
(Bing Image Creator で生成: プロンプト: Closeup of Setaria viridis flowers, background is vast green field and long river, blue sky, photo)
の続きです。前回の分析で交通量が減っているように見えました。そこで今回は本当に減っているか、確認します。
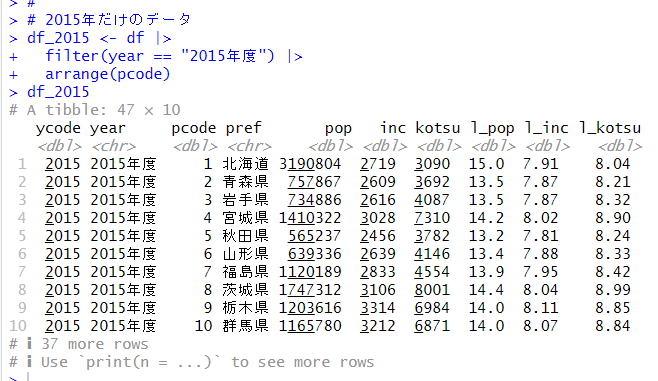
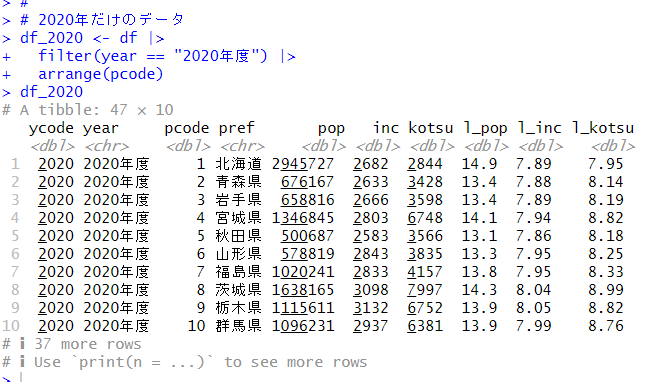
まず、2015年度だけのデータフレーム、2020年度だけのデータフレームを作成します。
そして、変化幅、変化率を計算したデータフレームを作成します。
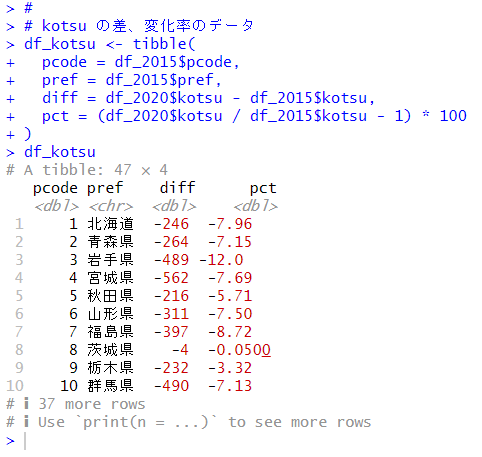
北海道は246台、7.96%も減ったということですね。
summary()関数をつかってdiff: 変化幅, pct: 変化率の平均値をみてみましょう。

平均値、中央値、第3分位値すべてマイナスですから、交通量が減っているのは間違いないようですね。
ヒストグラムを描いて分布を確認します。diff: 変化幅からです。

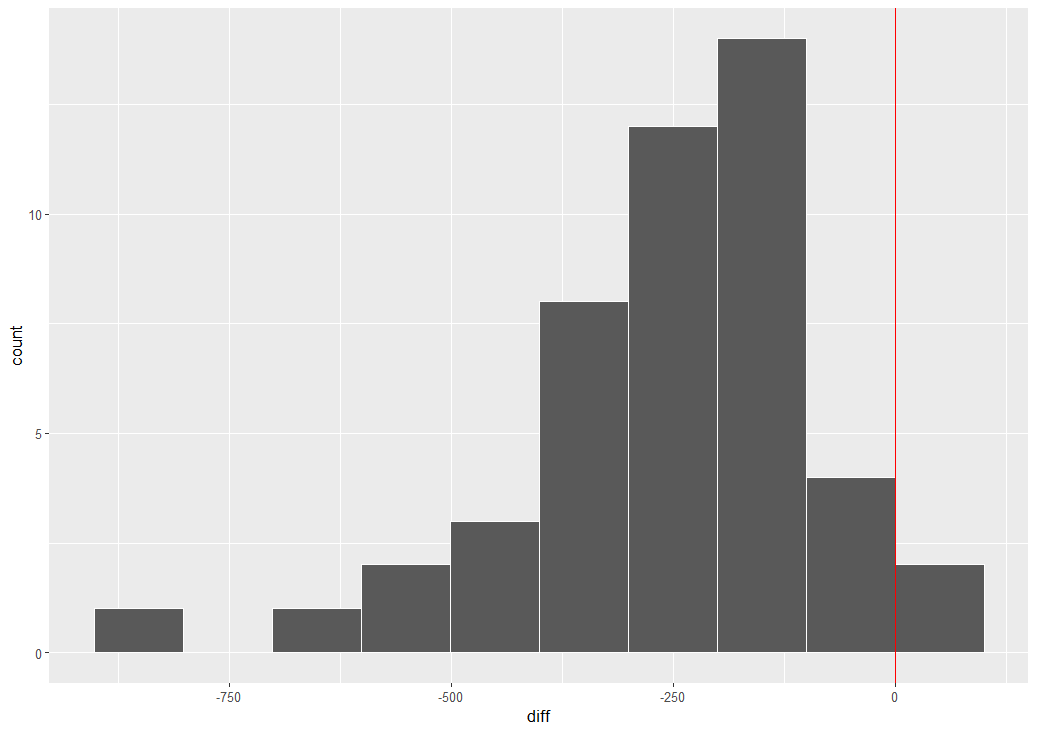
boundary = 0 にして、0をヒストグラムの境界線にして、geom_vline()で0の位置に赤い垂線を描きました。大半の都道府県がマイナスですね。
pct: 変化率も同じようにして変化率を描きます。

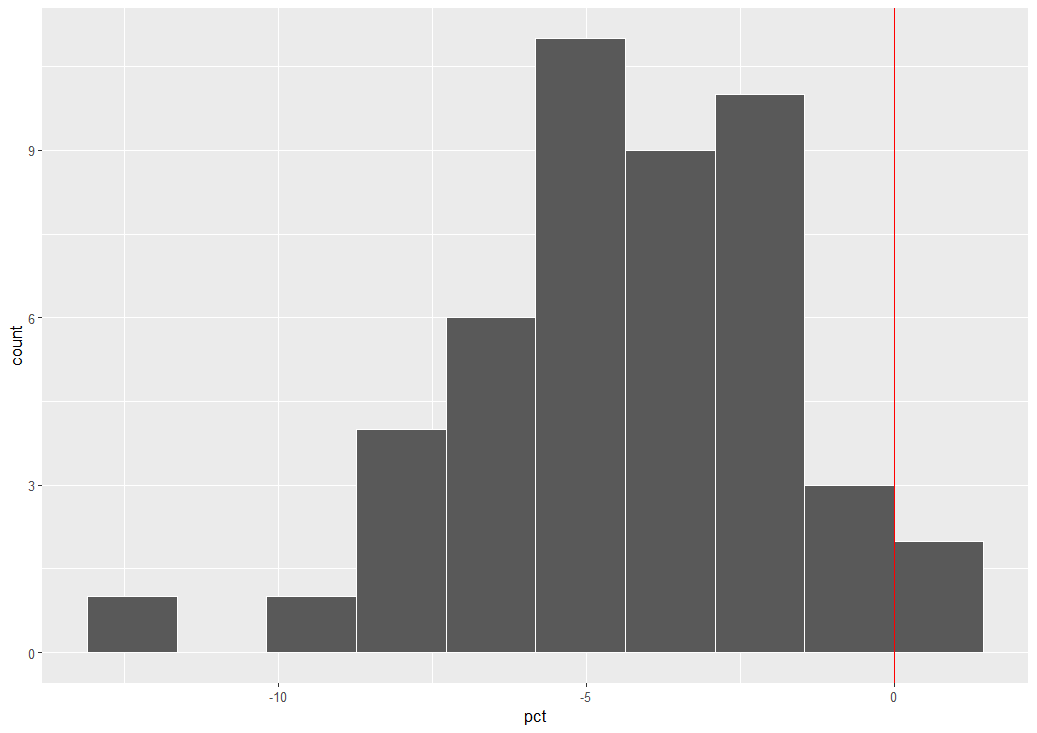
pct: 変化率も同じような分布ですね。
交通量が増えているところもあるようですので、それがどこなのか、確認します。

和歌山県と埼玉県は交通量が増えたのですね。
その反対に、交通量が大きく減ったところはどこでしょうか?
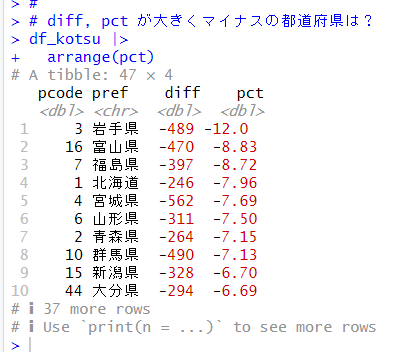
岩手県や富山県が大きく減っていることがわかります。
次に、pctの平均値がほんとうにマイナスかどうか、統計的検定をします。
t.test()関数で実行すると、瞬間的にわかります。
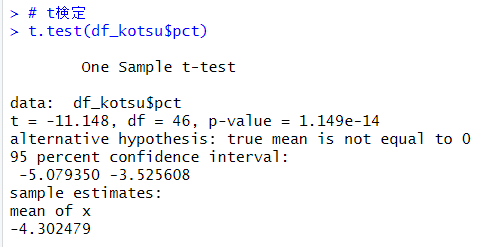
p-valueが1.149e-14とほぼ0です。95%信頼区間は-5.079 ~ -3.525 と0を含んでいませんからpctの平均値はマイナスであることは間違いないですね。
inferパッケージで、シミュレーションベースでも検定してみます。
https://infer.netlify.app/articles/t_test
こちらのサイトを参考にしています。

まず最初に平均値を計算します。
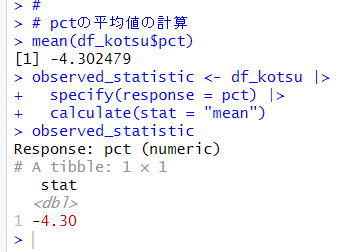
そうしたら、ブートストラップ法で何回も平均値を計算します。

1000個の平均値が生成されました。これをvisualize()関数でヒストグラムにします。

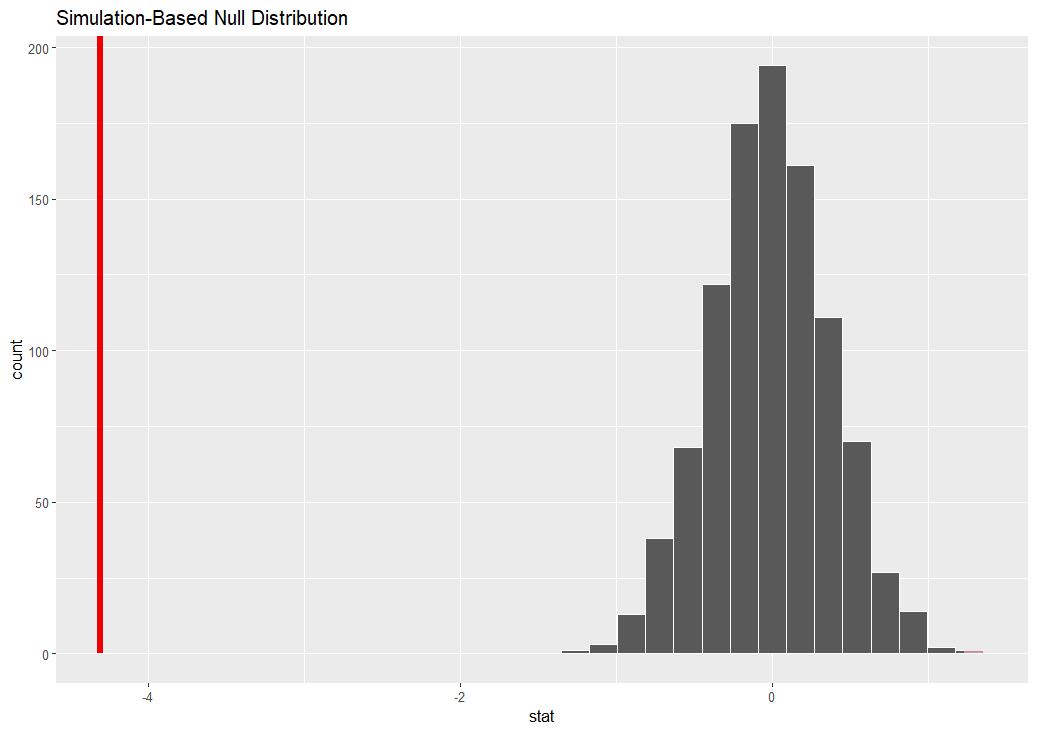
赤い垂線が実際の平均値です。ブートストラップ法で生成した平均値とは大きく離れています。
get_p_value()関数でp値を算出します。

p値は0です。
inferパッケージには、t_test()関数というものがあって、これで、t.test()関数と同じことができます。

今回は以上です。
次回は
です。
初めから読むには、
です。
今回のコードは以下になります。
#
# 2015年だけのデータ
df_2015 <- df |>
filter(year == "2015年度") |>
arrange(pcode)
df_2015
#
# 2020年だけのデータ
df_2020 <- df |>
filter(year == "2020年度") |>
arrange(pcode)
df_2020
#
# kotsu の差、変化率のデータ
df_kotsu <- tibble(
pcode = df_2015$pcode,
pref = df_2015$pref,
diff = df_2020$kotsu - df_2015$kotsu,
pct = (df_2020$kotsu / df_2015$kotsu - 1) * 100
)
df_kotsu
#
# df_kotsu のサマリー
summary(df_kotsu)
#
# diff のヒストグラム
df_kotsu |>
ggplot(aes(x = diff)) +
geom_histogram(color = "white", bins = 10,
boundary = 0) +
geom_vline(xintercept = 0, color = "red")
#
# pct のヒストグラム
df_kotsu |>
ggplot(aes(x = pct)) +
geom_histogram(color = "white", bins = 10,
boundary = 0) +
geom_vline(xintercept = 0, color = "red")
#
# diff, pct がプラスの都道府県別は?
df_kotsu |>
arrange(desc(pct))
#
# diff, pct が大きくマイナスの都道府県は?
df_kotsu |>
arrange(pct)
#
# t検定
t.test(df_kotsu$pct)
#
# inferパッケージの読み込み
library(infer)
#
# pctの平均値の計算
mean(df_kotsu$pct)
observed_statistic <- df_kotsu |>
specify(response = pct) |>
calculate(stat = "mean")
observed_statistic
#
# null distributionの生成
set.seed(1)
null_dist_1_sample <- df_kotsu |>
specify(response = pct) |>
hypothesize(null = "point", mu = 0) |>
generate(reps = 1000, type = "bootstrap") |>
calculate(stat = "mean")
#
# null distributionのヒストグラム
null_dist_1_sample |>
visualize() +
shade_p_value(observed_statistic,
direction = "two-sided")
#
# p値の算出
p_value_1_sample <- null_dist_1_sample |>
get_p_value(obs_stat = observed_statistic,
direction = "two-sided")
p_value_1_sample
#
# t_test()関数
t_test(df_kotsu, response = pct, mu = 0)
#