の続きです。
今回はR言語のglm関数でロジスティクス回帰分析をします。よく考えたら、整備率のデータは0%か100%と、取り得る値の範囲が決まっていますから、lm関数で単純な線形回帰よりもglm関数でロジスティクス回帰分析をしてほうが当てはまりがいいような気がしました。
やってみます。
まず、dg_hを%表示から小数点表示に変換しておきます。

glm関数でロジスティクス回帰分析をします。

summary関数で結果をみてみます。

pc_hは有意な変数のようです。
step関数でモデルを単純化します。
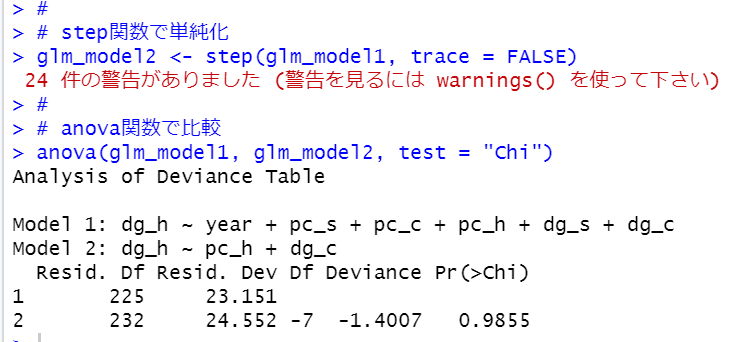
summary関数でglm_model2を見てみましょう。

残差プロットを描いてみます。


実際の値と予測値の散布図を描いてみます。


前回のall_model3と今回のglm_model2でどちらが当てはまりがいいのか、相関係数でみてみます。

今回のglm_model2のほうがわずかですが相関係数は高いです。
今回は以上です。
はじめから読むには、
です。