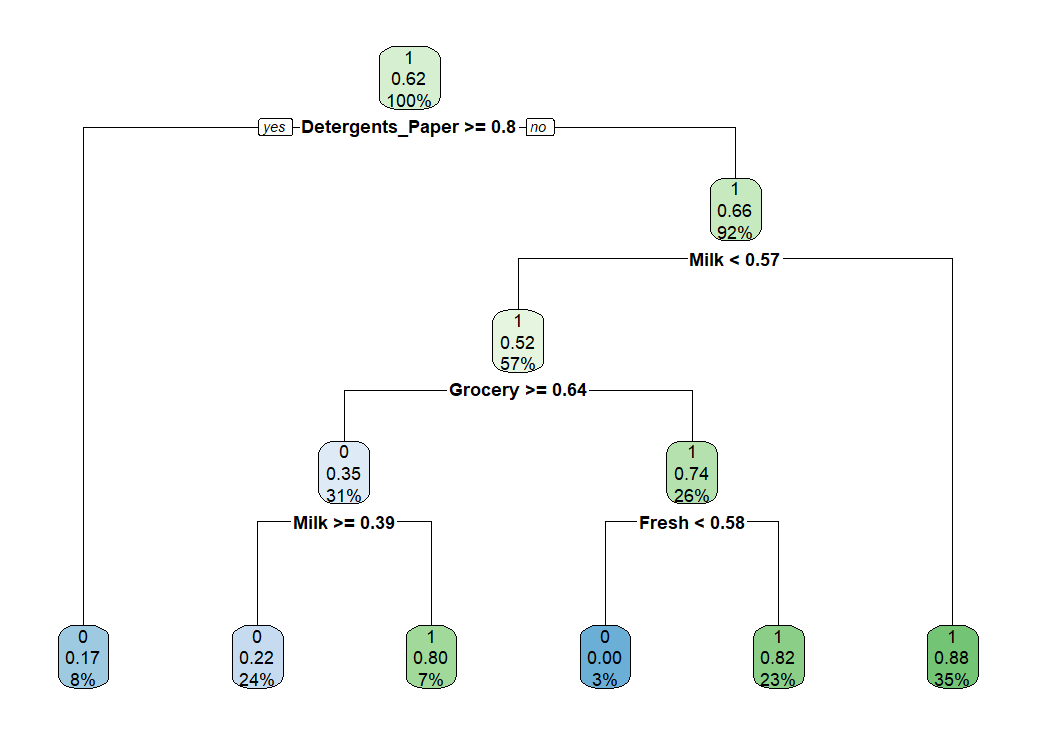
剪定前の決定木に比べるとだいぶスッキリした決定木になっています。
predict() 関数で予測していきましょう。はじめは、剪定前の決定木で予測してみます。

結果をみてみます。
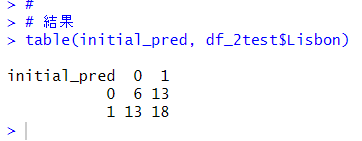
正解率は

48% でした。
剪定した決定木ではどうでしょうか?

正解率は 54% でした。
決定木モデルでも Lisbon Oporto の分類は難しいですね。
今回は以上です。
次回は
です。
初めから読むには、
です。
今回のコードは以下になります。
#
# rpart, rpart.plot を読み込む
library(rpart)
library(rpart.plot)
#
# Fresh:Grocery, Grocery:Delicassen を追加
df_2train <- df_2train |>
mutate(FG = Fresh * Grocery,
GD = Grocery * Delicassen)
df_2test <- df_2test |>
mutate(FG = Fresh * Grocery,
GD = Grocery * Delicassen)
#
# 剪定前のツリーを生成
set.seed(202)
initial_tree <- rpart(Lisbon ~ ., data = df_2train,
cp = 1e-10, minsplit = 3,
method = "class")
#
# ツリーを描く
rpart.plot(initial_tree)
#
# cpのグラフ
plotcp(initial_tree)
#
# cp = 0.051 で剪定
pruned_tree <- prune(initial_tree, cp = 0.051)
#
# 剪定された決定木のグラフ
rpart.plot(pruned_tree)
#
# initial_tree で予測
initial_pred <- predict(initial_tree, df_2test,
type = "class")
#
# 結果
table(initial_pred, df_2test$Lisbon)
#
# 正解率
(6 + 18) / nrow(df_2test)
#
# pruned_tree で予測
pruned_pred <- predict(pruned_tree, df_2test,
type = "class")
#
# 結果
table(pruned_pred, df_2test$Lisbon)
#
# 正解率
(13 + 14) / nrow(df_2test)
#