
Photo by Anton Maksimov juvnsky on Unsplash
の続きです。
今回は献血者率を他の変数で回帰分析してみましょう。
いままでの分析結果から、2006年と2011年では献血者率が違う、東日本と西日本では献血者率が違うなどがわかりました。
これら全部の変数を同時に考慮したときはどうなるでしょうか?
まずは、2006年なら1、2011年なら0となるダミー変数を作ります。

それではlm関数で回帰分析してみます。

summary関数で結果を見てみます。
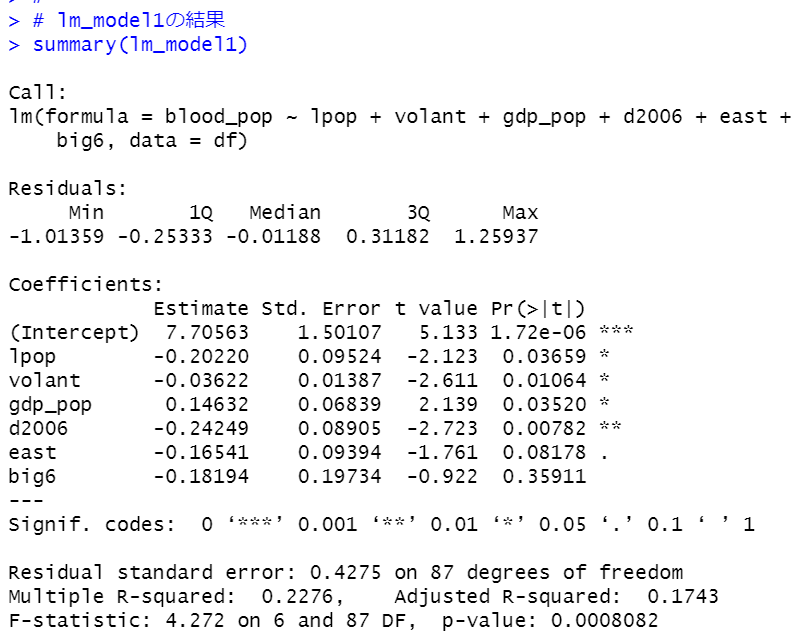
p-valueは0.0008082と0.05よりも低いので、全体として有意な統計モデルです。
eastの変数が10%水準、lpop, volant, gdp_pop, 変数が5%水準、d2006が1%水準で有意です。
人口が1%増えると0.002ポイント献血者率が減少します。
ボランティア活動行動者率が1ポイント増えると、0.03622ポイント献血者率が減少します。
gdp_popが1(百万円)増えると、0.14632ポイント献血者率が増加します。
2006年のほうが0.24249ポイント献血者率が低いです。
東日本のほうが0.16541ポイント献血者率が低いです。
続いて、誤差項が均一分散かどうかをチェックします。
まず、誤差項の2乗を計算して、それを説明変数で回帰分析します。
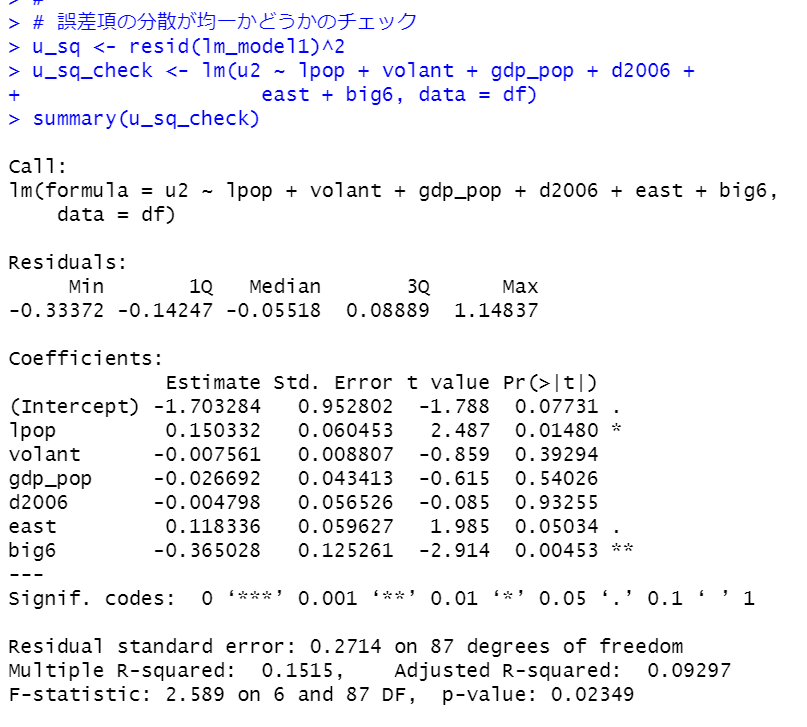
p-valueが0.02349ということで0.05よりも低いです。誤差項が均一分散(homoscedasticity)で無いということは、さきほどの結果のStd. Errorなどは正しくない、ということですね。
Using R for Introductry Econometrics

を参考にしてheteroscedasticity-robust inferenceを算出します。
lmtestとcarというパッケージを読み込みます。

coeftest()関数で通常のStd. ErrorとHeteroscedasticity-robust Std. Errorを算出できます。
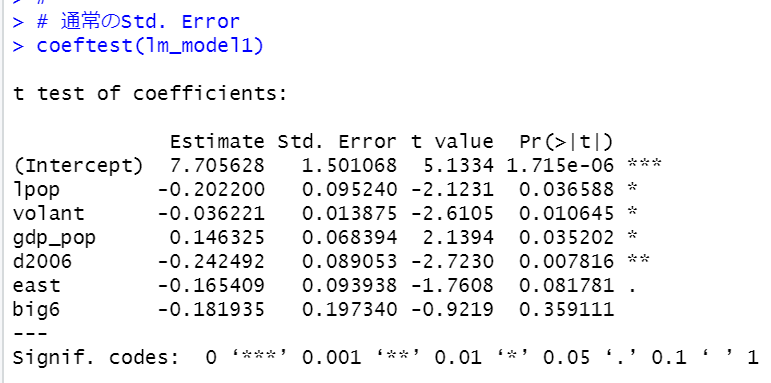
これは、すでにsummary()関数で表示したのを同じです。
heteroscedasticity-robust Std. Errorはvcov = hccmというオプションを加えます。

lpop, eastは有意な変数ではなくなりました。
volantが5%水準で有意で、対数変換した人口、人口当たりの県内総生産額、2006年か2011年か、東日本か、西日本か、big6か非big6かが同じなら、ボランティア行動者率が1ポイント上昇すると、献血者率は0.036221ポイント低下する、という結果です。
なんか不思議な結果ですね。
gdp_popが10%水準で有意です。他の条件が同じなら、1百万円だけ人口当たりの県内総生産額が上昇すると献血者率が0.146325ポイント上昇します。豊かになれば献血をする余裕もできるということでしょうか?
他の条件が同じならば、2006年のほうが2011年よりも献血者率が0.242492ポイント低いということです。2011年の人のほうが献血への意識が高いということですかね。
今回は以上です。
次回は
です。
はじめから読むには
です。