
Photo by dilara harmanci on Unsplash
の続きです。
今回は、回帰分析の説明変数に2006年の献血者率を加えて、2011年の献血者率を回帰分析してみようと思います。

blood_popをblood_pop_2016と名前を変更しておきましょう。

続いて、2011年だけのデータフレームを作ります。
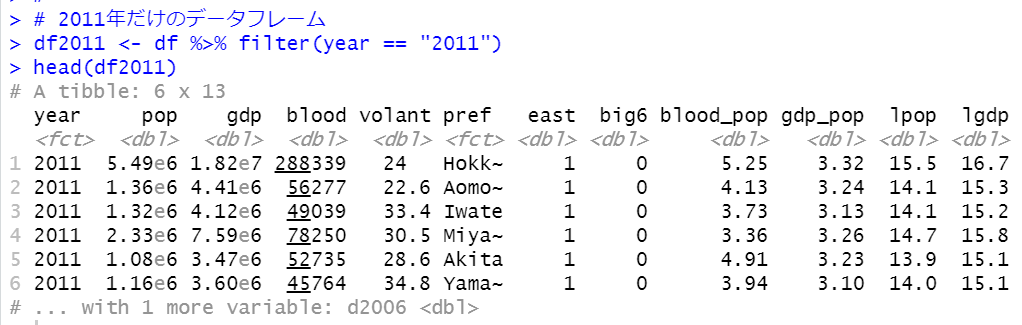
このdf2006とdf2011をinner_join()関数で結合します。
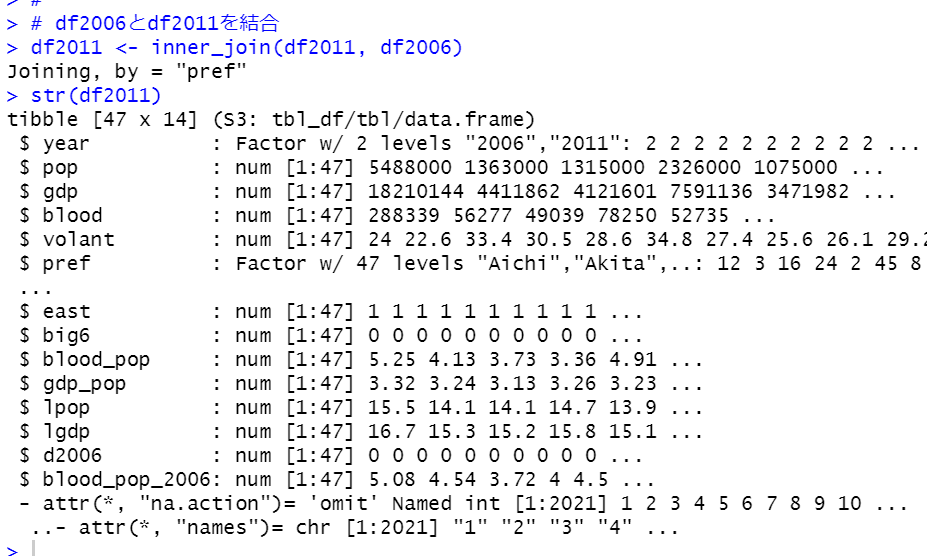
by = "pref" となっていますので、prefを基準にして結合したとわかります。
それでは、lm()関数で回帰分析をしてみます。

p-valueは2.506e-07と0.05よりも小さな値ですので、有意なモデルです。
このモデルでもvolant: ボランティア行動者率は有意な変数で、-0.03466と符号がマイナスです。
誤差項がheteroscedasticity(不均一分散)なのかどうかを検定してみます。

p-valueが0.4323と0.05よりも大きいので、誤差項はheteroscedasticity(不均一分散)とは言えないですね。
つまり、lm_model2は正しいモデルと言えます。
もういちど、coeftest関数でlm_model2の変数の係数をみてみます。
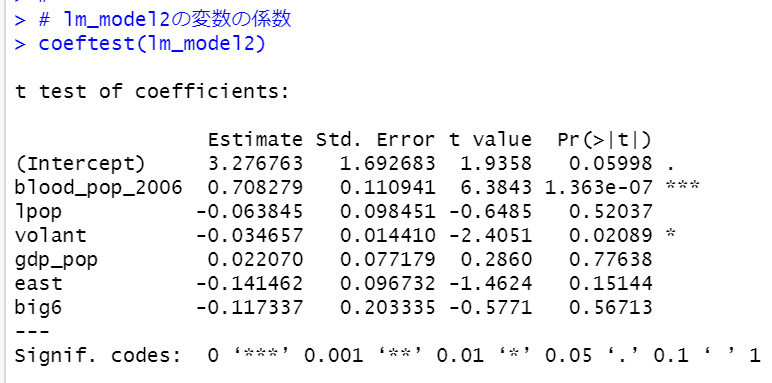
volant: ボランティア行動者率が10ポイント上昇すると、献血者率は0.3ポイント下がる、ということですね。
volantの平均値、献血者率の平均値を再確認します。
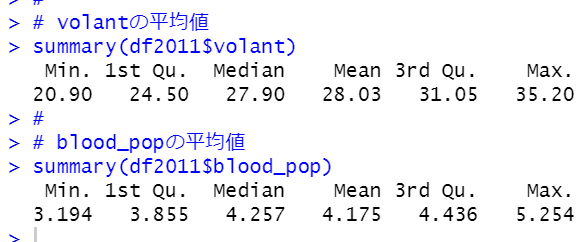
volantの平均値は28.03パーセント、献血者率の平均値は4.175%です。
今回は以上です。
はじめから読むには
です。